
Na grupie SEO Samodzielni często pojawiają się pytania, co może być nie tak ze stroną, kiedy nagle zalicza spadki w wynikach wyszukiwania. Zamiast rzucać teorią, pokażę Ci po prostu, jak ja podchodzę do sprawdzania witryn w Screaming Frog – narzędziu, z którego korzystam na co dzień. Nawet w darmowej wersji da się z niego sporo wyciągnąć, więc nie trzeba od razu szykować portfela. Lecimy!
- Czym jest Screaming Frog?
- Pierwsze kroki ze Screaming Frog
- Jak audytuję stronę w Screaming Frog?
- Analiza meta tagów (title, description)
- Sprawdzanie nagłówków H1, H2
- Sprawdzenie jakości treści – zakładka Content
- Błędy techniczne strony
- Statusy HTTP
- Przekierowania 301 – filtr Internal Redirect (3xx)
- Problemy z indeksowaniem – zakładka Directives
- Sprawdzenie adresów URL – zakładka URL
- Sprawdzenie zdjęć – zakładka Images
- Sprawdzenie bezpieczeństwa – zakładka Security
- Sprawdzenie linków wychodzących – zakładka External
- Sprawdzanie pozostałych błędów w Screaming Frog
- Tryb list, czyli jak obejść limit 500 adresów?
- Podsumowanie
Zobacz też:
Czym jest Screaming Frog?
Screaming Frog SEO Spider to rodzaj crawlera, który skanuje witrynę tak, jak robi to robot Google. Dzięki temu możesz łatwo sprawdzić, co działa dobrze, a co wymaga poprawy.
Jest to podstawowe narzędzie używane przez specjalistów od pozycjonowanie stron – w tym przeze mnie i pozostałych chłopaków z Top Online.
SC działa lokalnie – instalujesz go na swoim komputerze i od razu masz dostęp do danych z witryny: tytułów stron, meta opisów, statusów HTTP, struktury nagłówków, przekierowań, błędów 404, linków wewnętrznych i zewnętrznych, a nawet atrybutów ALT przy obrazkach.
Wersja darmowa nie jest idealna, ale nadal umożliwia wykonanie całkiem solidnego audytu.
To jeden z tych programów, które z czasem stają się Twoim SEO-asystentem na pełen etat.
Pierwsze kroki ze Screaming Frog
Zaczynamy od instalacji – prosta sprawa, pobierasz narzędzie ze strony producenta https://www.screamingfrog.co.uk/seo-spider/ i instalujesz jak każde inne oprogramowanie. Są wersje dostępne na Windowsa, macOS i na Linuxa.
