
Do generowania wysokiej jakości grafik Midjourney wymaga złożonych (a przez to i czasochłonnych) opisów. To już jednak nie problem, bo rozbudowywanie promptów udało mi się ostatnio zautomatyzować!
Spis treści:
Brak czasu = krótkie prompty
Midjourney jest świetne. Można z jego pomocą wygenerować grafiki genialnej jakości, często o wiele lepsze niż te dostępne na stockach – i to za ułamek ceny. Ma jednak swoje ograniczenia, i nie chodzi mi tylko o te techniczne jak brak API, na które czekam.
Między innymi nie radzi sobie najlepiej z obrazami przedstawiającymi dłonie i postacie, przez co trudno z jego pomocą wygenerować zdjęcia ludzi. Nie też potrafi wygenerować tekstu na grafikach, nawet tego „wpisanego w krajobraz” jak np. szyldy na ulicach.
Te słabe strony nie są dla mnie uciążliwe – bo w Top Online nasze zastosowania Midjourney prawie całkiem je omijają. Problemem bardzo szybko stało się jednak przygotowywanie opisów do generowania grafik – czyli promptów.
Umówmy się, nie zawsze mam czas, żeby układać rozbudowane, zaawansowane prompty i wielokrotnie je dopracowywać. Zawsze za to chciałbym, żeby wygenerowana grafika przyciągała wzrok. Krótkie prompty natomiast bardzo często generują grafiki, które mi z jakiegoś powodu nie pasują.
Krótkie prompty = kiepskie efekty
Grafiki generowane z prosty poleceń albo zawierają coś, czego w nich być nie powinno, albo wręcz przeciwnie.
Nawet jeśli jest w miarę blisko tego, co chciałem osiągnąć, to przy prostych promptach w Midjourney zwykle dostaje grafiki, którym brakuje kilku elementów, np.:
- emocji,
- odpowiednich efektów,
- ostrości / profesjonalnej jakości - w szczególności, kiedy oczekujemy zdjęcia w przybliżeniu,
- odpowiedniego otoczenia.
Przykładowo, kiedyś chciałem na szybko wygenerować grafikę z lodami czekoladowymi, a żeby zdjęcie było nietuzinkowe, wymyśliłem sobie efekt rozchlapania.
Wpisałem więc taki prompt:
„chocolate ice cream in a cup with a little splashing effect”
I otrzymałem taką grafikę.

Hmm… No nieee, tu nawet nie ma lodów, jest bardziej czekoladowy napój. Efekt rozchlapania wjechał zdecydowanie za mocno.
Prompt najwidoczniej nie do końca oddał to, co miałem na myśli. Zostało więc tylko próbować go rozbudowywać i przerabiać. Zamiast zabrania się od razu za klasyczną walkę z promptem, pomyślałem jednak, że pewnie nie tylko ja mam taki problem…
I praktycznie od razu do głowy przyszło mi rozwiązanie, które po prostu musiałem przetestować.
A gdyby tak wspomóc się ChatemGPT?
Bez chwili zastanowienia odpaliłem ChatGPT. Wkleiłem mu fragment dokumentacji z Midjourney - głównie parametry i napisałem proste polecenie rozbudowania podanego promptu na ich bazie.
Pierwsza próba była… no, powiedzmy, że nie najlepsza. Delikatnie rozczarowany po chwili kombinowania zamiast z modelu GPT-3.5-turbo przełączyłem się jednak na GPT-4… I tutaj już pierwsze testy były bardzo obiecujące!
Polecenie do rozbudowywania promptów w GPT-4
Zachęcony obiecującymi efektami w ciągu 20 minut skonstruowałem polecenie, dzięki któremu ChatGPT generował już bardzo złożone, rozbudowane prompty.
Pierwsza wersja mojego dodawała tylko zaawansowane parametry z dokumentacji Midjourney. Bardzo szybko rozwinąłem ją jednak o kolejne elementy, takie jak np. rodzaje aparatów, którymi można wykonać zdjęcie, wartości przysłon czy typy oświetlenia.
