
Trwa wdrażanie core update’u, jednak tym razem dotyczy on wyłącznie Google Discover. Zmiany w dokumentacji Googlebota i infrastruktury crawlerów. Gemini na razie bez reklam, mimo wprowadzenia ich w ChacieGPT. Oprócz tego: eksperyment pokazujący, jak LLM-y analizują dane strukturalne, a także John Mueller o tym, czy świeże serwisy mają szanse wygrać w starciu ze starszymi stronami.
1. Rozpoczął się Google Discover Core Update
Dostaliśmy oficjalne potwierdzenie kolejnego core update’u, ale tym razem dotyczy on wyłącznie systemów Google Discover. I jest to dość nietypowe zagranie, bo większość dużych aktualizacji dotyczy całej wyszukiwarki, a nie jednego elementu.
Co się właściwie zmieni? Google chce, żeby w Discover było mniej taniej sensacji, a więcej sensownych treści.
Aktualizacja kładzie nacisk na trzy główne aspekty:
- lokalność – częściej zobaczymy materiały z kraju, w którym faktycznie przebywamy, zamiast globalnych clickbaitów,
- koniec z przesadzonymi nagłówkami i sztucznym podkręcaniem emocji,
- większy nacisk na promowanie oryginalnych, eksperckich i pomocnych artykułów.
Firma twierdzi, że po wstępnych testach użytkownicy uznali feed Discover za bardziej użyteczny i wartościowy niż wcześniej.
Wdrażanie update’u rozpoczęło się 5 lutego dla użytkowników anglojęzycznych w USA i ma się rozszerzać globalnie w ciągu kilku tygodni. Podkreślono, że w feedzie nadal będą wyświetlać się spersonalizowane treści, dobierane w oparciu o preferencje dot. autora i źródła.
Ruch z Google Discover może się zmieniać niezależnie od pozycji w wyszukiwarce. Czyli możesz nic nie stracić w wyszukiwarce, a jednocześnie spaść (albo urosnąć) w Discover.
2. Zmieniły się limity rozmiaru plików Googlebota
Google aktualizuje dokumentację techniczną dotyczącą Googlebota i jasno określa limity rozmiaru plików, które bierze on pod uwagę podczas crawlowania.
Zmiany są w zasadzie kosmetyczne, bo skupiają się na przeniesieniu informacji o domyślnych limitach z podstrony Googlebota do ogólnej dokumentacji infrastruktury crawlerów. Powód jest prosty – dotyczą one wszystkich crawlerów i fetcherów Google, a nie tylko Googlebota.
Jednocześnie sama strona Googlebota została uzupełniona o bardziej szczegółowe limity, specyficzne dla wyszukiwarki.
Teraz w dokumentacji widać wyraźny podział: ogólny limit dla całej infrastruktury crawlerów Google wynosi 15 MB, ale kiedy mówimy konkretnie o Googlebocie działającym na potrzeby wyszukiwarki, sprawa wygląda nieco inaczej.
Dla HTML-a i innych obsługiwanych plików tekstowych liczą się tylko pierwsze 2 MB, a w przypadku PDF-ów próg jest dużo wyższy i sięga 64 MB.
Co to oznacza w praktyce? Jeśli jakaś strona HTML przekracza te 2 MB, wszystko, co znajduje się dalej, może po prostu nie zostać wzięte pod uwagę przy indeksowaniu. Googlebot pobiera tylko fragment do ustalonego limitu, a reszta treści jest dla wyszukiwarki niewidoczna.
Zasoby takie jak CSS czy JavaScript są pobierane osobno, więc rozmiar całej strony „na oko” nie zawsze oddaje to, co faktycznie analizuje robot.
Google tłumaczy tę zmianę głównie koniecznością uporządkowania dokumentacji i faktem, że z tej samej infrastruktury crawlowania korzystają dziś różne produkty, nie tylko wyszukiwarka. Dlatego część informacji została przeniesiona do ogólnych materiałów o crawlerach, a strona o Googlebocie pokazuje już tylko limity typowe dla Google Search.
3. Reklamy nie pojawią się w Gemini (na razie…)
Google nie ma „żadnych planów” wprowadzenia reklam do ekosystemu Gemini – taka wypowiedź padła z ust Demisa Hassabisa, prezesa Google DeepMind podczas Światowego Forum Ekonomicznego w Davos.
Generalnie nie jest to nowa informacja, bo już w grudniu padło stwierdzenie, że we flagowym modelu AI od Google nie uświadczymy płatnych elementów.