Ja pokażę Ci wszystko na przykładzie darmowej wersji. Ma ona swoje ograniczenia (np. brak integracji z GSC czy limit 500 adresów URL), ale spokojnie – i tak da się tutaj sporo zrobić.
Wersja free pozwala na użycie dwóch trybów:
- Spider (czyli skanowanie całej strony).
- List (gdzie ręcznie podajesz adresy do analizy).
Na start zostajemy w trybie Spider. Wklejasz swoją domenę, klikasz Start i czekasz, aż narzędzie przeskanuje wszystko, co znajdzie.
Jak audytuję stronę w Screaming Frog?
Screaming Frog zbiera masę danych. Czasem trwa to chwilę, czasem dłużej – wszystko zależy od rozmiaru strony. Dla serwisów w granicach 500 URL-i jest to zwykle kilka minut.
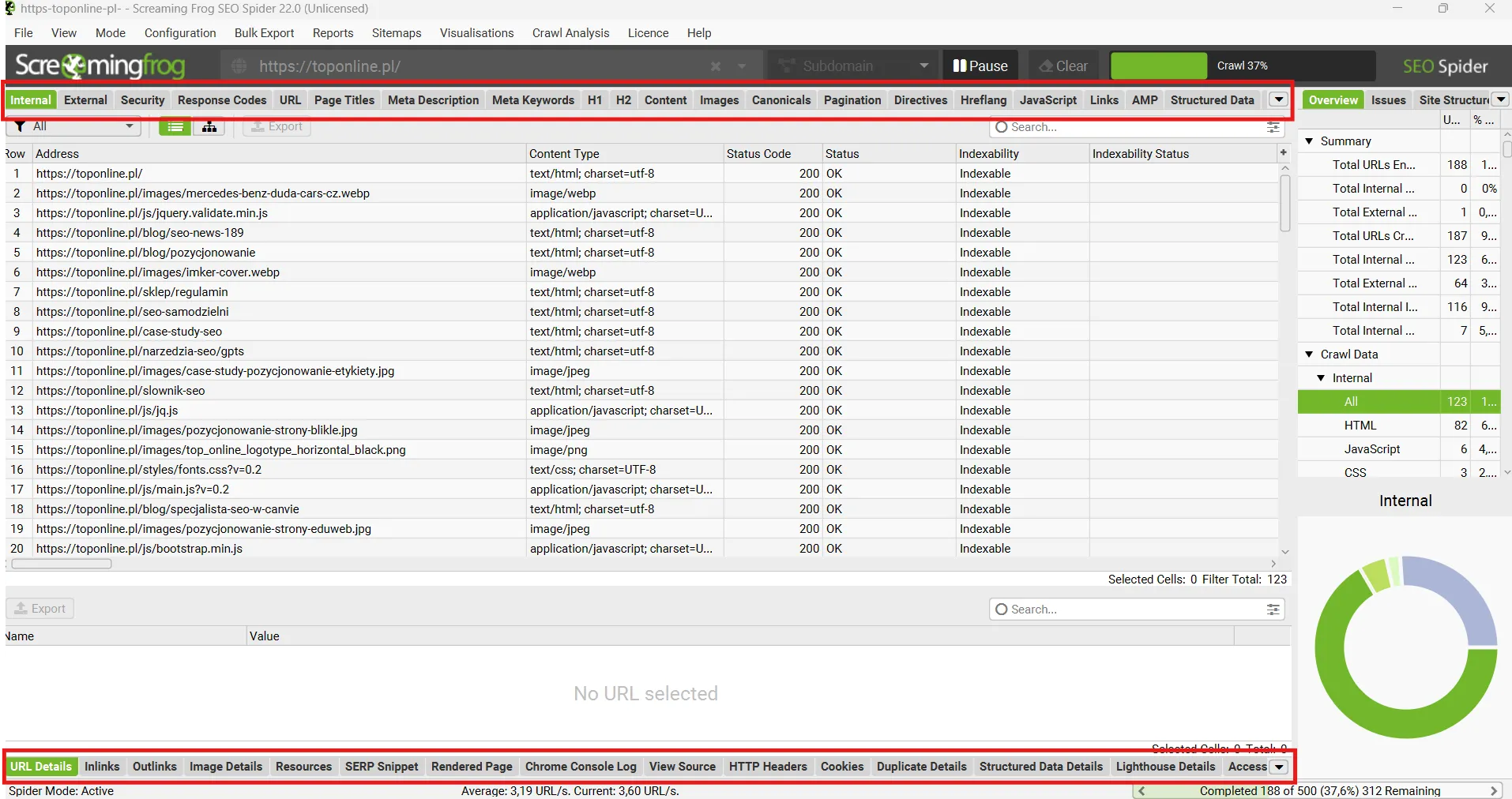
W narzędziu jest sporo zakładek. Ja na co dzień zaglądam do tych sekcji:
- Internal (czyli całość analizy bez filtrów),
- External (linki wychodzące),
- Security (czy wszystko jest na HTTPS),
- Response Codes (tej karty używam najczęściej, to centrum informacji o wszystkich kodach odpowiedzi serwera: 200, 3xx),
- URL (struktura adresów),
- Page Titles,
- Meta Description,
- Nagłówki H1 i H2,
- Content (analiza zawartości strony),
- Images (czy zdjęcia nie są za ciężkie albo bez altów),
- Canonicals (dane o zastosowaniu linków kanonicznych),
- Hreflang (info o tagach hreflang dla stron z różnymi wersjami językowymi).
Dolne menu daje szczegóły o wybranym URL-u – tam podglądam np. kod odpowiedzi HTTP, anchor texty, linki wewnętrzne i zewnętrzne czy dane o grafikach. Po prawej mam filtry, które pozwalają mi wyciągnąć dokładnie to, czego szukam.
Analiza meta tagów (title, description)
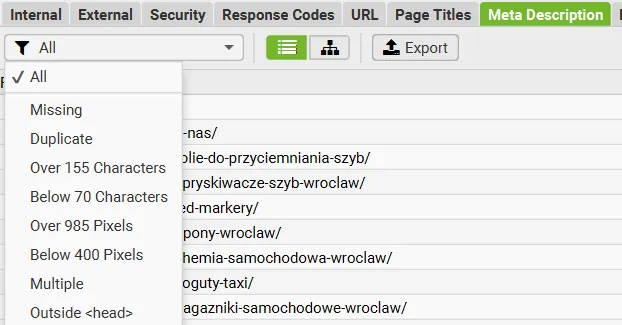
Nie będę się tu skupiał na dopasowaniu odpowiednich słów kluczowych, tylko na typowo technicznych błędach – brakujących, powielonych, za krótkich lub za długich meta title i description. Screaming Frog pozwala to wszystko szybko wyłapać i posortować.
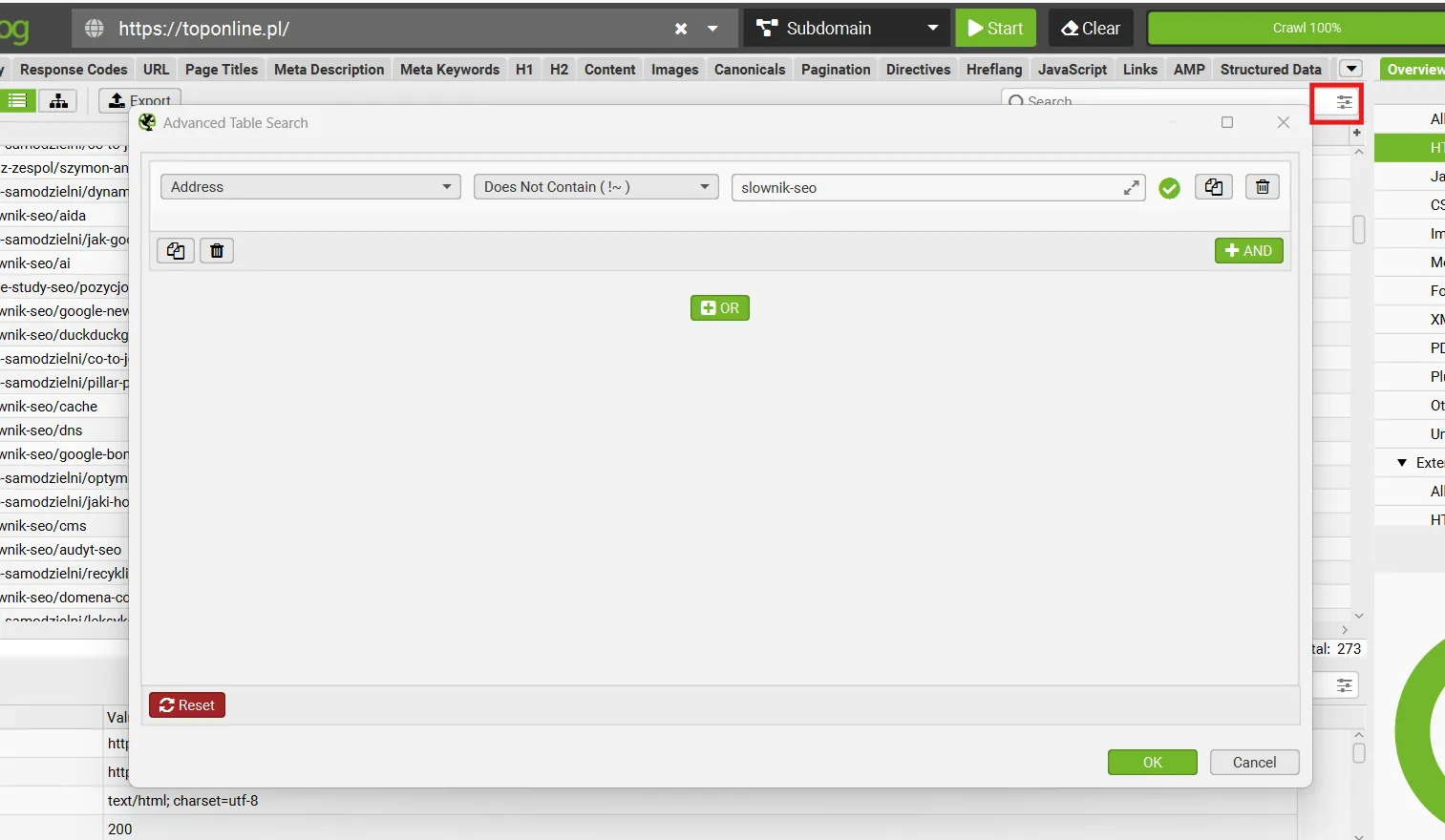
