
Raz na jakiś czas wpadnie mi w ręce strona, która w teorii powinna być w Google, ale w praktyce… ani po niej widu, ani słychu. Nie ma dramatu, to się po prostu zdarza. Zamiast panikować i zgadywać, korzystam ze swojego schematu i krok po kroku sprawdzam, co mogło pójść nie tak.
Spis treści:
- Czy strona w ogóle jest w indeksie Google?
- Czy strona sama blokuje swoją widoczność? Atrybut noindex, nofollow w sekcji <head> strony
- Plik robots.txt pod lupą
- Czy sitemapa pomaga czy przeszkadza?
- Linkowanie wewnętrzne w obrębie strony
- Duplikacja – sprawdzam, czy treści ze sobą nie konkurują
- Upewniam się, czy strona nie dostała bana od Google
- Wiek witryny też ma znaczenie
- Inne problemy techniczne na stronie
- Podsumowanie – sprawdzanie widoczności strony w Google
- Podsumowanie w punktach
Zobacz też:
Czy strona w ogóle jest w indeksie Google?
Zawsze zaczynam od absolutnych podstaw, bo zaskakująco często to właśnie tam leży problem. Wchodzę w Google i wpisuję prostą komendę: site:nazwadomeny.pl.
Jeśli widzę listę podstron, wiem, że Google już zna tę witrynę. Może nie rankuje jej wysoko, ale przynajmniej pojawia się w indeksie.
Jeśli natomiast wyników nie ma wcale, zapala mi się pierwsza lampka ostrzegawcza. To oznacza, że albo strona nie została jeszcze zaindeksowana, albo coś skutecznie blokuje roboty.
I dopiero tu zaczyna się właściwa analiza.
.webp)
Czy strona sama blokuje swoją widoczność? Atrybut noindex, nofollow w sekcji <head> strony
Kiedy mam podejrzenie, że coś blokuje indeksację, zaglądam do kodu HTML strony. Interesuje mnie głównie sekcja <head>, bo to tam często ukrywa się winowajca.
Szukam meta tagu noindex. Jeśli jest obecny, sprawa jest prosta – strona sama mówi Google: „nie pokazuj mnie w wynikach”. Robot może ją odwiedzać, analizować, ale finalnie i tak jej nie wyświetli.
Z atrybutem nofollow jest trochę inaczej, bo dotyczy linków, ale też potrafi narobić zamieszania, szczególnie jeśli ktoś zastosował go globalnie.
Najczęściej widzę ten problem po wdrożeniach. Strona była robiona na wersji testowej, ktoś dodał blokadę indeksowania… i zapomniał ją zdjąć, kiedy serwis miał wystartować. Klasyk.
Plik robots.txt pod lupą
Kolejny krok to sprawdzenie pliku robots.txt. Nie zajmuje mi to dużo czasu, a może szybko wyjaśnić sytuację.
Jeśli widzę tam zapis Disallow: /, to właściwie od razu mam odpowiedź. Ta reguła blokuje dostęp do całej strony dla robotów. I znowu – bardzo często to pozostałość po pracach deweloperskich.
Zdarza się też, że blokada dotyczy tylko wybranych podstron, które… akurat są kluczowe z punktu widzenia widoczności. Dlatego nie patrzę tylko na to, czy plik istnieje, ale też czy jego zawartość ma sens.
Czy sitemapa pomaga czy przeszkadza?
Przy nowych stronach prawie zawsze analizuję sitemapę. To taki drogowskaz dla robotów Google – pokazuje im, gdzie mają iść i co jest ważne.
Jeśli sitemapy nie ma albo nie została zgłoszona w Google Search Console, indeksowanie może być po prostu wolniejsze. Nic krytycznego, ale jest to jednak jakieś utrudnienie.
Natomiast często problem nie leży w jej braku, tylko w jakości. Widuję mapy zawierające stare URL-e, błędy 404 albo podstrony, których nie powinny tam być. Wtedy zamiast pomagać, mogą narobić bałaganu.
Dlatego nie traktuję sitemapy jako elementu do szybkiego odhaczenia, tylko faktycznie sprawdzam, co w niej siedzi i przede wszystkim – czy jest aktualna.
Linkowanie wewnętrzne w obrębie strony
Potem patrzę, jak strona jest połączona sama ze sobą. Linkowanie wewnętrzne często jest traktowane po macoszemu, a dla robotów Google ma ogromne znaczenie.
Jeśli jakaś podstrona nie ma żadnych wewnętrznych linków, które by do niej prowadziły, to dla robota praktycznie nie istnieje. Może ją znaleźć przypadkiem, ale równie dobrze może nigdy na nią nie trafić.
Często widzę to przy nowych sekcjach albo wpisach blogowych, które zostały wrzucone i zapomniane. Technicznie są dostępne, ale nic do nich nie prowadzi i funkcjonują trochę w oderwaniu od reszty serwisu.
Duplikacja – sprawdzam, czy treści ze sobą nie konkurują
Duplikacja to podstępny „zawodnik”. Na pierwszy rzut oka wszystko wygląda okej, ale w tle Google dostaje kilka bardzo podobnych wersji tej samej treści.
Wtedy zaczyna się problem z wyborem tej właściwej. W takiej sytuacji część podstron w ogóle nie trafia do indeksu, albo ich widoczność jest mocno ograniczona.
Z mojego doświadczenia wynika, że najczęściej trafiają się:
- powielone opisy produktów,
- różne warianty URL-i prowadzące do tej samej zawartości,
- wpisy blogowe rankujące na te same frazy kluczowe i odpowiadające na bardzo podobne pytania.