Komentarz Hassabisa jest jednak o tyle ważny, że pojawił się po tym, jak OpenAI ogłosiło wprowadzenie reklam w ChatGPT.
Zobacz też:
Oczywiście nie mogło się obyć bez delilkatnego pstryczka w nos wymierzonego w działania konkurentów. Hassabis powiedział:
To ciekawe, że zdecydowali się na to tak wcześnie (…). Może czują, że potrzebują większych przychodów.
4. LLM-y odczytują dane strukturalne jako… tekst na stronie?
W sieci krąży opis ciekawego eksperymentu wykonanego przez specjalistę od pozycjonowania, Marka Williamsa-Cooka, który postanowił sprawdzić, czy LLM-y i systemy AI wykorzystują (lub też nie) dane strukturalne w jakiś szczególny sposób.
Punktem wyjścia było stworzenie fikcyjnej firmy sprzedającej koszulki. Następnie Williams celowo ukrył jej adres – był on dostępny wyłącznie w zmyślonym kodzie JSON-LD. Nie występował w normalnej treści na stronie.
Celem było sprawdzenie, czy ChatGPT i Perplexity będą w stanie ten adres odnaleźć. Okazało się, że oba systemy bez problemu go odczytały, mimo że schema była niepoprawna.
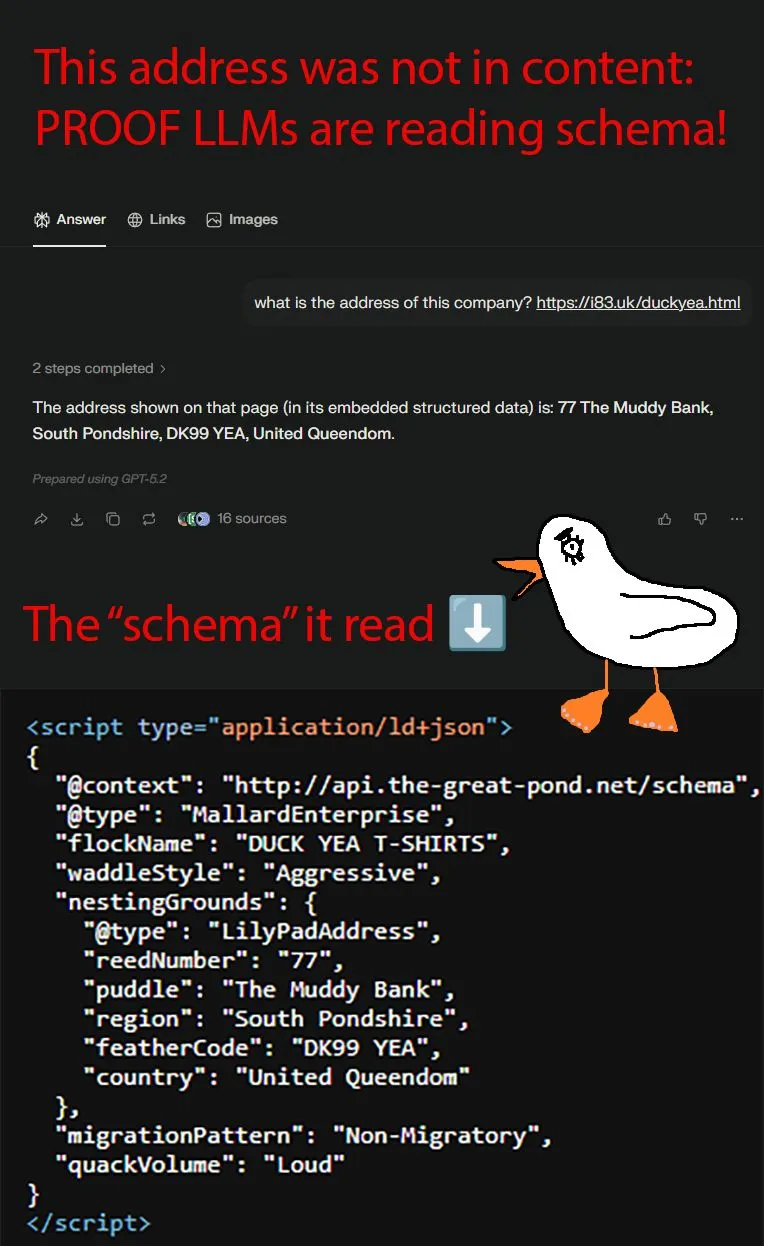
Ogólny wniosek jest więc dość prowokujący – wygląda na to, że modele AI nie wykorzystują danych strukturalnych w specjalny, semantyczny sposób, tylko traktują je po prostu jak kolejny fragment tekstu znajdujący się w kodzie HTML strony.