Za pomocą filtrów wyszukuję adresy bez uzupełnionego meta title oraz takie, które mają powielone tytuły (Duplicate).
Duplikaty często pojawiają się w przypadku paginacji – wtedy wystarczy poprawić schemat generowania meta title, np. dodając numer strony („Strona kategorii – Strona 2”).
Długość meta title też oczywiście ma znaczenie – jeśli jest za krótki, to dobra okazja, by go rozbudować i dodać najważniejszą frazę kluczową lub zachęcający tekst. Jeśli tytuł jest za długi – pojawia się ryzyko, że zostanie ucięty w wynikach wyszukiwania.
Z kolei w opisach (meta description) patrzę, czy są unikalne i czy sprawdzają się jako „teaser” treści. Brakujące lub powielone to sygnał, że warto się temu przyjrzeć dokładniej.
Opis sam w sobie nie jest czynnikiem rankingowym, ale mocno działa na CTR, więc lepiej go nie ignorować. Dla większych serwisów stosuję automatyczne schematy, ale strony kategorii opisuję ręcznie – często przy pomocy naszej asystentki AI YOSA.
Sprawdzanie nagłówków H1, H2
Każda podstrona powinna mieć jeden, konkretny H1. W Screaming Frog najczęściej korzystam z filtrów Duplicate, Multiple i Missing.

Duplikaty pojawiają się np. przy stronach produktów z różnymi wariantami. Warto też sprawdzić, czy brakujący H1 nie jest efektem działania CSS-a, który np. może pokazywać nagłówek w kodzie jako div.
W H2 zaglądam głównie po to, żeby zobaczyć, czy wspierają temat strony, nie powielają się i czy w ogóle pojawiają się w treści. Brak logicznej struktury nagłówków to dla mnie sygnał, że dana strona może wymagać lepszej optymalizacji pod kątem contentu.
Sprawdzenie jakości treści – zakładka Content
Tu szukam np. stron z Lorem Ipsum (czyli niedokończonych lub zapomnianych podstron), duplikatów (filtry Exact i Near Duplicates) oraz takich, które są po prostu puste.
Zduplikowane treści obniżają wartość całej strony, dlatego te dane bardzo się przydają w ustaleniu, co poprawić albo rozbudować.
Błędy techniczne strony
Sprawdzenie błędów technicznych to podstawa. Mogą one utrudniać robotom Google indeksowanie Twojej strony, a użytkownikom – korzystanie z niej.
