
Jak stworzyć GPT-4 z dodatkową wiedzą? Za pomocą frameworku LangChain. A jak zrobić to bez programowania? Właśnie to Ci pokażę. Oto jak krok po kroku połączyć chatbota AI z własnymi danymi!
Spis treści:
Dwa słowa o chatbocie Ignasiu
Ignaś to Inteligentny Asystent SEO Top Online, czyli nasz robot, który pomaga nam realizować pozycjonowanie stron. Chatbot to jego część, dzięki której już niedługo każdy będzie mógł z nim porozmawiać – i uzyskać tym samym pomoc w samodzielnym SEO.
Tutaj nie będzie jednak o Ignasiu. O tym, po co konkretnie, jak i dlaczego powstał ten chatbot (i jak działa!) pisałem już w artykule podlinkowanym wyżej, pod spisem treści. W tym tekście pokażę Ci za to jak zrobić takiego bota krok po kroku.
Co tak właściwie robimy
To, co tutaj pokażę, to będzie w pewnym sensie taki „własny ChatGPT”, a dokładnie GPT-4 (lub GPT-3.5-turbo, na którym bazuje darmowy ChatGPT) z dodatkową wiedzą.
Nie będziemy jednak go szkolić/dostrajać, czyli stosować fine-tuning. Zastosujemy Retrieval Augmented Generation (RAG) – czyli automatyczne dodawanie informacji/wiedzy do promptów z wybranych przez nas zewnętrznych źródeł (na przykład z książek).
Mówiąc inaczej: połączymy model OpenAI z zewnętrznym systemem. Ten, po zadaniu pytania przez użytkownika, znajdzie najpierw w dodanych przez nas materiałach odpowiednie informacje, a potem uzupełni nimi otrzymane polecenie i dopiero wtedy wyśle je do GPT.
Efekt będzie podobny do tego, który dostałbym wysyłając do ChatGPT pytanie razem z wszystkimi informacjami potrzebnymi do udzielenia na nie rzetelnej odpowiedzi. Stworzymy własnego chatbota, który ma dodatkową, sprawdzoną wiedzę na dany temat.
Nie będziemy jednak niczego kodzić. Skorzystamy z gotowych rozwiązań, a konkretnie z otwartej aplikacji Flowise.
1. Wybór dodatkowej wiedzy
Zanim zacznę, muszę najpierw zdecydować, po co mi ten chatbot, do czego ma służyć i skąd mam wziąć dla niego dodatkową wiedzę, która na to coś pozwoli.
Skuteczność bota będzie zależeć od tego, czy nasz system będzie w stanie znaleźć i dodać do promptów właściwe fragmenty tekstu. To z kolei zależy od tego, jak przygotujemy bazę danych, ale i od tego, z czego będzie się ona składać.
Nasza dodatkowa wiedza musi dać się podzielić na kawałki o odpowiedniej długości. Tak, by nie były one zbyt długie, ale też, żeby jednocześnie zawierały możliwie pełne informacje.
Oczywiście nie będziemy robić tego ręcznie, ale struktura treści nie może być zbyt chaotyczna. W praktyce wystarczy, że będzie to w miarę poprawny, „normalny” tekst.
Mogą to być choćby teksty blogowe, poradniki, instrukcje, dokumentacje, książki, a nawet własne notatki.
Warto wiedzieć
Jako baza wiedzy najlepiej sprawdzą się treści o powtarzalnej strukturze, jak np. artykuły z jednego konkretnego bloga.
U mnie bazą dodatkowej wiedzy będzie kurs GA4 Grześka Słoki, w którego powstawaniu mam swój udział redagując teksty.
Chatbot będzie z kolei asystentem nowego użytkownika Analytics 4 – który pomaga odnaleźć się w narzędziu.
2. Instalacja i przygotowanie Flowise
Do zainstalowania i uruchomienia aplikacji, w której zbudujemy naszego bota, potrzebować będziemy najnowszej wersji Node.js (pobierzesz ją tutaj).
Po zainstalowaniu Node instalujemy Flowise. Otwieram w tym celu terminal/wiersz poleceń i wpisuję:
npm install -g flowise
Po zakończeniu instalacji uruchamiam aplikację, wpisując tym razem:
npx flowise start 
Jeśli wszystko gra, to Flowise powinno być już dostępne pod adresem http://localhost:3000/ w przeglądarce.
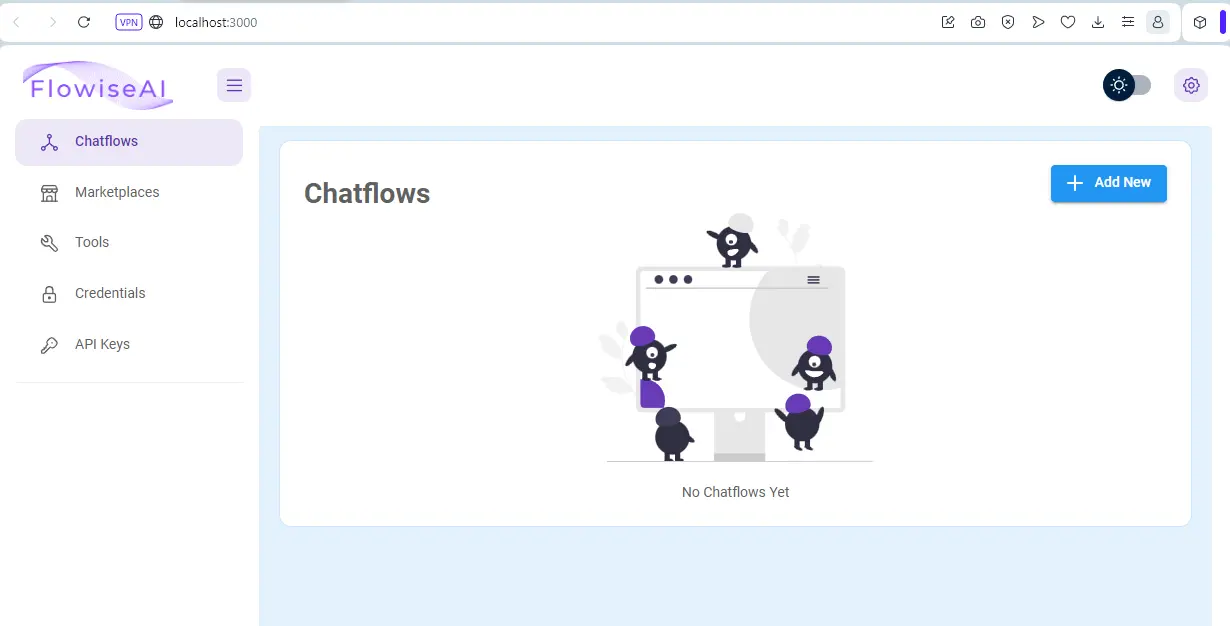
W taki sposób za każdym razem będziesz uruchamiać swoją aplikację. Jeśli interesuje Cię hostowanie jej zewnętrzne (tak, by zawsze była ona dostępna pod jakąś domeną), to o tym, jak to zrobić, przeczytasz w dokumentacji.
3. Przygotowanie kont OpenAI i Pinecone
Mamy aplikację, która pozwoli nam zbudować naszego bota. Potrzebujemy więc jeszcze dostępu do usług, z których będziemy korzystać. Czyli do platform OpenAI i Pinecone.
Myślę, że nie ma sensu, żebym tworzył tutaj kolejny poradnik rejestrowania się na platformie OpenAI. Pokaże więc tylko, gdzie (już na stworzonym koncie z podpiętą kart) znajdziesz klucze API.