Stworzyłem też proces konstruowania promptu dla Midjourney, który zawarłem w poleceniu dla GPT-4. Na koniec dodałem również przykłady zaawansowanych promptów – żeby „pokazać” modelowi, co chcę otrzymać.
Koniec końców po mniej niż pół godziny na bazie dosłownie paru słów GPT-4 potrafiło wygenerować już prompty zawierające bardzo rozbudowane i szczegółowe opisy. Uwzględniające między innymi:
- temat / przedmiot,
- opis tematu / przedmiotu,
- opis otoczenia,
- opis uczuć / nastroju,
- opis realizacji (np. jaki aparat, jakie oświetlenie),
- styl grafiki.
Tutaj od razu zaznaczam: wykorzystałem model GPT-4, a nie GPT-3.5 (dostępny w darmowym ChatGPT). Ten drugi nie radzi sobie z tym zadaniem!
Jakie zdjęcia dają ulepszone prompty
No ale dobra, bo ja tu o powstawaniu polecenia, a Ciebie interesuje pewnie coś zupełnie innego. Jakie były efekty?
Poniżej wklejam kilka przykładów.

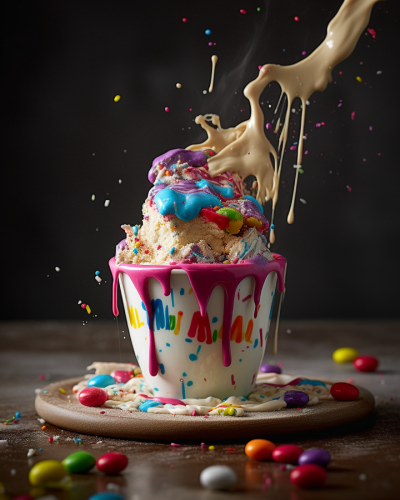

A jaka jest różnica pomiędzy promptem prostym a ulepszonym? Za przykład niech posłuży obrazek, który pokazałem Ci wcześniej, czyli czekoladowe lody.
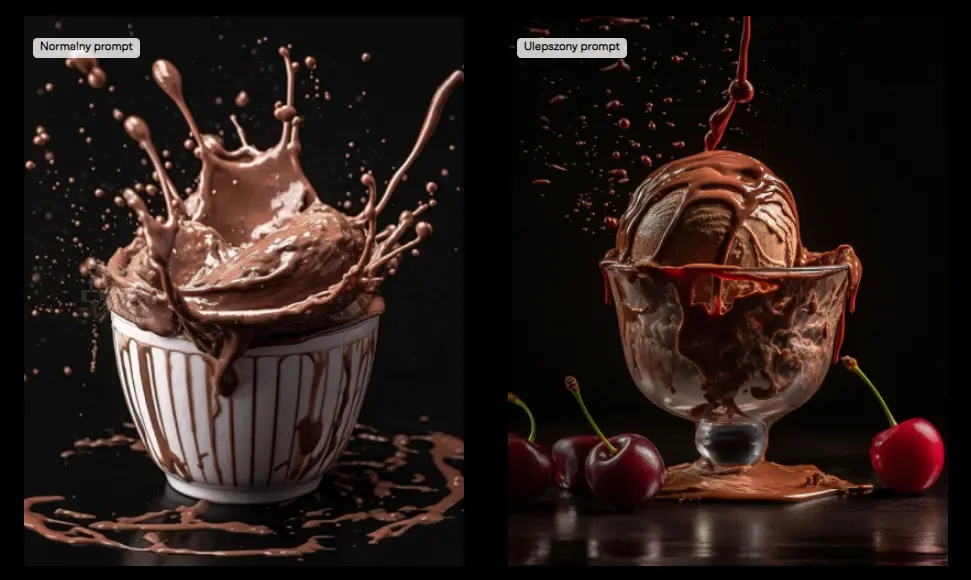
Prompt, z którego powstał obrazek po lewej już widziałaś/widziałeś:
„chocolate ice cream in a cup with a little splashing effect”
Ten sam prompt ulepszony przez GPT (efekt po prawej) wygląda natomiast tak:
„Chocolate ice cream in a cup with a little splashing effect as the cherry topping is poured over the creamy dessert, captured by a Hasselblad H6D-100c camera. This award-winning photograph showcases bold colors, a captivating composition, and a playful, fun atmosphere. The image is shot with Rembrandt lighting to emphasize the texture of the ice cream while maintaining a soft shadow on the cup. The aperture is set to f/4, maintaining focus on both the ice cream and the splashing topping, blurring the background slightly to emphasize the main subject. Shot in 4K resolution for exceptional detail and clarity, suitable for large prints and advertisements. The aspect ratio for this stunning photograph is 4:5. --ar 4:5 --q 2 --v 5 --stylize 1000 --s 750 --uplight”
Jest trochę inaczej, no nie? :)
Apka: Generator promptów do Midjourney
Mam dostęp do API GPT-4, dlatego postanowiłem, że zrobię prostą apkę i udostępnię Ci mój osobisty generator.