Statusy HTTP
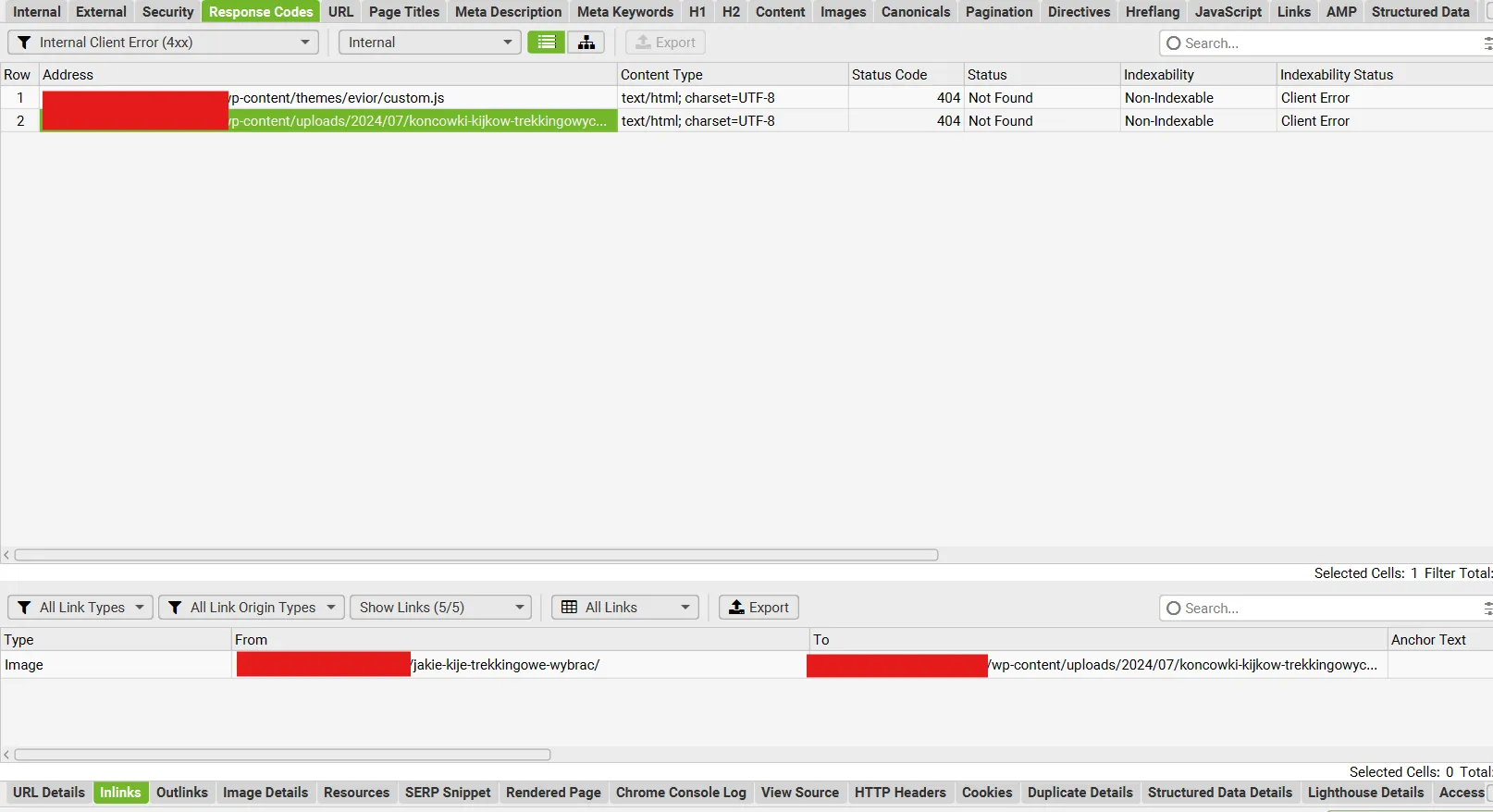
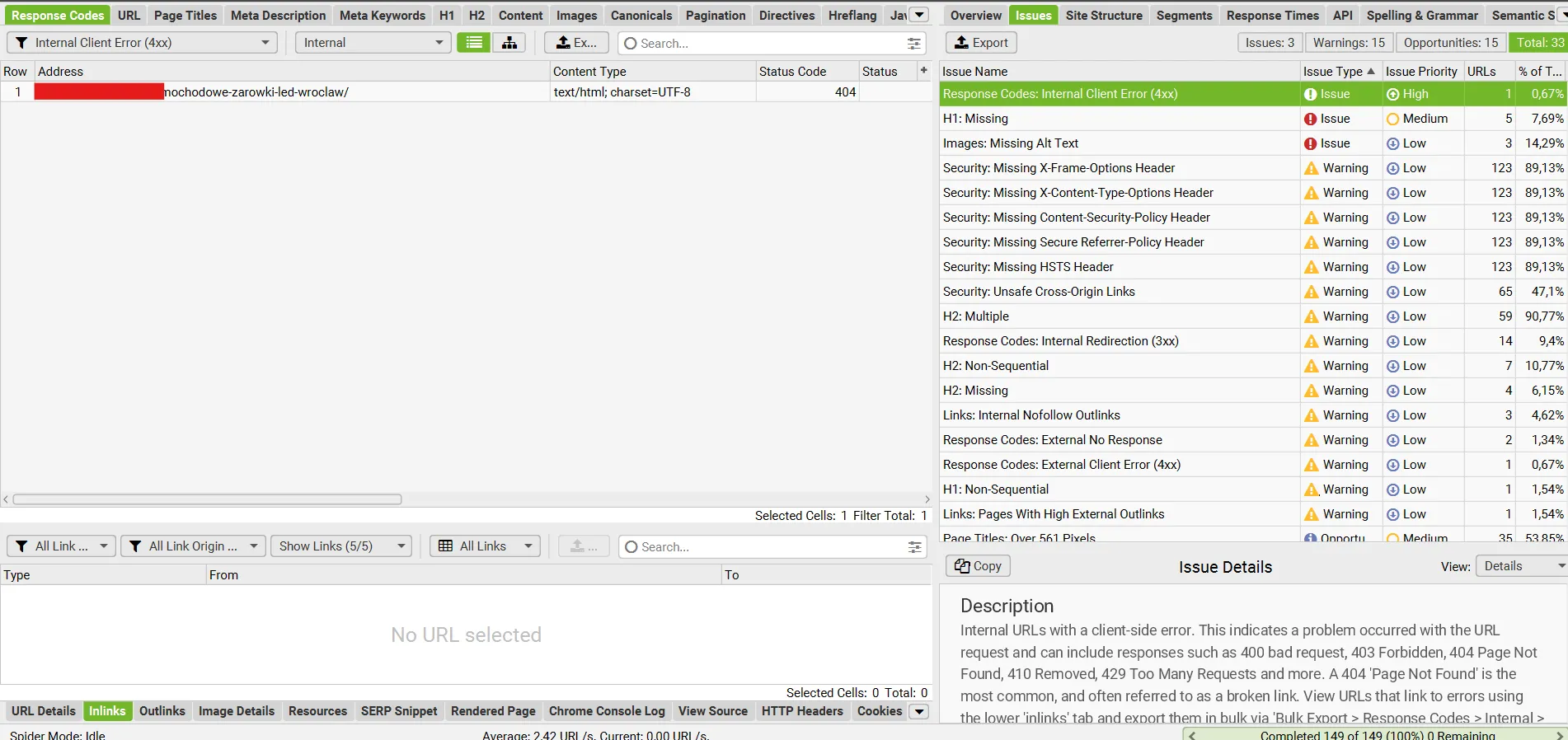
Na początek zaglądam do zakładki Response Codes i ustawiam filtr na Internal lub Internal Client Error. Szukam błędów 4xx, czyli głównie 404 – to strony, które nie istnieją, ale wciąż prowadzą do nich linki.