Loguję się na konto. W prawym górnym rogu wchodzę w nazwę organizacji (lub „Personal” na koncie osobistym), a kolejno w „View API Keys”.
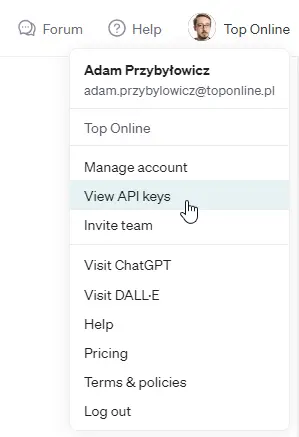
Tutaj generuję klucz API (+ Create new secret key):
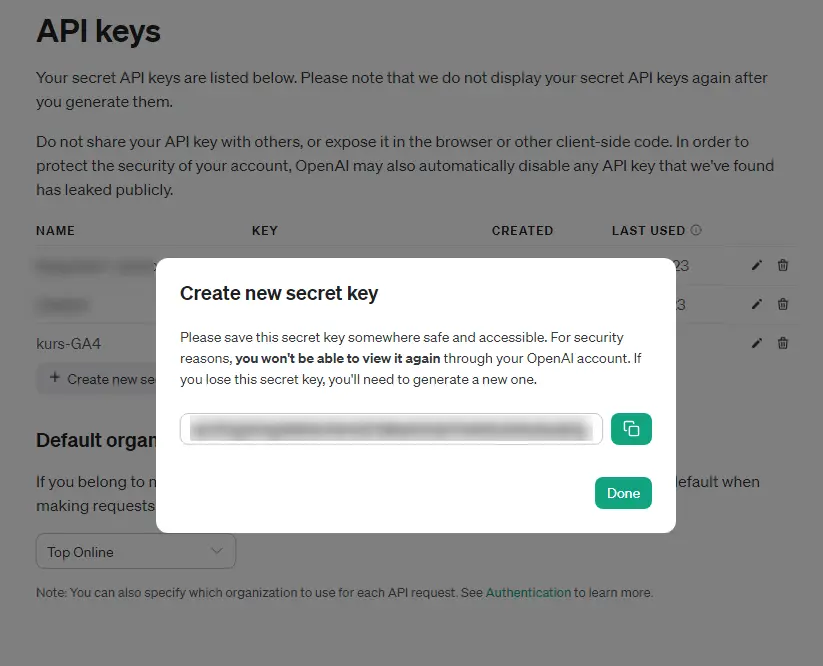
Kopiuję go i dodaję do zakładki „Credentials” we Flowise.
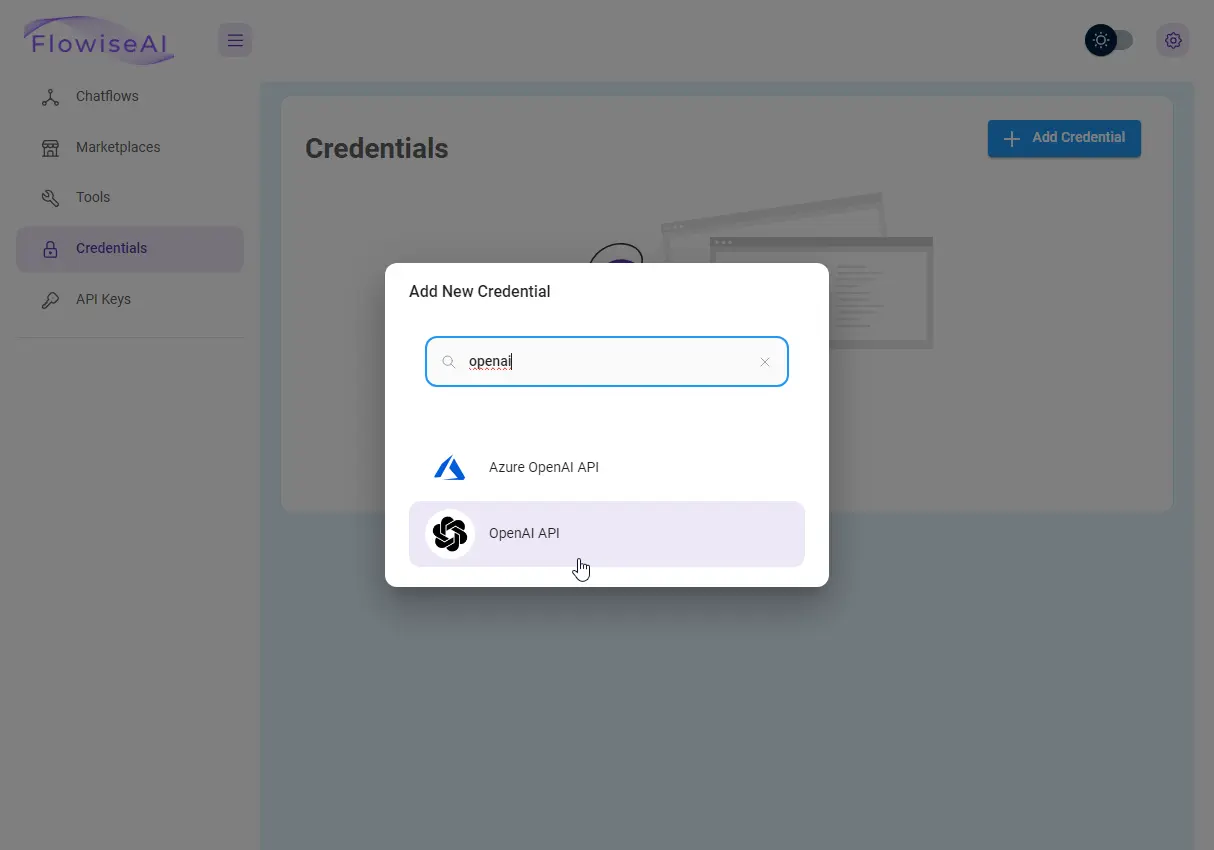
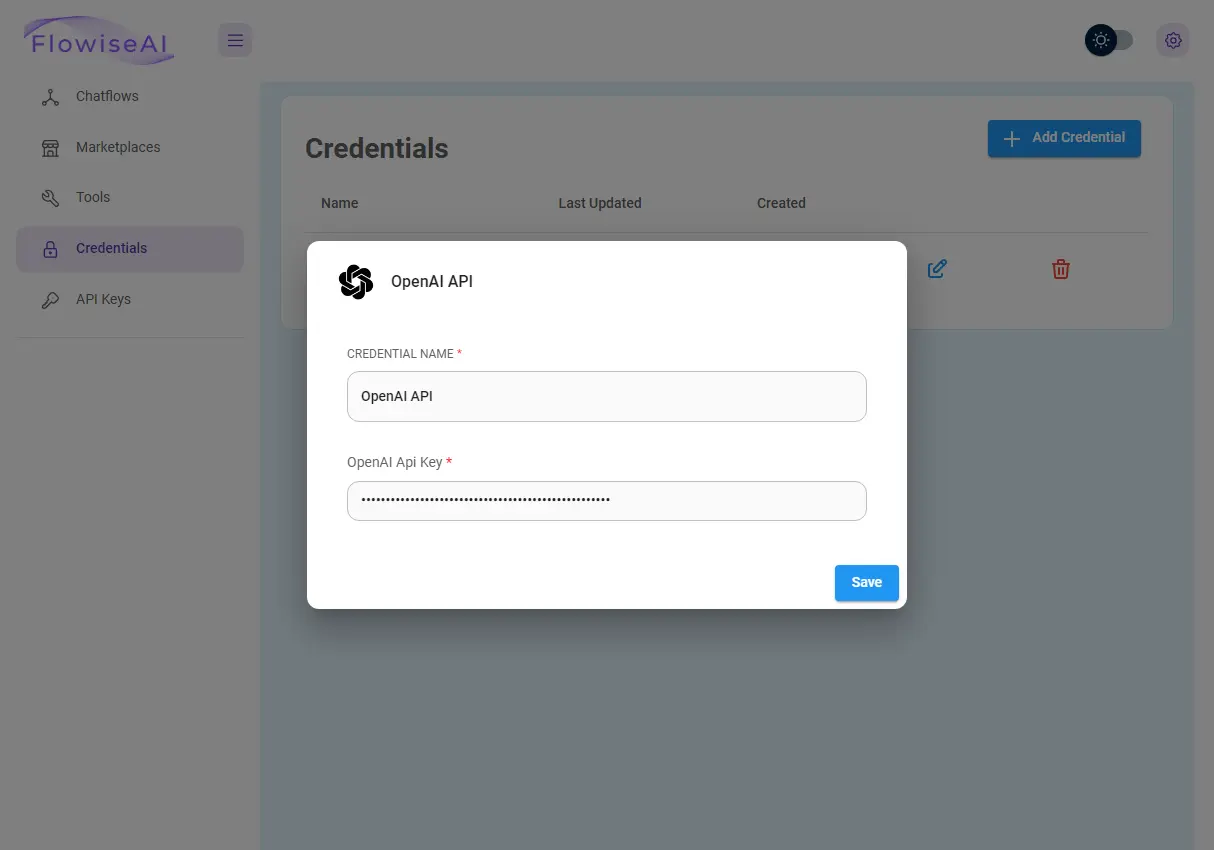
W tym samym miejscu dodam następnie klucz API Pinecone. Żeby go uzyskać, będę musiał jednak stworzyć najpierw konto i indeks, czyli naszą bazę danych.