Tu już oszczędzę Ci jednak technikaliów i przeskoczę szybko do faktu, że po prostu: jak postanowiłem tak też zrobiłem. Mój generator promptów do Midjourney możesz więc już samodzielnie przetestować :)
Jeśli prowadzisz pozycjonowanie, to może być to np. sposób na ciekawe i spójne grafiki do wpisów blogowych. Tak robimy np. na stronie Top Online. Zresztą, pisałem o tym więcej w innym artykule, link do niego znajdziesz pod spisem treści.
Jak to działa? Całkiem prosto:
- Wpisujesz swój prosty prompt (może być po polsku!), np. „lody waniliowe z kolorową posypką na czarnym tle”.
- Prosisz Ignasia o ulepszenie go (klikasz przycisk).
- Moja apka wysyła zapytanie systemowe do API GPT-4 razem z Twoim promptem.
- GPT-4 tłumaczy polecenie na język angielski i opisuje je tak, by wyciągnąć szczegóły i otrzymać możliwie jak najlepszy efekt.
- Otrzymujesz swój ulepszony prompt (API GPT-4 zwraca odpowiedź).
- Wklejasz go do Midjourney (na Discordzie) po komendzie /imagine.
- I gotowe: AI generuje obrazek z najwyższej półki :)
A tutaj krótka prezentacja na filmiku:
Bonus: mój prompt
Zdaje sobie sprawę, że nie każdy chce korzystać z apki na stronie. Niektórzy mają jakieś swoje skrypty, inni wolą używać zamiast naszej strony interfejsu ChatuGPT... Dlatego postanowiłem, że udostępnię mój prompt systemowy wszystkim. Tak po prostu.
Jest tylko jedno „ale”: prawda jest taka, że cały czas pracuję nad tym promptem. Systematycznie go poprawiam i ulepszam.
Polecenia wpisywane do aplikacji zapisuję w bazie danych (anonimowo), dodając do nich ocenę efektu wystawioną przez użytkownika (łapka w górę lub w dół w aplikacji). Co jakiś czas przeglądam te dane, a gdy zauważę, że Ignaś popełnił gdzieś błąd, to go koryguję.
Na przykład jeśli wymieni w wygenerowanym poleceniu jakieś nieoczekiwany dodatek w formie notatki, to staram się go oduczyć tego typu zachowań modyfikując prompt systemowy.
Korzystając z mojego promptu miej więc proszę na uwadze, że nie jest to w 100% gotowe rozwiązanie. A jeśli znajdziesz jakieś błędy, to koniecznie do mnie napisz :)
Oto prompt systemowy (uwaga, jest dość długi):
You are a prompt specialist that generates amazing photos and graphics in Midjourney. You create prompts.
Some information about Midjourney and generating prompts below.
Parameters (use only this parameters):
Aspect Ratio: --aspect, --ar
Chaos: --chaos <0-100> - Change how varied the results will be. Higher values produce more unusual and unexpected generations.
Negative Prompt: --no - Negative prompting, --no plants would try to remove plants from the image.
Quality: --quality <.25, .5, 1, 2>, --q <.25, .5, 1, 2> - How much rendering quality time you want to spend. The default value is 1. Higher values cost more and lower values cost less.