W dolnym panelu Inlinks mogę od razu sprawdzić, skąd te linki odsyłają i podmienić je w kodzie strony lub CMS-ie. Taka szybka naprawa często daje realny efekt w postaci poprawy widoczności i lepszego UX.
Przekierowania 301 – filtr Internal Redirect (3xx)
Następnie przechodzę do kontroli przekierowań – 301 i 302.
Podstrony powinny kierować na możliwie najbardziej zbliżone strony – na przykład na podobny produkt lub na kategorię, w której wcześniej się znajdowały.
Dodatkowo sprawdzam, które podstrony przekierowują bezpośrednio na stronę główną. Informację o tym znajdziesz w kolumnie Redirect URL.
Sortuję tę kolumnę rosnąco – od najmniejszej do największej – dzięki czemu adresy odsyłające na home page wyświetlają się jako pierwsze.
Szukam też wielokrotnych przekierowań oraz tzw. pętli przekierowań (Redirect Loop) – czyli błędnych konfiguracji, w których przekierowania prowadzą w nieskończoność (np. A → B → A). Taka sytuacja blokuje dostęp do treści zarówno dla użytkowników, jak i robotów wyszukiwarek.
No i jest jeszcze Meta Refresh – czyli tzw. odświeżanie meta, zamiast standardowego przekierowania 301 lub 302. To przestarzałe i nieprzyjazne rozwiązanie, więc jeśli się pojawia, od razu je usuwam.

Problemy z indeksowaniem – zakładka Directives
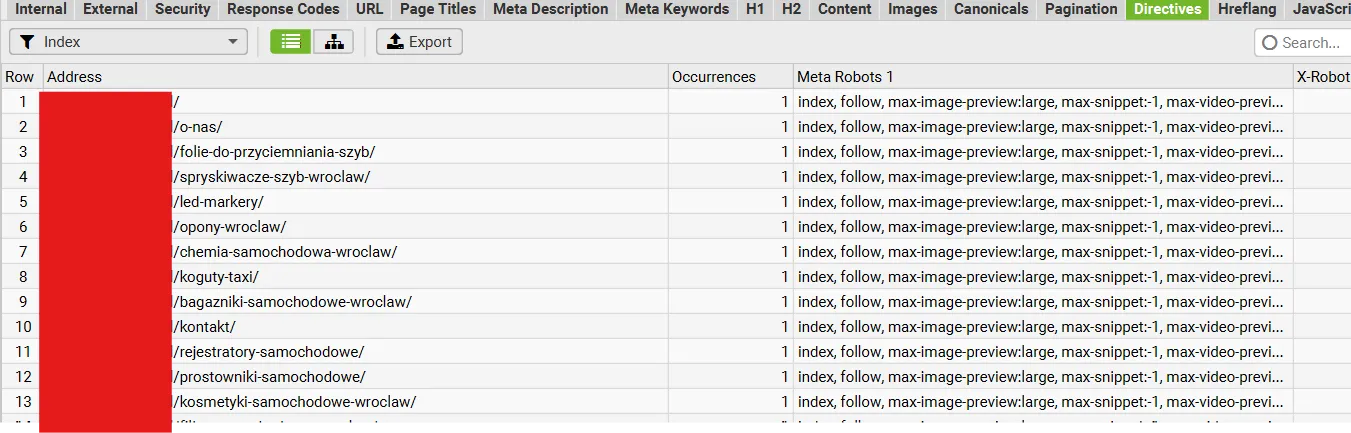
W tej zakładce sprawdzam, czy coś nie jest przypadkiem zablokowane przed robotami Google, np. tagiem meta noindex albo w pliku robots.txt.
Kiedyś standardowo wykluczało się regulaminy, polityki prywatności itd., ale dziś lepiej je zostawić – Google lubi transparentność. Warto też sprawdzić, czy wewnętrzne linki nie mają atrybutu nofollow. Jeśli mają, a prowadzą do istotnych podstron – zmieniam na follow.
Sprawdzenie adresów URL – zakładka URL
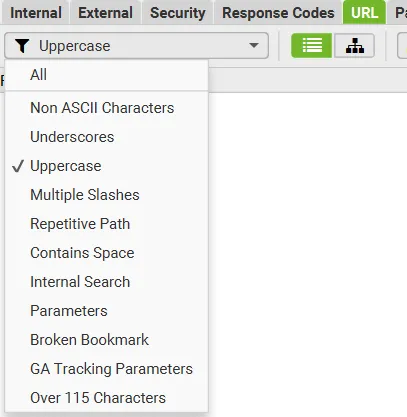
Tutaj analizuję strukturę adresów. Polskie znaki, wielkie litery, podkreślniki – wszystko to może wprowadzić bałagan i utrudnić ich prawidłowe odczytywanie. Adresy powinny być krótkie, czytelne i w miarę logiczne. Najlepiej, gdy składają się z małych liter i myślników (jako separatorów).
