
Na pozycję strony w wynikach Google wpływa mnóstwo przeróżnych czynników. Żaden z nich nie ma jednak większego znaczenia bez indeksacji, za którą odpowiedzialne są algorytmy. Proces ten nie musi (a nawet nie powinien) być pozostawiony przypadkowi. Można na niego wpływać, a najważniejszym, służącym do tego narzędziem jest właśnie robots.txt. Z tej lekcji Akademii SEO dowiesz się, czym jest i do czego służy plik robots.txt. Poznasz też jego budowę i nauczysz się, jak stworzyć go samodzielnie.
Spis treści:
- Czym jest plik robots.txt?
- Do czego służy plik robots.txt?
- Czy plik robots.txt jest ważny?
- Co zawiera plik robots.txt?
- Jak stworzyć robots.txt?
- Składnia robots.txt – ważne kwestie przy tworzeniu pliku
- Przykładowe reguły w robots.txt
- Korzystanie z robots.txt – o tym musisz pamiętać!
- Podsumowanie
Czym jest plik robots.txt?
Robots.txt to niewielki i stosunkowo prosty plik tekstowy, umieszczany w głównym katalogu strony internetowej, mający bardzo duży wpływ na pozycjonowanie. To jeden z głównych mechanizmów "Robots Exclusion Protocol", mających na celu informowanie robotów internetowych o tym, czego nie powinny robić na danej stronie. Mówiąc inaczej, plik robots to zestaw reguł, do których stosują się odwiedzające stronę algorytmy.
Do czego służy plik robots.txt?
Z pliku robots.txt roboty odwiedzające witrynę "dowiadują się", czy mogą uzyskać dostęp do konkretnych podstron i plików. To właśnie w nim możesz podać adresy i elementy swojej witryny, które chcesz wyłączyć z indeksowania. Dzięki robots.txt możesz więc wpływać na to, jak Twoja strona będzie odebrana przez wyszukiwarkę. Możesz więc też wpływać na jej pozycję.
Plik robots.txt jest pierwszym elementem sprawdzanym na stronie internetowej przez roboty Google. To z niego odczytują one zasady, według których mogą indeksować stronę. Na jego podstawie określają też, które elementy strony mogą analizować pod kątem ich struktury i treści. O tym, dlaczego niektórych podstron nie powinno się indeksować, wiesz już z jednej z poprzednich lekcji.
Czy plik robots.txt jest ważny?
Plik robots.txt jest istotny, gdy z jakiegoś powodu chcesz ograniczyć robotom możliwość indeksowania niektórych podstron. Stworzenie go daje możliwość zablokowania indeksowania informacji nieistotnych z punktu widzenia szukających. Pozwala zapobiec też indeksowaniu podstron i elementów mogących negatywnie wpływać na pozycję witryny w Google.
Plik robots jest też szczególnie przydatny na bardzo rozbudowanych stronach, zawierających dużo dynamicznej treści. Indeksowanie ich w całości zajęłoby wiele miesięcy, a widoczność wszystkich podstron w wyszukiwarce wcale nie jest przecież potrzebna. W takim wypadku ograniczenie zakresu indeksacji pozwala przyśpieszyć cały proces. Dzięki niemu roboty skanują tylko podstrony istotne dla SEO, a to przekłada się na lepsze i szybsze wyniki.
Umieszczenie pliku robots.txt na serwerze zaleca się jednak zawsze, nawet wtedy, gdy strona ma być indeksowana w całości. Dzięki temu można uniknąć ewentualnych błędów, które mogłyby uniemożliwić zaindeksowanie istotnych podstron lub elementów.
Czego oczy nie widzą,
Tego Google nie czyta.

Co zawiera plik robots.txt?
Plik robots.txt nie jest skomplikowany, a w jego skład wchodzi zaledwie kilka elementów. Są to kolejno dyrektywy zezwalające i blokujące oraz oznaczenia robotów, których dotyczą. To właściwie wszystko, jedynym dodatkowym elementem może być wskazanie robotom lokalizacji mapy witryny.