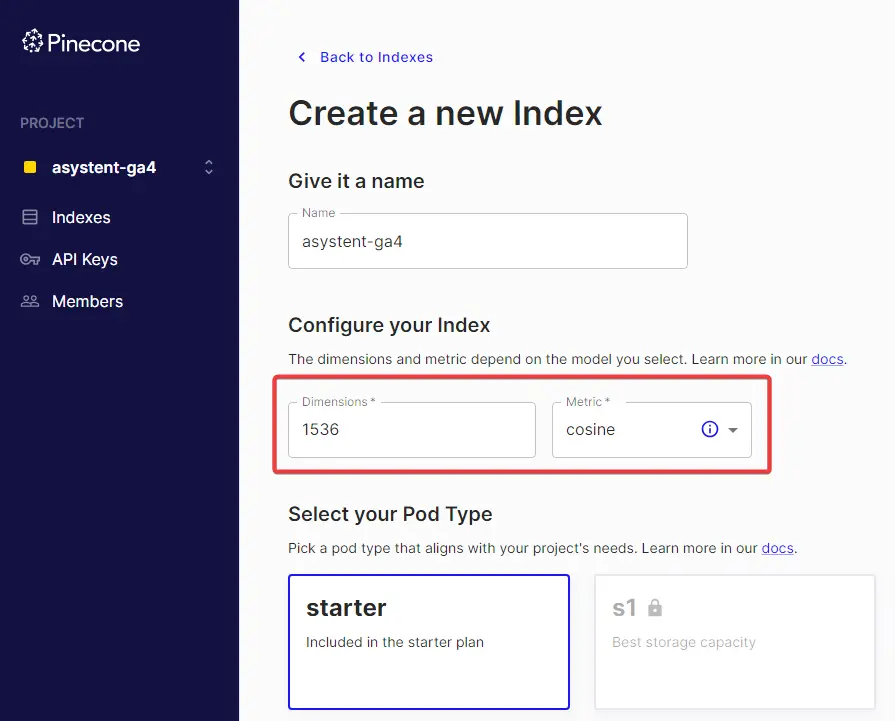
Wchodzę więc na stronę rejestracji Pinecone i zakładam konto. Po zalogowaniu do platformy w menu po lewej stronie tworzę nowy projekt, a następnie przechodzę do indeksów i tworzę nowy indeks.
Nazwa może być dowolna, kluczowym ustawieniem są tylko wymiary (dimensions), których musi być dokładnie 1536.
Gdy indeks jest już stworzony, przechodzę do „API Keys” i stąd kopiuję klucz oraz środowisko (environment).
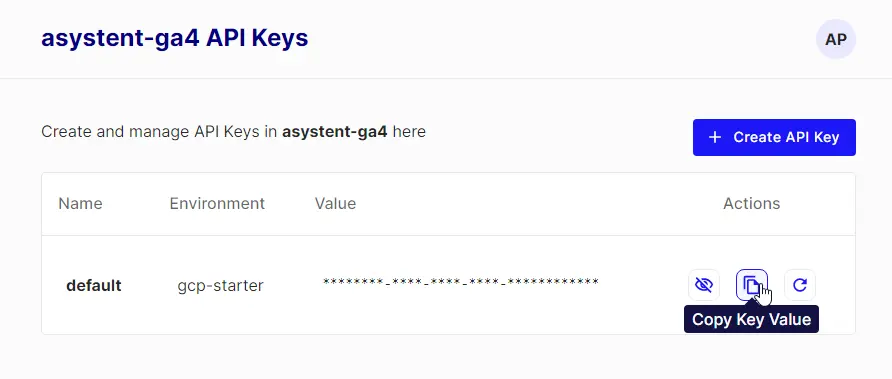
Dane te dodaję do Flowise, analogicznie do danych OpenAI (potrzebny będzie klucz API, nazwa środowiska i nazwa indeksu).