Jeśli dany CMS generuje różne wersje tych samych adresów (np. /Produkty/Kije i /produkty/kije, co w praktyce oznacza 2 różne adresy), warto zadbać o poprawne oznaczenia kanoniczne i ustawić przekierowania, żeby uniknąć kanibalizacji.
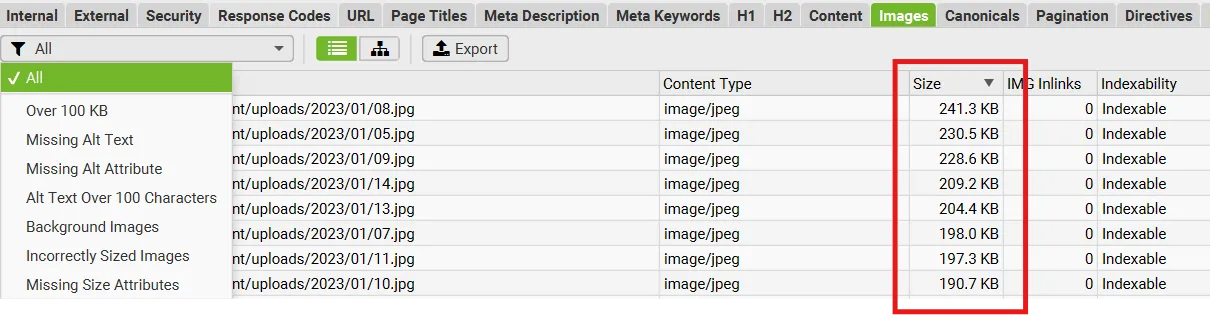
Sprawdzenie zdjęć – zakładka Images
Obrazki też potrafią napsuć krwi. Sprawdzam, czy mają atrybuty alt – jeśli nie, warto je dodać, szczególnie w sklepach i wpisach blogowych. Alt-y nie tylko wspierają SEO, ale też poprawiają dostępność strony.
Zerkam również na wagę plików – sortuję kolumnę Size i od razu widzę, które obrazy są za duże. Staram się, żeby pliki graficzne miały maksymalnie 150 KB. Jeśli widzę jpg-a ważącego >300 KB, to wiem, że strona może ładować się za wolno.
Sprawdzenie bezpieczeństwa – zakładka Security
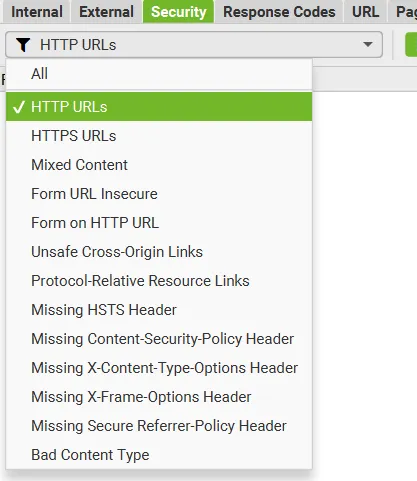
W tym miejscu patrzę, czy wszystko działa na HTTPS. Jeśli coś jeszcze funkcjonuje na HTTP, wrzucam przekierowanie.
Ważna rzecz: mixed content – czyli sytuacja, gdy strona jest na HTTPS, ale część zasobów (np. zdjęcia, skrypty) wczytuje się przez HTTP – to zła praktyka i trzeba to poprawić. Filtr Mixed Content w Screaming Frog pozwala to szybko wychwycić.
Sprawdzenie linków wychodzących – zakładka External
Na koniec zaglądam do linków wychodzących. Jeśli strona prowadzi do błędnych zewnętrznych adresów (np. 404 albo wygasłych domen), usuwam je lub podmieniam.
Linki przeglądam także pod kątem ich liczby – jeśli jedna podstrona ma kilkanaście linków wychodzących, zastanawiam się, czy na pewno wszystkie są potrzebne.
To szczególnie ważne w przypadku linków afiliacyjnych i sponsorowanych – warto mieć nad nimi kontrolę.
Sprawdzanie pozostałych błędów w Screaming Frog
Na koniec zaglądam do zakładki „Issues” w bocznym menu. Screaming Frog sam wykrywa najczęstsze problemy i sortuje je według typu. Dla mnie to świetne miejsce na szybki przegląd techniczny serwisu.
Niektóre błędy są oczywiste – np. brak meta title albo za duży rozmiar zdjęć. Inne wymagają chwili zastanowienia, bo dotyczą np. niespójności w canonicalach, pustych znaczników lub dziwnych przekierowań.
Przy każdym problemie mogę sprawdzić nie tylko jego nazwę, ale też krótkie wyjaśnienie, dlaczego to może być istotne (sekcja Issue Details). Fajne jest to, że narzędzie nadaje błędom priorytety – od krytycznych po mniej ważne – więc łatwiej zdecydować, czym zająć się w pierwszej kolejności.
Z tego raportu korzystam regularnie, nawet po zakończeniu audytu. To taki techniczny radar, który pozwala mi trzymać rękę na pulsie i wychwycić nowe błędy, zanim zauważy je klient albo Google.