Dyrektywy Allow i Disallow – instrukcje dla robota
Dyrektywy Allow i Disallow mówią robotom, które adresy URL mogą odwiedzać i skanować. Każdy z robotów ma domyślnie pozwolenie na dostęp do wszystkich podstron. Zablokowanie dostępu następuje poprzez użycie dyrektywy Disallow. Za pomocą Allow można z kolei zezwolić na skanowanie konkretnego adresu. Ze względu na domyślny dostęp nie trzeba jej używać dla każdego adresu, można użyć jej jednak do tworzenia wyjątków.
Załóżmy, że chcesz zablokować dostęp do katalogu /example/. W tym celu w pliku robots.txt dodajesz dyrektywę Disallow, która wygląda tak:
User-agent: *
Disallow: /example/
Te dwie linijki blokują robotom dostęp do wszystkich adresów URL, które zaczynają się od /example/. Dzięki nim adresy te nie będą indeksowane. Idąc dalej, załóżmy, że w tym katalogu znajduje się jednak plik istotny pod względem SEO, na którego indeksacji Ci zależy. Używasz więc dyrektywy Allow, tworząc tym samym wyjątek:
User-agent: *
Disallow: /example/
Allow: /example/exception.php
Dzięki niemu, pomimo zakazania dostępu do katalogu /example/ roboty będą mogły skanować plik exception. Będzie on stanowił wyjątek.
User-agent – różne instrukcje dla różnych robotów
Za skanowanie poszczególnych elementów na stronie odpowiadają różne roboty. To dlatego w pliku robots można zawrzeć dla nich osobne instrukcje. Każde połączenie z Twoją stroną jest realizowane za pośrednictwem jakiegoś programu. Każdy taki program (najczęściej przeglądarka internetowa) ma z kolei swoje systemowe oznaczenie. Oznaczeniem tym jest właśnie User-agent.
Wszystkie roboty, podobnie jak przeglądarki internetowe, mają swoje unikalne oznaczenia. Dzięki nim można je identyfikować i tworzyć dla nich osobne reguły. Poniżej przedstawiamy kilka robotów wraz z ich oznaczeniem.
- Googlebot (User-agent: Googlebot) – robot indeksujący strony wyświetlane na komputerach i urządzeniach mobilnych,
- Googlebot Image (User-agent Googlebot-Image) – robot indeksujący obrazki i grafiki,
- Googlebot Video (User-agent Googlebot-Video) – robot indeksujący wideo,
- AdsBot (User-agent: AdsBot-Google) – robot odpowiedzialny za sprawdzenie jakości reklam na stronie wyświetlanej na komputerze,
- AdsBot Mobile Web (User-agent: AdsBot-Google-Mobile) – robot sprawdzający jakość reklam na stronie wyświetlanej w systemie iOS.
Załóżmy, że z jakiegoś powodu chcesz, by do Twojej strony nie miał dostępu Googlebot Image. W takiej sytuacji użyjesz reguły:
User-agent: *
Allow: /
User-agent: Googlebot-Image
Disallow: /
Dzięki niej do całej strony będą mieć dostęp wszystkie roboty, z wyłączeniem Googlebota odpowiedzialnego za indeksację obrazów. Takie wyjątki dotyczące konkretnego robota można też oczywiście tworzyć dla poszczególnych adresów i plików.
Co ważne, nie każdy z robotów bierze pod uwagę plik robots. Przykładowo, Feedfetcher, czyli bot mający za zadanie pobierać wiadomości ze stron w celu wyświetlania ich w aplikacjach mobilnych (np. Wiadomości Google) nie respektuje pliku robots.txt.
Pełna lista robotów indeksujących wraz z ich oznaczeniami i informacjami o respektowaniu reguł jest dostępna na stronie link.