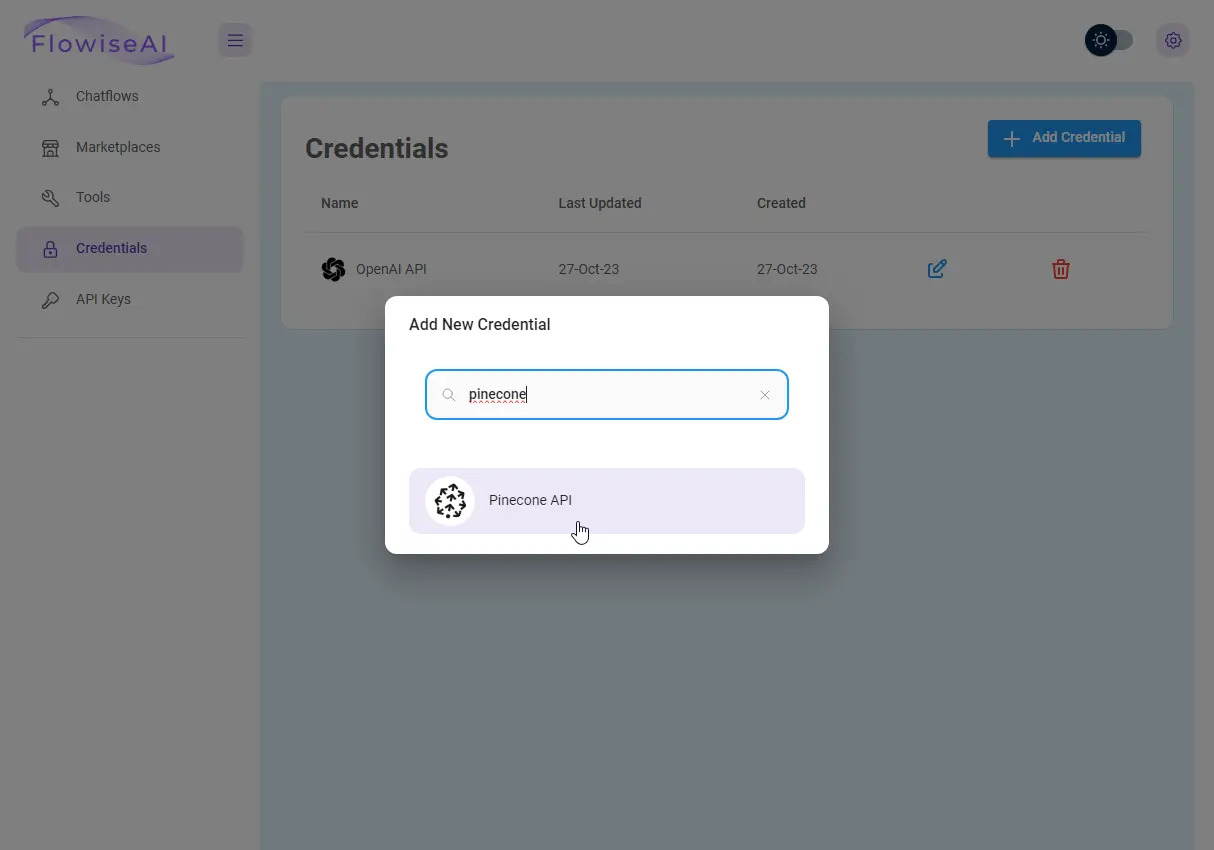
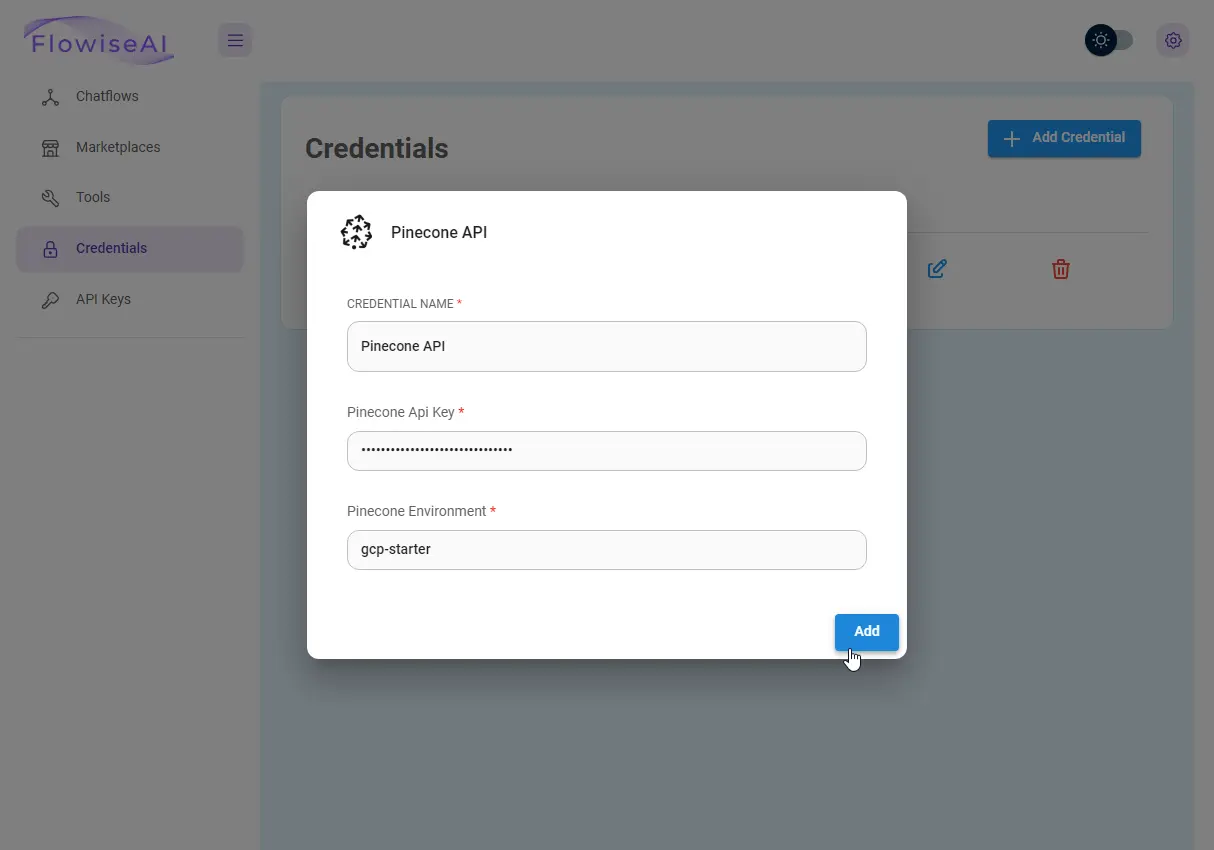
Warto wiedzieć
Pamiętaj, że Flowise pozwala na wykorzystanie wielu innych modeli AI, różnych baz danych i różnych usług (polecam testować!) – ja pokazuję tylko jedno z rozwiązań.
Na koniec otrzymuję taki obrazek:
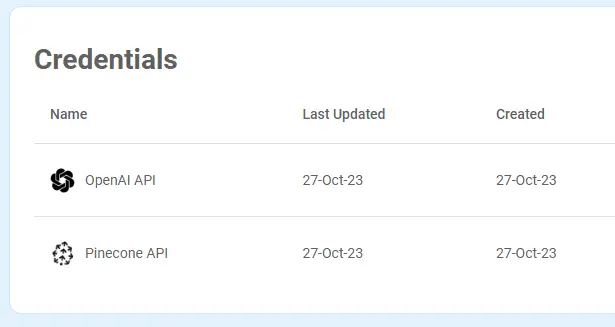
Klucze obu API mamy dodane, można iść dalej :)
4. Przygotowanie bazy wiedzy
Flowise bazuje na bibliotece Langchain, stworzonej po to, by ułatwić tworzenie aplikacji bazujących na dużych modelach językowych. Tak jak Langchain, pozwala więc pracować na różnych plikach i zapewnia gotowe narzędzia do ich przetwarzania (dzielenia na wspomniane kawałki).
Od TXT, PDF i DOC, przez JSON, CSV, HTML, aż po bazę danych Notion, całe repozytoria GitHuba czy pliki Figmy. My skupimy się na podstawowym „dodaniu wiedzy” do chatbota – stąd naszą bazą danych będzie tekst.
Ja na potrzeby przykładu wybrałem PDF – w takim formacie będę więc przygotowywał pliki z dodatkową wiedzą dla chatbota.
Zastosuję też podstawową metodę podziału treści, czyli recursive text splitter. Dzieli on tekst odmierzając fragmenty według podanej długości chunków (w tym wypadku mierzonych po prostu liczbą znaków) i rozdziela je na nowych liniach lub spacjach.
W praktyce znaczy to tyle, że będę potrzebować poprawnego tekstu bez zbędnych znaków typograficznych. Nie jest to niezbędne, ale usunę z niego też wszelkie zdjęcia, formatowanie, nagłówki i ozdobniki, żeby nic nie zaburzyło przetwarzania.
Na początek zebrałem materiały, czyli wszystkie opublikowane dotychczas części naszego kursu.
Kolejno z każdego z nich usunąłem formatowanie, elementy takie jak leady, spisy treści, grafiki i linki. Tak, żeby w mojej bazie wiedzy były tylko czyste informacje tekstowe. Przejrzałem też całość pod kątem nadmiarowych odstępów i fragmentów, które mogłyby zaszkodzić dzieleniu tekstu.