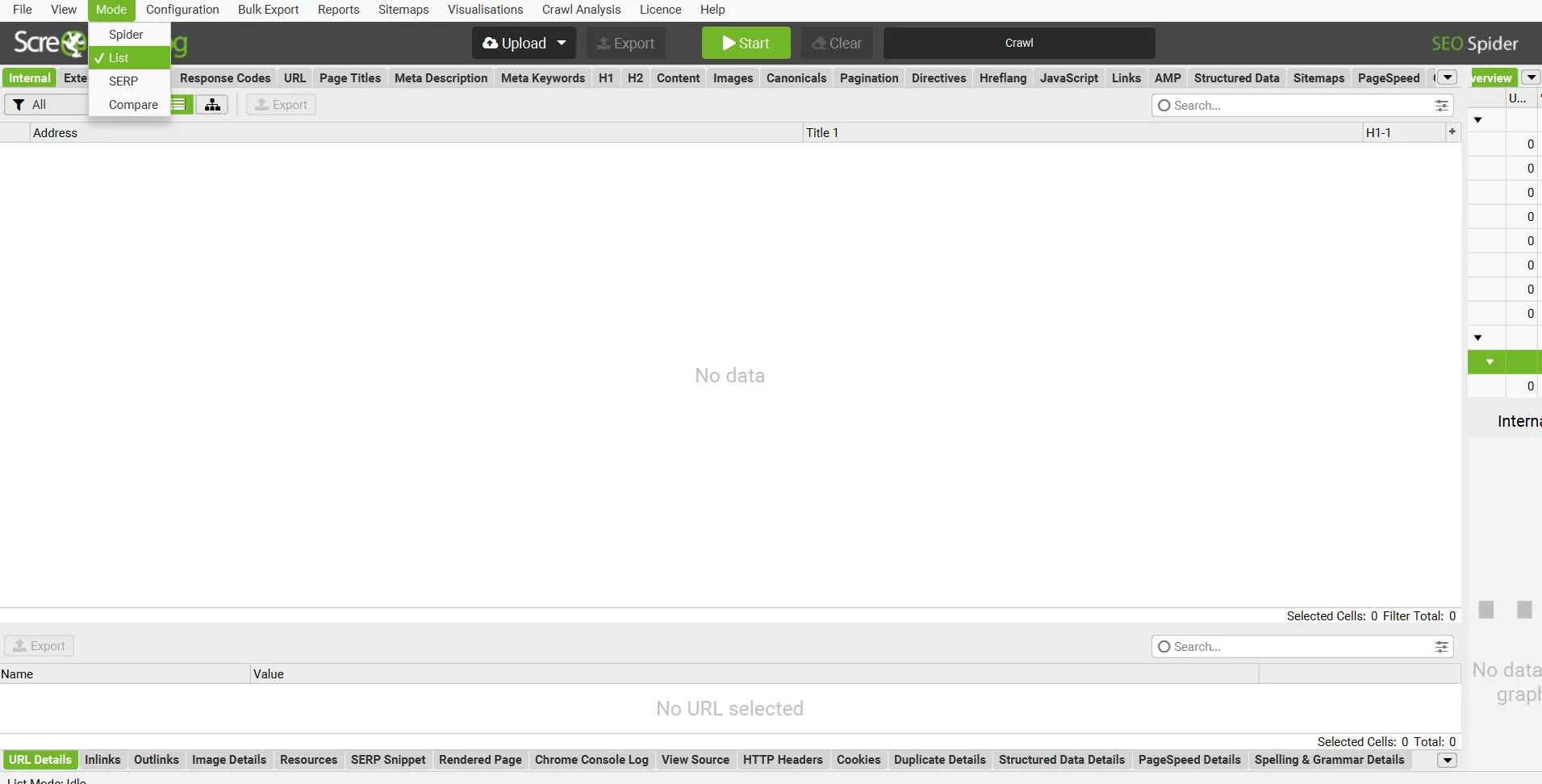
Tryb List, czyli jak obejść limit 500 adresów?
Darmowa wersja Screaming Frog ma limit 500 adresów, ale tryb List pomaga go obejść. W menu Mode wybieram List, klikam Upload i wklejam listę URL-i ręcznie. Można je wcześniej podzielić na paczki po 500 i analizować partiami.
A skąd brać adresy URL?
Pierwszą opcją jest Google Search Console, gdzie mogę znaleźć informację np. o niezaindeksowanych podstronach w obrębie witryny.
Drugim rozwiązaniem jest zaciągnięcie adresów bezpośrednio z mapy XML. Adres do mapy witryny znajdziesz zazwyczaj w pliku robots.txt.

Jeśli go tam nie ma, możesz sprawdzić sekcję Indeksowanie → Mapy witryn w Google Search Console.