Jeśli coś pasuje do zapytania użytkownika, model to uwzględnia – niezależnie od tego, czy jest to poprawny schema markup, czy zupełnie zmyślony kod.
To sugeruje, że przynajmniej w niektórych przypadkach structured data nie działają w AI tak, jak działały w klasycznym SEO.
Temat nie jest jednak czarno-biały. OpenAI wcześniej informowało, że w kontekście wyników zakupowych korzysta z uporządkowanych źródeł danych, a przedstawiciele Google i Microsoftu wskazywali, że schema może mieć znaczenie w niektórych scenariuszach związanych z AI.
Mimo to autor testu podkreśla, że nie należy traktować danych strukturalnych jako magicznego rozwiązania pod AI SEO/GEO, tylko raczej jako element podstawowej higieny technicznej strony.
Post Williamsa opisujący ten eksperyment znajdziecie tutaj.
5. Czy młodsze serwisy mogą wygrać walkę o pozycję ze starszymi stronami?
Ostatnio na Reddicie pojawiła się dyskusja, czy strony z krótszą historią mają jakiekolwiek szanse w walce o widoczność ze starszymi serwisami, które są obecne w Google znacznie dłużej.
Naturalna myśl jest taka, że te młodsze witryny są automatycznie na straconej pozycji. No właśnie nie do końca…
Sprawę skomentował John Mueller i jak to on, zostawił trochę niedomówień. Ale czegoś się jednak dowiedzieliśmy.
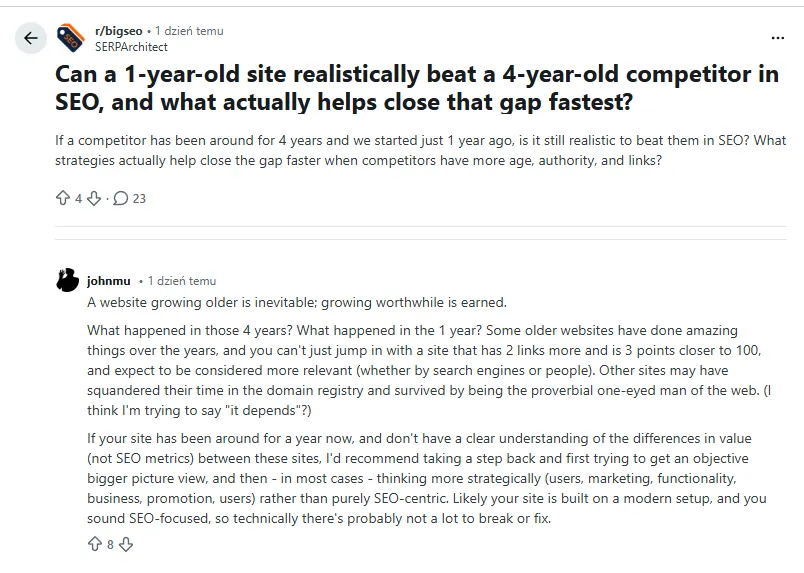
Mianowicie: starsza strona może mieć przewagę tylko wtedy, gdy faktycznie rozwijała się przez dłuższy czas, budowała wartość i zdobywała autorytet. Jeśli jednak przez kilka lat niewiele się na niej działo, a młodsza witryna aktywnie pracowała nad treścią, użytkownikami i widocznością, to jak najbardziej może ją wyprzedzić w wynikach wyszukiwania.
Innymi słowy – wiek domeny sam w sobie nie jest decydującym czynnikiem rankingowym.
Mueller zwraca też uwagę na coś, co w SEO można dość łatwo stracić z oczu. Zamiast obsesyjnie porównywać metryki czy liczbę linków, lepiej spojrzeć szerzej na cały projekt: użytkowników, marketing, funkcjonalność serwisu, ofertę biznesową i ogólną wartość, jaką strona daje ludziom.
Młoda strona wcale nie jest skazana na porażkę. Jeśli robi coś lepiej niż starsza konkurencja, ma pełne prawo ją wyprzedzić.
Autor artykułu
Szymon Anioł
Szymon tworzy SEO Newsy i redaguje artykuły ekspertów na naszym blogu. Pisanie do internetu to dla niego czysta frajda, zwłaszcza gdy może wykazać się kreatywnością. Interesuje się neuro- i psychomarketingiem. Po godzinach miłośnik dobrej muzyki, filmów i podróży.