A na koniec zapisałem wszystkie teksty jako jeden plik PDF:
Warto wiedzieć
Ten etap jest czasochłonny, ale warto poświęcić mu czas. Od jakości bazy wiedzy zależy bezpośrednio jakość późniejszych odpowiedzi chatbota.
Jeśli chcesz tylko poeksperymentować, śmiało możesz „wrzucić” też kompletnie niezmieniony plik PDF. Oszczędzisz na czasie, a zobaczysz jak to działa – miej tylko z tyłu głowy, że takie nieprzygotowane w żaden sposób dane często dają przeciętne efekty.
Ja powyższy proces czyszczenia tekstu wypracowałem sobie testując różne konfiguracje. Na tekstach z naszego bloga, ale i m.in. na swojej pracy licencjackiej, na dostępnych w domenie publicznej książkach jak np. „Przygody Tomka Sawyera” czy… na instrukcji obsługi odkurzacza. :)
5. Wgranie danych do indeksu
Mamy apkę, mamy dostęp do usług i mamy bazę wiedzy. Czas więc poskładać z tego wszystkiego naszego chatbota.
We Flowise aplikacje buduje się za pomocą diagramów, tzw. Chatflows. Łączy się w nich gotowe bloki odpowiadające elementom aplikacji wg. logiki ich działania.
Przechodzę więc do zakładki Chatflows i klikam „Add new”. Następnie wybierając plusik rozwijam listę dostępnych elementów.
Potrzebował będę następujących:
- Conversational Retrieval QA Chain (z zakładki Chains) – ten element wykonuje sekwencję czatu, zarządzając zapytaniami, wyszukiwaniem danych i komunikacją z API usług,
- ChatOpenAI (z zakładki Chat models) – przez ten element łączymy aplikację z modelem czatu, GPT-4 lub GPT-3.5-turbo,
- Pinecone Upsert Document (z zakładki Vector Stores) – ten element wykona operację indeksowania naszych danych w bazie Pinecone.
- OpenAIEmbeddings (z zakładki Embeddings) – dostęp do API OpenAI Embeddings, dzięki któremu będziemy w stanie wykonać indeksacje i późniejsze wyszukiwania w bazie danych,
- PDF file (z zakładki Document Loaders) – pozwoli nam załadować i przetworzyć plik PDF
- Recursive Character Text Splitter (z zakładki Text Splitters) – pozwoli podzielić zawartość tego pliku na fragmenty do indeksowania
Wszystkie te elementy dodaje do mojego flow, a następnie łączę je ze sobą i uzupełniam ich konfigurację o dodane wcześniej klucze API.
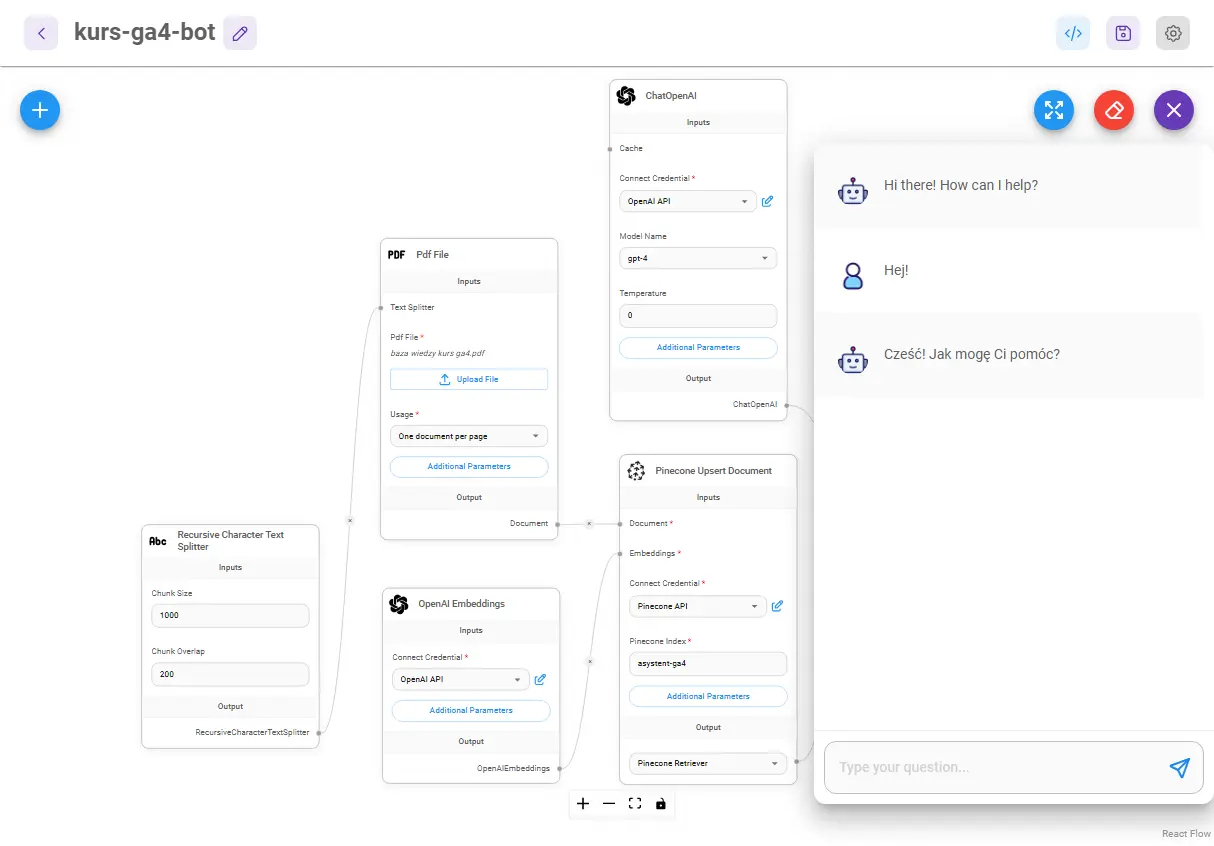
Gotowy chatflow wygląda tak:
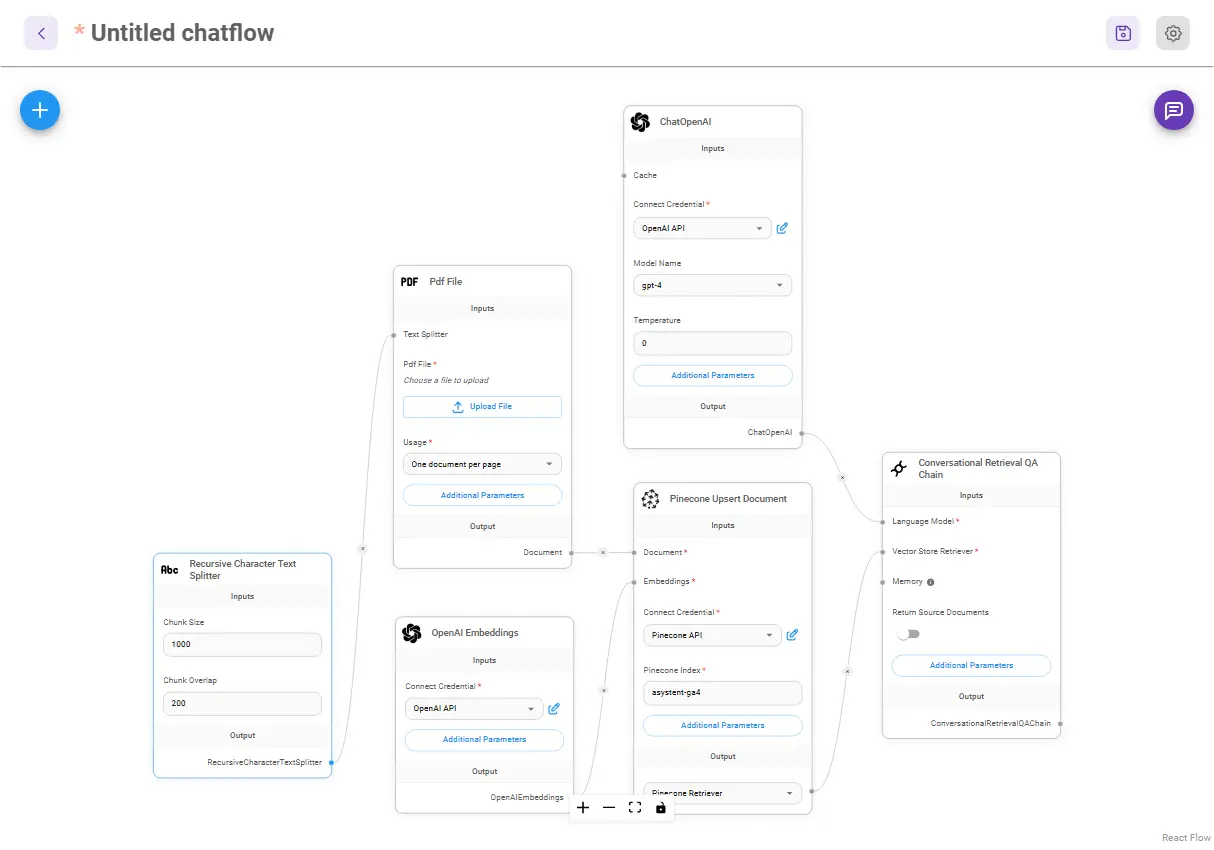
Jak widzisz, w module Pinecone dodałem nazwę indeksu, który utworzyłem wcześniej. W module Recursive Character Text Splitter ustawiłem z kolei parametry Chunk size: 1000 i Chunk overlap: 200.