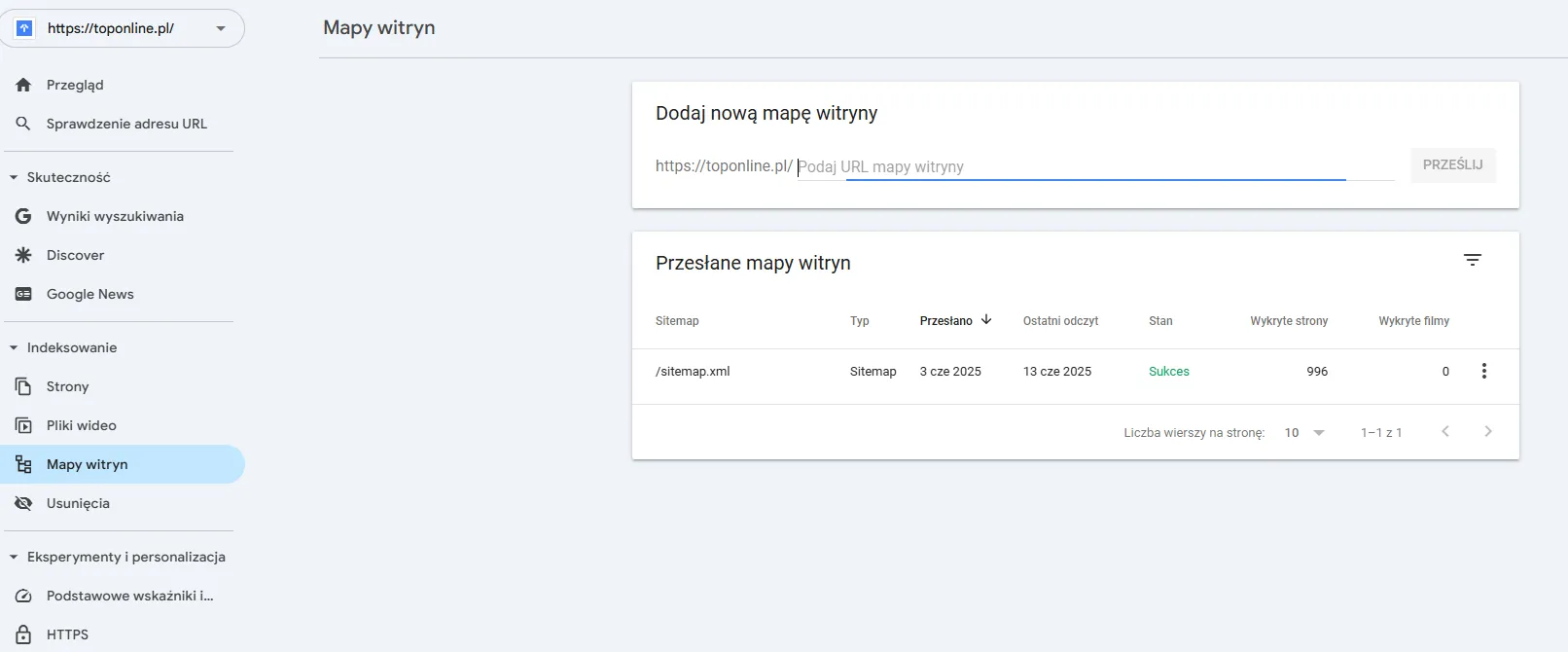
Pobierając adresy bezpośrednio z mapy witryny, pomijamy odwołania do plików .css i .js.
W przypadku rozbudowanych serwisów istnieje jednak duże prawdopodobieństwo, że mapa XML została podzielona na kilka sekcji – osobno dla różnych typów podstron takich jak wpisy blogowe, produkty, kategorie itd. Takie rozwiązanie jest często stosowane m.in. na platformie Shoper.
Wystarczy wtedy wkleić adres konkretnej podmapy w opcji Upload – Download Sitemap XML, aby pobrać wszystkie zawarte w niej adresy.
Podsumowanie
Screaming Frog to prawdziwy kombajn funkcjonalności, ale przy odrobinie wprawy i wiedzy da się go ujarzmić.
Najważniejsze to umieć wyciągnąć z SC to, co rzeczywiście ma wpływ na SEO. Narzędzie samo nie zrobi roboty, ale świetnie pokazuje, od czego warto zacząć.
- Screaming Frog to narzędzie SEO, które skanuje Twoją stronę jak robot Google i pokazuje, co warto poprawić.
- Instalacja jest szybka, a w darmowej wersji możesz skanować do 500 URL-i i korzystać z trybu Spider lub List.
- Po przeskanowaniu strony zaglądam do konkretnych zakładek, żeby wyciągnąć z narzędzia najważniejsze dla mnie informacje.
- SC pozwala mi sprawdzać, czy title i description są unikalne, mają odpowiednią długość i czy nie brakuje ich na żadnej podstronie.
- Mogę też w dowolnej chwili przeanalizować jakość treści w sekcji Content, a także skontrolować nagłówki H1 i H2.
- Najpierw usuwam błędy 404 i problemy z przekierowaniami 3xx, które psują indeksację i aspekty związane z UX-em.
- W zakładce Directives sprawdzam, czy istotne podstrony nie są zablokowane przez tag noindex lub plik robots.txt i wprowadzam poprawki, jeśli trzeba.
- Upewniam się, że adresy URL są krótkie, czytelne i nie zawierają błędnych znaków, wielkich liter czy podkreślników.
- Obrazki powinny mieć alt-y i ważyć możliwie jak najmniej – w zakładce Images wyłapuję te, które wymagają optymalizacji.
- W sekcji Security upewniam się, że wszystkie podstrony działają w oparciu o protokół HTTPS.
- Usuwam lub poprawiam niedziałające linki zewnętrzne i sprawdzam, czy nie ma ich za dużo w obrębie pojedynczej podstrony (sekcja External).
- Zakładka „Issues” pokazuje wszystkie problemy na stronie i pomaga ustalić, co trzeba poprawić w pierwszej kolejności.
- Jeśli strona ma więcej niż 500 URL-i, korzystam z trybu List i analizuję ją partiami, kopiując podstrony z mapy witryny lub danych z GSC.
Autor artykułu
![[object Object] - Top Online](https://cdn.toponlineapp.pl/5986-maciej-bednarski.png)
Maciej Bednarski
Maciek to doświadczony specjalista SEO, perfekcjonista w e-commerce. Dba o detale techniczne i UX. Po godzinach zdobywa Karkonosze i wspina się na ściance. Uwielbia trekking łączy pracę z górską pasją
![[object Object] - Top Online](https://cdn.toponlineapp.pl/7474-hubert.png)

![[object Object] - Top Online](https://cdn.toponlineapp.pl/7496-ola-mlodzinska.png)