Dodatkowa funkcja robots.txt – wskazanie mapy witryny
Oprócz zamieszczania dyrektyw plik robots pozwala na wskazanie algorytmom lokalizacji mapy witryny. Dzięki temu roboty będą mieć dostęp do wszystkich adresów URL, a cały proces indeksacji przebiegnie szybciej. Możesz to zrobić dodając w robots.txt linijkę wyglądającą w ten sposób:
Sitemap: https://example.com/folder/sitemap.xml
Jak stworzyć robots.txt?
W zależności od potrzeb plik robots możesz stworzyć na różne sposoby. Możesz napisać go ręcznie lub wygenerować z pomocą zewnętrznego narzędzia. Możesz też stworzyć plik dynamiczny, za pomocą swojej strony. Żaden z tych sposobów nie jest skomplikowany.
Ręczne tworzenie robots.txt
Najprostszy i najpopularniejszy sposób. Polega na utworzeniu zwykłego pliku o rozszerzeniu txt i wypisaniu wszystkich reguł oraz user-agent’ów ręcznie. Metoda ta wymaga znajomości działania pliku i jego składni. W przypadku niewielkich stron jest jednak w zupełności wystarczająca.
Tworzenie pliku robots z pomocą generatora
Plik robots możesz też stworzyć za pomocą generatora. Dzięki takiemu rozwiązaniu nie musisz mieć wiedzy na temat składni pliku i jej działania. Musisz wiedzieć tylko jakie adresy lub roboty chcesz blokować i jakie wyjątki od tych reguł chcesz zastosować. Poniżej przedstawiamy przykłady darmowych generatorów dostarczanych przez Ryte oraz SeoBook.
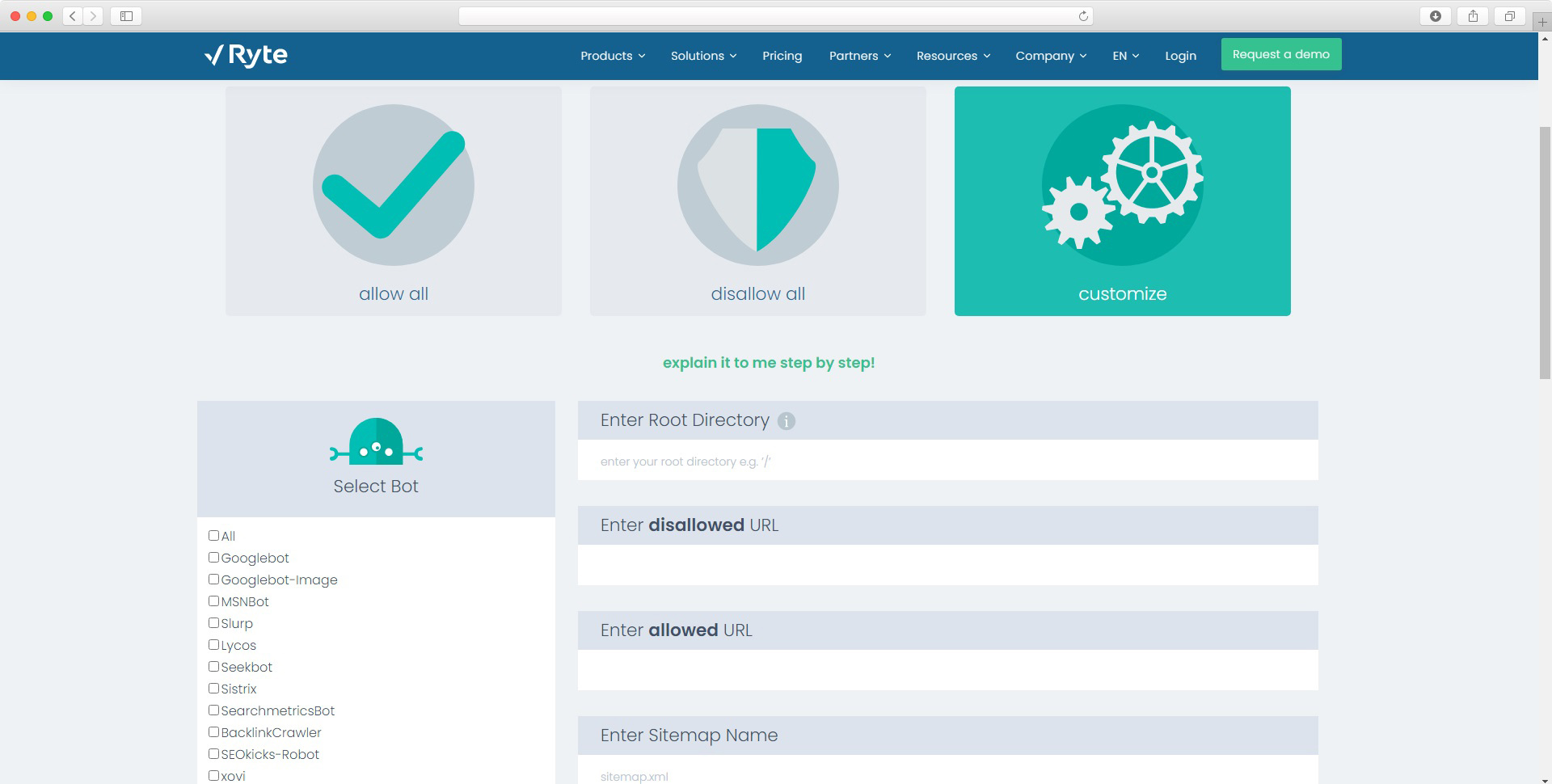
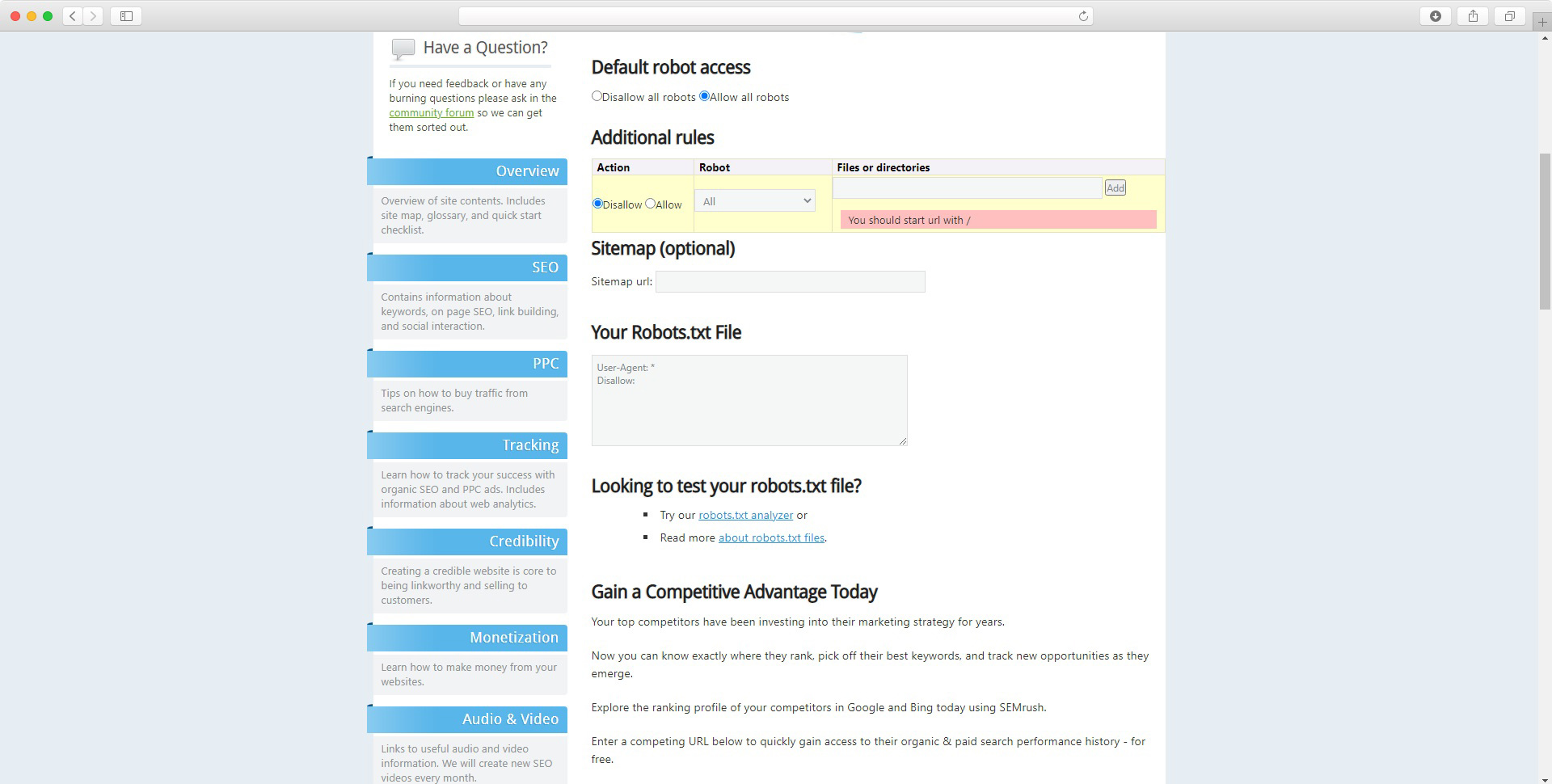
Dynamiczny plik robots - system CMS
Robots.txt może być zwykłym plikiem tekstowym znajdującym się na serwerze lub podstroną. Dla robotów nie ma to żadnego znaczenia, w obu wypadkach ścieżka dostępu jest identyczna (example.com/robots.txt). Format pliku pozostaje taki sam, zawartość jest więc odczytywana poprawnie.
Daje to trzecią możliwość generowania pliku robots, za pomocą systemu CMS (np. Wordpress), z którego korzystasz. Dzięki niej można stworzyć plik dynamiczny, który może być aktualizowany w zależności od ustawień indeksowania poszczególnych podstron i elementów. To bardzo wygodne rozwiązanie pozwalające łatwo zarządzać indeksacją. Gdy zablokujesz indeksowanie konkretnych podstron, CMS sam doda odpowiednią regułę do robots.txt. Nie będziesz więc musieć pamiętać o jego istnieniu i modyfikacjach.
Gdzie umieścić plik robots.txt?