Upewniam się, czy strona nie dostała bana od Google
Na końcu zaglądam do GSC. Interesuje mnie sekcja „Bezpieczeństwo i ręczne działania”.
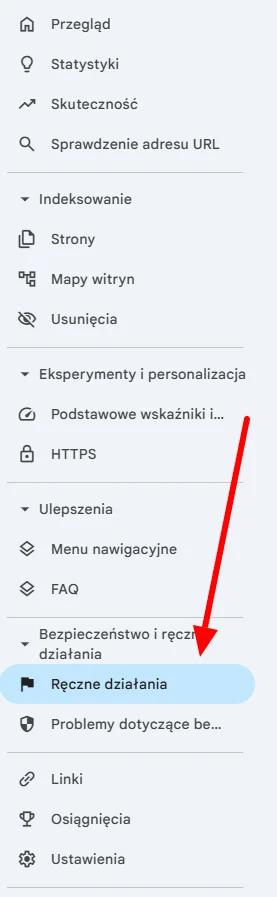
Zdarza się, że na stronę zostaje nałożona kara. Zespół Google robi to ręcznie – najczęściej chodzi o naruszenie wytycznych wyszukiwarki, np. spamowe linki, manipulacje wynikami wyszukiwania, ukrywanie treści w serwisie albo inne bardziej „kreatywne” działania.
Jeśli w sekcji „Ręczne działania” pojawia się komunikat, to wiem, że sprawa jest dość poważna.
W takich przypadkach nie ma drogi na skróty. Trzeba usunąć problem i dopiero potem wysłać prośbę o ponowne rozpatrzenie. Dopóki tego nie zrobię, strona może być praktycznie niewidoczna.

Wiek witryny też ma znaczenie
Są jednak takie case’y, że wszystko jest poprawnie ustawione, a strona dalej się nie pojawia w indeksie. Wtedy trzeba trochę ochłonąć i przypomnieć sobie, że… nowe domeny po prostu potrzebują czasu. Google musi je odkryć, przeanalizować i upewnić się, że warto je pokazywać użytkownikom. Nie dzieje się to od razu.
Czasem to kwestia kilku dni, a czasem kilku tygodni. W takich sytuacjach zamiast szukać problemów na siłę, obserwuję i sprawdzam, czy coś zaczyna się ruszać.
Inne problemy techniczne na stronie
Po drodze często wychodzą też mniej oczywiste, bardziej techniczne rzeczy:
- Błędne przekierowania, które prowadzą donikąd.
- Błędy serwera (np. 5xx), przez które roboty Google nie mogą wczytać strony.
- Podstrony zwracające 404 (wskazujące na nieistniejące adresy URL), mimo że ktoś nadal do nich linkuje.
- Problematyczna nazwa domeny, która utrudnia identyfikację i zrozumienie witryny.
Zdarza się też, że problemem jest wydajność. Strona ładuje się tak wolno, że roboty nie są w stanie jej sprawnie przeskanować. Pozornie jest to detal, ale w rzeczywistości może mocno wpłynąć na indeksację.
Podsumowanie – sprawdzanie widoczności strony w Google
Jak by to wszystko zgrabnie podsumować… Chyba najłatwiej powiedzieć, że brak widoczności w Google rzadko ma jedną przyczynę. Częściej to kombinacja kilku drobnych błędów – problemów z indeksacją, technikaliów, jakości treści i samego serwisu.
Dlatego nie kombinuję, tylko zawsze lecę swoim sprawdzonym schematem. Najpierw weryfikuję indeks, potem potencjalne blokady jak noindex czy robots.txt. Później zaglądam do sitemapy, analizuję linkowanie i sprawdzam duplikację.
Dzięki temu faktycznie rozumiem, co się dzieje. I to zazwyczaj pozwala mi dość szybko znaleźć odpowiedź na pytanie, dlaczego strony nie ma w Google.
Podsumowanie w punktach
- Na początku sprawdzam komendą
site:nazwadomeny.pl, czy Google w ogóle widzi stronę. - W kodzie strony sprawdzam, czy nie ma tagów blokujących indeksowanie lub śledzenie linków.
- Upewniam się, że plik robots.txt nie odcina robotom dostępu do całej witryny lub jej kluczowych części.
- Weryfikuję, czy plik sitemap.xml istnieje, jest aktualny i zawiera poprawne adresy URL.
- Analizuję, czy podstrony są odpowiednio połączone linkami wewnętrznymi, żeby robot mógł do nich dotrzeć.
- Sprawdzam, czy podobne lub identyczne treści nie konkurują ze sobą w obrębie jednej witryny.
- Zaglądam do Search Console, żeby wykluczyć ręczne kary od Google.
- Biorę pod uwagę, że nowe strony potrzebują czasu, zanim zaczną pojawiać się w wynikach wyszukiwania.
- Szukam ewentualnych błędów technicznych, które mogą utrudniać indeksowanie i dostęp do strony (błędy serwera, złe przekierowania itd.).
Autor artykułu
![[object Object] - Top Online](https://cdn.toponlineapp.pl/6865-maciej-wojciechowski.png)
Maciej Wojciechowski
W tłumie specjalistów SEO Maciej dosłownie wystaje ponad resztę - dwa metry wzrostu robią swoje. Dzięki temu szybciej dostrzega problemy na stronach, nawet jeśli narzędzia analityczne próbują udawać, że nic się nie dzieje. Kiedy nie optymalizuje serwisów, łapie za aparat albo gitarę, którą opanował metodą „YouTube i cierpliwość”. Lubi być w ruchu - czy to na treningu, czy na spacerze, byle nie przy biurku.
![[object Object] - Top Online](https://cdn.toponlineapp.pl/7496-ola-mlodzinska.png)