Chunk size to tutaj liczba znaków w pojedynczym fragmencie, który będzie indeksowany w bazie danych. Chunk overlap to z kolei liczba znaków, które będą „zachodzić na siebie”, powtarzać się we fragmentach.
Fragment nr. 2 będzie miał na początku do 200 znaków z końca fragmentu 1, nr. 3 będzie powielał kawałek końca nr. 2 i tak dalej. Chodzi o to, żeby zachować możliwe pełne znaczeniowo akapity.
Jeśli wiesz, że do Twojej bazy wiedzy lepiej sprawdziłby się podział na krótsze kawałki, to możesz zmienić tę wartość.
Przy użyciu kilku plików każdy z nich może zostać też podzielony inaczej. Przykładowo, nasz chatbot Ignaś, ma w swojej „głowie” fragmenty indeksowane w 4 różnych konfiguracjach.
W każdym razie wszystko mamy już gotowe, pozostaje więc tylko załadować plik PDF do modułu PDF file.
Następnie zapisuje chatflow, klikam ikonkę chatu po prawej stronie i wysyłam dowolną wiadomość.
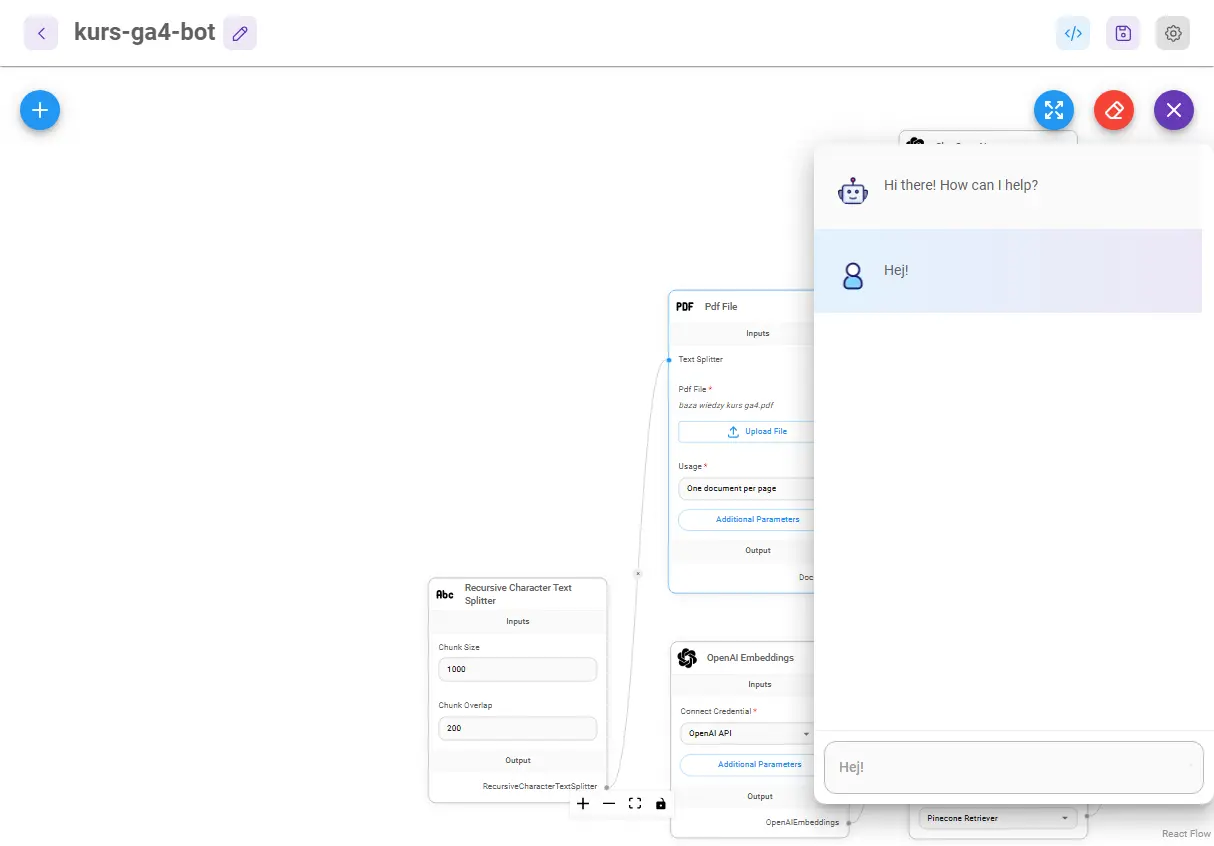
W ten sposób uruchomiłem swoją aplikację, system przetwarza więc dane i tworzy indeks.
Uwaga: to może trochę potrwać – im większa Twoja baza wiedzy, tym dłużej. Jeśli coś pójdzie nie tak, chat zwróci Ci błąd.
Chat odpowiedział… więc mam już swojego chatbota!
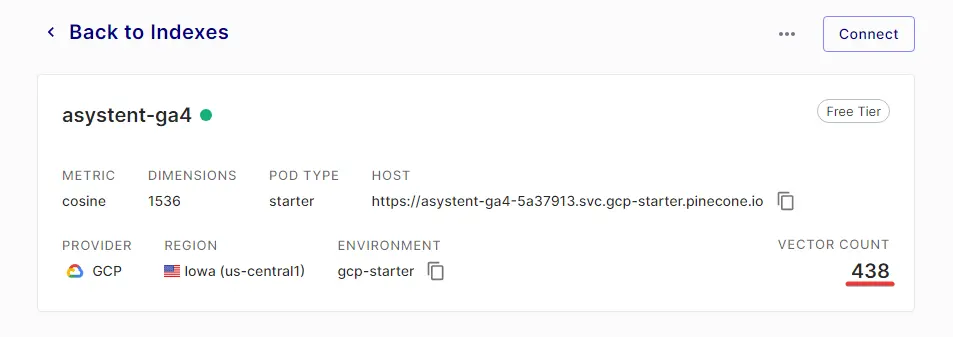
Dla pewności sprawdzam jeszcze indeks Pinecone - jeśli liczba wektorów wzrosła, a chat poprawnie odpowiedział na pytanie, to operacja udała się w 100%.