Plik robots.txt musi znajdować się w głównym katalogu Twojej strony. Zawsze powinien być on dostępny pod adresem example.com/robots.txt. Nie można umieszczać go w podkatalogach.
Zanim przystąpisz do tworzenia swojego zbioru reguł, sprawdź, czy plik robots nie został już utworzony. Wpisz w wyszukiwarce swoją domenę i dopisz /robots.txt. Jeśli istnieje możesz go edytować lub zastąpić nowym. Pamiętaj, że każda strona może mieć tylko jeden plik robots.
Jak sprawdzić plik robots.txt?
Gdy stworzysz już robots.txt, możesz go przetestować. Dzięki temu będziesz wiedzieć, czy został on napisany poprawnie i czy Googleboty zastosują się do zawartych w nim wytycznych. By to zrobić, zaloguj się do Google Search Console i wejdź w link.
W narzędziu testowania pliku robots możesz zweryfikować też, czy poszczególne adresy URL będą skanowane przez roboty. Sprawdzanie pliku nie jest konieczne, może być jednak przydatne w przypadku bardzo rozbudowanych stron, gdy stosujesz wiele rozbudowanych reguł i wyjątków. W narzędziu tym możesz także powiadomić Google o wprowadzeniu zmian i poprosić o zaindeksowanie nowego pliku robots.txt.