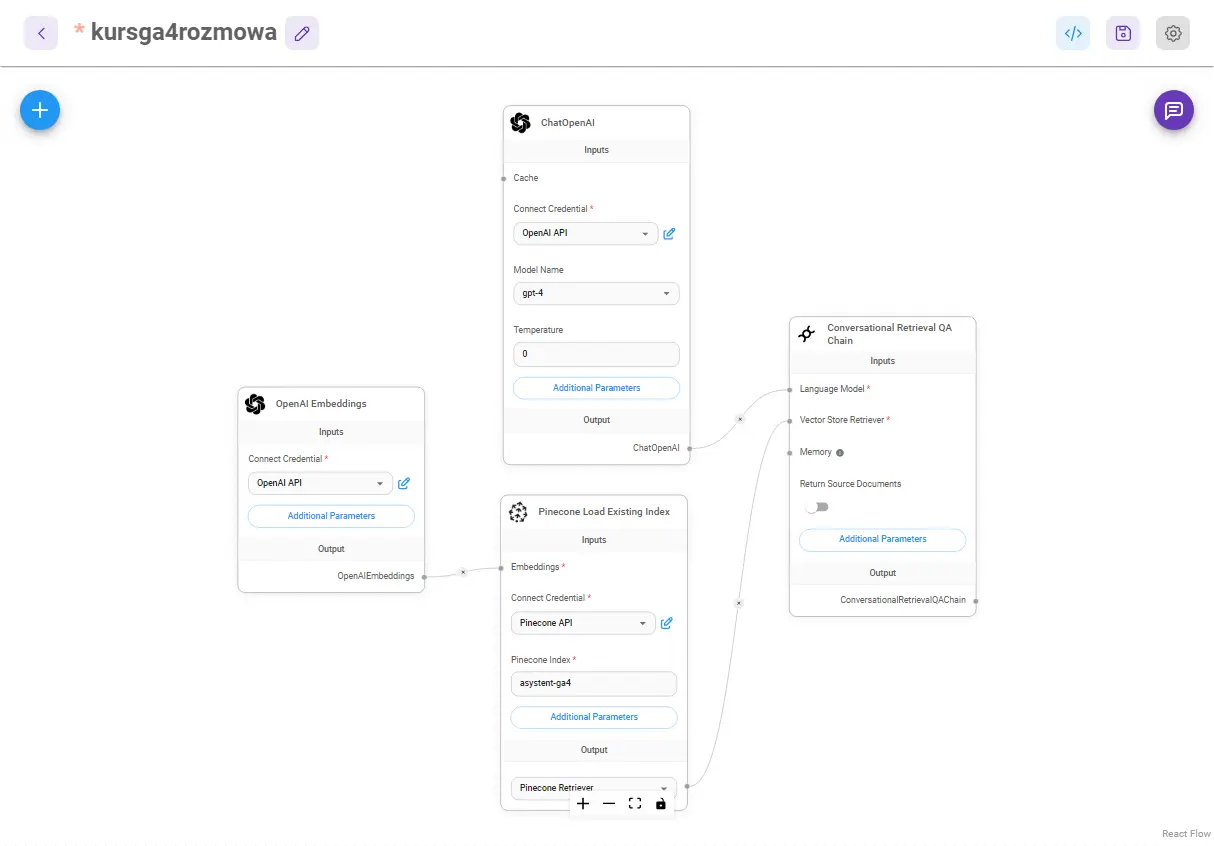
Na tym etapie w zasadzie możemy już korzystać z chatu, ale ja polecam jeszcze zmodyfikować jeden element: zamienić moduł Upsert document, na Load Existing Index i usunąć moduły do ładowania plików i podziału tekstu.
Tak, żeby przy kolejnych rozmowach z czatem już na 100% tylko wczytywać stworzoną bazę danych.
Jeśli chcesz dodawać kolejne pliki do swojego indeksu, to możesz też zrobić kopię swojego chatflow i wtedy go zmodyfikować. Stworzysz w ten sposób osobny, gotowy chatflow do dodawania kolejnych danych i osobny chatflow do konwersacji.
Warto wiedzieć
Kolejne pliki z wiedzą do swojego chatbota możesz dodawać powtarzając procedurę z tego punktu: po prostu dodaj nowy plik i wyślij jakieś polecenie do chatu.
6. Prompt chatbota
Mamy chat oparty o GPT3.5-turbo/GPT4, który odpowiada na pytania dotyczące naszej niestandardowej wiedzy. Teraz możemy jeszcze nadać mu indywidualny charakter lub określone zachowanie dodając prompt systemowy.
Taką dodatkową instrukcję możesz dodać w module Conversational Retrieval QA Chain, klikając w „Additional Parameters”.
Tutaj baaaardzo prosty przykładowy prompt dla bota kursu Google Analytics 4:
```
Prowadzisz korepetycje z używania Google Analytics 4. Znasz się tylko na tym narzędziu. Odpowiadaj zwięźle, prosto i zgodnie z prawdą, wyłącznie na podstawie otrzymanego kontekstu.
```
Samo tworzenie wewnętrznego polecenia dla chatbota (i zabezpieczanie się przed zmanipulowaniem go) to jednak temat na tyle rozległy, że poświęcę mu jeszcze pewnie osobny tekst.
Trochę porad o tym jak napisać dobry prompt znajdziesz w moim tekście: Gdy GPT nie rozumie, czyli podstawy dobrych promptów.
Jeśli jednak chcesz zdobyć podstawową, uporządkowana wiedzę o promptach, to polecam Ci kurs Prompt Engineering Podstawy dostępny na Eduweb.pl.
Efekt i jak korzystać z takiego chatbota
Żeby jeszcze pokazać efekty (i różnicę!), zadałem to samo pytanie w chacie, który tu wspólnie właśnie zrobiliśmy i w ChatGPT:
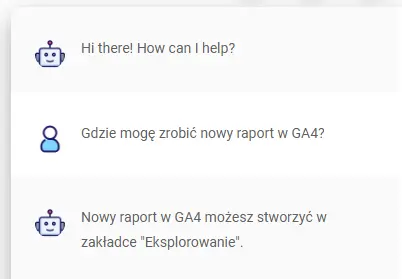
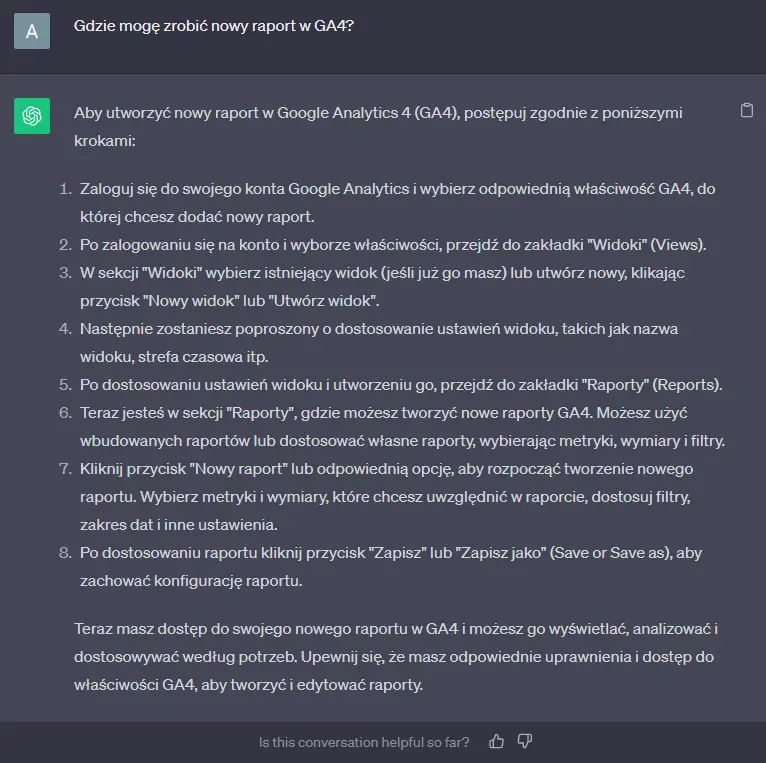
No dobra, a tak od strony praktycznej, jak z tego korzystać na co dzień?
Z takiego niestandardowego chatu mogę korzystać bezpośrednio w apce, wchodząc w okienko chatu naszego chatflow (tak, jak zadałem pytanie wyżej).
Mogę jednak także choćby osadzić sobie takie okienko czatu na dowolnej stronie internetowej, korzystać z czatu jako z API, albo i wygenerować osobną stronę czatu.
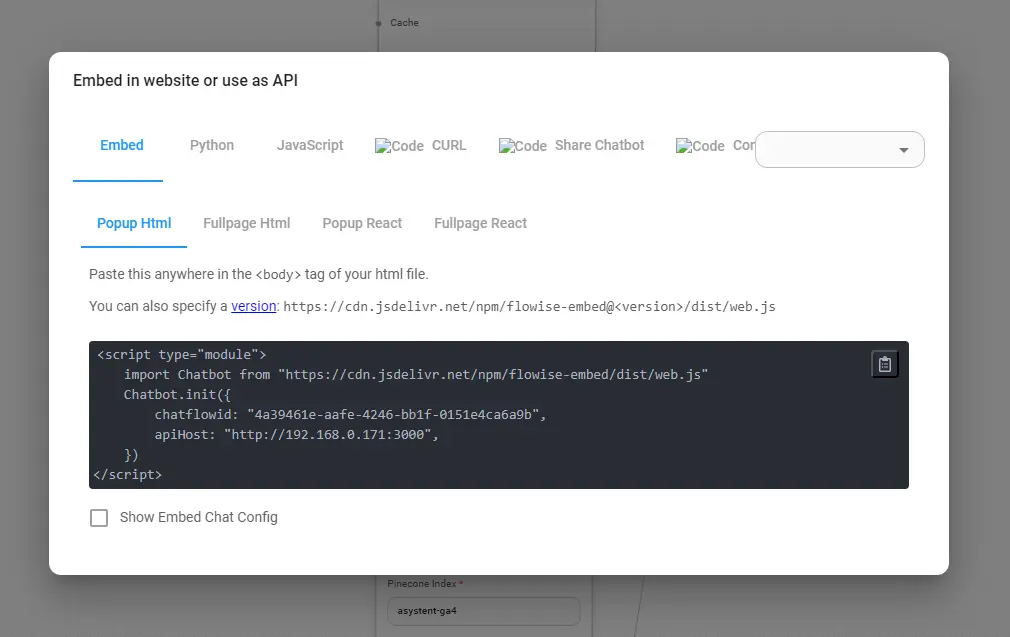
Wszystkie te opcje znajdziesz w prawym górnym rogu swojego chatflow, pod ikonką kodu.
Warto wiedzieć
Twój chat będzie działał tylko wtedy, gdy uruchomisz Flowise! Osadzenie go na stronie jest możliwe tylko wtedy, gdy aplikacja jest hostowana na serwerze.
Na koniec ponownie: polecam poczytać dokumentację Flowise.
Ograniczenia i możliwości
To, co tutaj pokazałem, to podstawy podstaw. Stworzysz w ten sposób bota, który pozwoli Ci porozmawiać z dodatkową wiedzą – co może być mega użyteczne. Nie polecałbym jednak publikowania takiego bota np. na swojej stronie dla użytkowników.
Choćby ze względu na to, że używanie API OpenAI jest płatne, a Flowise nie ma żadnego wbudowanego sposobu, który zabroniłby komuś np. używania prostego skryptu do nabicia nam ogromnych kosztów. Zresztą, to tylko wierzchołek góry lodowej.
Inne minusy tego rozwiązania to m.in. to, że nie możemy modyfikować wewnętrznych promptów, które są w języku angielskim (więcej pisałem o nich w tekście podlinkowanym pod spisem treści). Domyślnie mamy też mocno ograniczony dostęp do historii konwersacji.
Żeby nie było jednak tak negatywnie, pokazując podstawy, myślę, że nie pokazałem też ani 10% tego, co Flowise potrafi.
Przede wszystkim, jak na no code przystało, pozwala tworzyć aplikacje naprawdę ekspresowo. Oferuje też połączenia modeli językowych z różnymi narzędziami i masą zewnętrznych usług.
Możemy tu zrobić np. bota, który będzie odwiedzał wskazane przez nas strony, szukał informacji w Google czy wykonywał różne akcje. Opcji jest mnóstwo i polecam Ci się nimi po prostu pobawić.
Od razu podpowiadam również, że aplikacja ma swoją aktywną społeczność skupioną na Discordzie. No i Marketplace Flowise, wbudowany w aplikację. Znajdziesz w nim gotowe schematy (Chatflows), które można od razu przetestować w praktyce.
Podsumowanie w punktach
- Połączenie GPT-4 z dodatkową wiedzą najłatwiej jest zrealizować techniką RAG – czyli automatycznym dodawaniem fragmentów tekstu do promptów.
- Baza wiedzy chatbota powinna składać się z w miarę poprawnego, „normalnego” tekstu (np. artykuły blogowe, książki, własne notatki).
- Flowise, w którym stworzymy bota, instalujemy z terminala/wiersza poleceń – do czego potrzebny jest Node.js.
- Potrzebne będą też klucze API: OpenAI i Pinecone, które możemy uzyskać na platformach firm (w Pinecone tworząc indeks).
- Kolejny etap to przygotowanie bazy wiedzy: zebranie tekstów, usunięcie z nich zbędnych elementów i wyczyszczenie formatowania.
- Mając gotowe pliki przechodzę do stworzenia pierwszego Chatflow, uzupełniam konfigurację i wgrywam pliki.
- Rozpoczynam chat z botem i uruchamiam tym samym przetwarzanie danych.
- Następnie modyfikuję Chatflow, już do bezpośredniej konwersacji.
- No i na koniec przygotowuję polecenie wewnętrzne (system prompt) dla GPT-4, który nada mu indywidualny charakter.
Autor artykułu
Adam Przybyłowicz
Product Lead i specjalista od researchu i rozwoju w Top Online. Zdobywa dla nas wiedzę, szuka nowych rozwiązań i pracuje nad tym, żebyśmy nie zostali w tyle. Prowadzi zespół tworzący m.in. YOSA.AI.
![[object Object] - Top Online](https://cdn.toponlineapp.pl/5986-maciej-bednarski.png)

![[object Object] - Top Online](https://cdn.toponlineapp.pl/6865-maciej-wojciechowski.png)

![[object Object] - Top Online](https://cdn.toponlineapp.pl/6525-Jordan.png)