Składnia robots.txt – ważne kwestie przy tworzeniu pliku
Plik robots.txt składa się z grup (co najmniej jednej), każda z nich zawiera:
- wskazanie do jakiego robota ma zastosowanie (User-agent),
- do których katalogów i plików robot może lub nie może uzyskać dostęp (dyrektywy Allow i Disallow),
- grupy są przetwarzane od góry do dołu, każdy robot jest dopasowywany tylko do jednej grupy reguł (tej, która najprecyzyjniej się do niego odnosi),
- wszystkie strony niezablokowane regułą Disallow: mogą być domyślnie indeksowane przez robota,
- roboty rozróżniają wielkość liter w regułach!
- w jednym wierszu może znaleźć się tylko jedna reguła,
- użycie gwiazdki "*" w dyrektywie User-agent: sprawia, że grupa odnosi się do wszystkich robotów, z wyjątkiem robotów AdsBot. Zablokowanie ich wymaga bezpośredniego wskazania,
- reguła dotycząca katalogu musi kończyć się znakiem "/".
User-agent: *
Disallow: /nazwa-katalogu/
- Reguła dotycząca konkretnej strony musi zawierać jej pełną nazwę,
- Symbol “*” może zostać użyty w dyrektywach User-agent, Allow oraz Disallow jako prefiks, sufiks lub cała ścieżka,
- Znak "$" dopasowuje wszystkie adresy URL kończące się określonym ciągiem
Przykład: reguła blokuje wszystkie adresy URL z końcówką .pdf
User-agent: *
Disallow: /*.pdf$
Przykładowe reguły w robots.txt
Blokada dostępu do całej strony (z wyjątkiem robotów AdsBot):
User-agent: *
Disallow: /
Blokada dostępu do katalogu i jego zawartości:
User-agent: *
Disallow: /katalog/
Blokada dostępu do katalogu i jego zawartości z wyjątkiem dla jednego pliku:
User-agent: *
Disallow: /katalog/
Allow: /katalog/plik.html
Blokada dostępu do jednego pliku:
User-agent: *
Disallow: /katalog/plik.xml
Blokada dostępu do jednej podstrony:
User-agent: *
Disallow: /strona-prywatna.html
Blokada dostępu do wszystkich plików o konkretnym rozszerzeniu:
User-agent: *
Disallow: /*.xml$
Korzystanie z robots.txt – o tym musisz pamiętać!
- Robots.txt nie służy do zabezpieczania dostępu do zasobów, jego zawartość jest publicznie dostępna. Jeśli chcesz zabezpieczyć dane, zastosuj odpowiednie uwierzytelnianie,
- Nie wszystkie roboty internetowe stosują się do zapisów zawartych w pliku robots! Roboty odpowiedzialne za sprawdzanie zabezpieczeń stron mogą ignorować wszystkie zawarte w nim reguły,
- Googlebot może indeksować zablokowane adresy URL jeśli natrafi na nie na innych stronach w postaci odnośnika, wówczas będą one widoczne w wynikach wyszukiwania.
Podsumowanie
Prawidłowe zaplanowanie reguł i zamieszczenie ich w robots.txt pozwala wpływać na proces indeksacji. W ten sposób możesz oddziaływać na pozycję swojej strony w Google. Szczególnie jeśli Twój serwis jest bardzo rozbudowany lub posiada adresy, które nie powinny być widoczne w wyszukiwarce. Plik robots w porównaniu do meta tagów to drobiazg, o który zdecydowanie warto zadbać, ponieważ im więcej “plusów” tym lepsze wyniki możemy osiągnąć.
Z tego artykułu dowiedziałeś się:
- Co to jest robots.txt i do czego służy
- Zawartość pliku robots
- Jak stworzyć plik robots.txt
Autorzy artykułu
Zespół Top Online
Adam Przybyłowicz
Product Lead i specjalista od researchu i rozwoju w Top Online. Zdobywa dla nas wiedzę, szuka nowych rozwiązań i pracuje nad tym, żebyśmy nie zostali w tyle. Prowadzi zespół tworzący m.in. YOSA.AI.