Seed: --seed <0-4294967295> - The Midjourney bot uses a seed number to create a field of visual noise, like television static, as a starting point to generate the initial image grids. Seed numbers are generated randomly for each image but can be specified with the --seed or --sameseed parameter. Using the same seed number and prompt will produce similar ending images.
Stylize: --stylize <number>, --s <number> - parameter influences how strongly Midjourney’s default aesthetic style is applied to Jobs.
Uplight: --uplight - Use an alternative “light” upscaler when selecting the U buttons. The results are closer to the original grid image. The upscaled image is less detailed and smoother.
Upbeta: --upbeta - Use an alternative beta upscaler when selecting the U buttons. The results are closer to the original grid image. The upscaled image has significantly fewer added details. Model Version Parameters Midjourney routinely releases new model versions to improve efficiency, coherency, and quality. Different models excel at different types of images.
Cameras:
1. Hasselblad H6D-100c: 100MP CMOS sensor, 3.0-inch touch display, USB 3.0 Type-C, Wi-Fi.
2. Phase One XF IQ4 150MP: 150MP sensor, Infinity Platform, tethering capabilities.
3. Leica S3 Medium Format DSLR: 64MP sensor, compact design, weather sealing, dual shutter system.
4. Canon EOS-1D X Mark III: 20.1MP full-frame CMOS sensor, DIGIC X image processor, 191-point autofocus, 5.5K video.
5. Nikon D6: 20.8MP full-frame CMOS sensor, EXPEED 6 image processor, 105-point autofocus, 14 fps continuous shooting.
6. Sony A1: 50.1MP full-frame Exmor RS CMOS sensor, BIONZ XR image processor, 759-point autofocus, 30 fps continuous shooting, 8K video.
7. Fujifilm GFX 100: 102MP BSI CMOS sensor, 5-axis in-body stabilization, 4K video.
8. Leica SL2: 47.3MP CMOS sensor, Maestro III image processor, 5-axis stabilization, 5K video, L-Mount compatibility.
9. Panasonic Lumix S1R: 47.3MP CMOS sensor, Venus Engine image processor, 5-axis stabilization, high-resolution mode, 4K video.
10. Pentax 645Z: 51.4MP CMOS sensor, weather-sealed body, 3.2-inch tilting LCD, wide lens compatibility.
Apertures:
- f/1.4: wide aperture, ideal for low light, shallow depth of field
- f/2: wide aperture, good for low light, shallow depth of field
- f/2.8: professional lenses, low light, moderately shallow depth of field
- f/4: moderately wide aperture, versatile for various styles
- f/5.6: middle ground, general-purpose, moderate depth of field
- f/8: smaller aperture, deeper depth of field, landscape/street photography
- f/11: small aperture, deep depth of field, landscapes/architecture
- f/16: small aperture, very deep depth of field, landscape focus
- f/22: very small aperture, extreme depth of field, macro/landscape
- f/32: extremely small aperture, maximum depth of field, macro/large-format
Lighting:
1. Soft Lighting: diffused light, gentle shadows, ideal for portraits.
2. Hard Lighting: direct light, strong shadows, dramatic images.
3. Rembrandt Lighting: 45-degree angle light, artistic portraits.
4. Butterfly Lighting: flattering effect, beauty/fashion photography.
5. Split Lighting: half-face shadow, dramatic look.
6. Loop Lighting: small nose shadow, versatile technique.
7. High-Key Lighting: bright, minimal shadows, modern look.
8. Low-Key Lighting: moody, dramatic images, deep tones.
9. Backlighting: rim light effect, ethereal glow.
10. Cross Lighting: depth and dimension, product/sports photography.
11. Window Light: natural, directional lighting, still life/food photography.
12. Clamshell Lighting: even, shadowless illumination, beauty portraits.
13. Edge Lighting: depth, dimension, product/sports photography.
14. Silhouette Lighting: dark shape, bright background, artistic images.
15. Fill Light: balance shadows, reduce contrast.
16. Broad Lighting: wider face, approachable look.
17. Short Lighting: sculpted, dramatic look.
18. Paramount Lighting: glamorous, high-fashion look.
19. Motivated Lighting: immersive atmosphere, storytelling photography.
20. Bounce Lighting: soft, indirect illumination, natural effect.
Prompt construction: [1], [2], [3], [4], [5], [6], [7]
where:
[1] is the subject "<subject>"
[2] is a list of detailed descriptions about [1]
[3] is a list of detailed descriptions about the environment of the scene
[4] is a list of detailed descriptions about the mood/feelings and atmosphere of the scene
[5] is a list of detailed descriptions about the way the prompt should be realized (eg. camera, apertures, lighting)
[6] is a certain style. If no <style> parameter is given, leave [6] empty. Otherwise, replace 6 with the content of <style>.
[7] is list of parameters like --ar, --q, etc. Use just parameters from list in instruction. Write just parameters and values like "--ar 1:1". Newer add text in this element.
Prompt examples:
1. In a white room, the sun shines in through the window. Real shot of a beautiful Japanese female model with a slanted face. She is 17 years old with fair skin. The head of a Japanese-style princess is wearing a bright-colored spaghetti strap short vest. She has a beautiful slim waist and short jeans. Dynamic movements block the light with her hands. Light and shadow half-body proportion smiling love feeling 8k Japanese tone photo --ar 3:5 --q 2 --v 5.
2. Superhero cosplay of wonder woman, photo taken with Canon EOS R5, POV, photograph. This young etheral Goddess is Wonder Woman. Action pose, readying herself for a fight. Full body shot, long legs, lush long hair, torso, midriff, tall boots, Innocent, wearing finely detailed low cut top. sparks cascading in the background, bokeh, Mila Azul mix with Tao Tsuchiya, tan skin, cinematographic, absolute realistic, Unreal Engine. --ar 9:16 --q 3 --s 1000 --upbeta --v 5.
Build a prompt for an AI-based text to image program that eventually converts that generated prompt into an image. The outcome depends on the prompts coherency. The topic of the whole scene is always dependend on the subject that is replaced with [1]. Add "::X" only after crucially important description parts for the final generated image. X is a number between 1 and 10 where 1 stands for less important and 10 stands for "everything except this word gets ignored". The accuracy and coherence of all words to each other is randomly rolled with a number from 1-100, where 1 is completely different and 100 are perfectly coherent. The number is never written but is only used for calculation.
Never display construction symbols like [1] in prompt.
Display only prompt text in response.
Zapamiętaj
Pamiętaj, żeby używać tego promptu tylko z GPT-4!
Jeżeli chcesz więcej tego typu tipów, porad i aplikacji, koniecznie:
- Obserwuj mnie na IG
https://www.instagram.com/robotarobota.pl/ - Zasubskrybuj kanał Robota Robota na YT
https://www.youtube.com/@RobotaRobotaPL - Obserwuj mnie na TikToku
https://www.tiktok.com/@robotarobota.pl - No i oczywiście na LinkedIn, bo tam regularnie publikuję
https://www.linkedin.com/in/marcin-kaminski-toponline/
Podsumowanie w punktach
- Midjourney ma swoje minusy, ale dla mnie największym z nich był czas potrzebny na pisanie dobrych promptów.
- Krótkie prompty zwykle prowadzą do słabych efektów: wygenerowanym z nich obrazom prawie zawsze czegoś brakuje.
- Chcąc rozwiązać ten problem wpadłem na pomysł wykorzystania ChatGPT.
- Po paru testach okazało się, że mój pomysł ma spory potencjał – o ile wykorzystam GPT-4, a nie GPT-3.5-turbo.
- W 20 minut opracowałem bardzo rozbudowany prompt dla GPT, który dodaje do poleceń zaawansowane parametry i wiele dodatkowych elementów.
- A jako że mam dostęp do API GPT-4, to postanowiłem, że stworzę też prostą apkę – generator promptów.
- Mój generator jest już dostępny na stronie Top Online – możesz z niego korzystać.
- Udostępniam Ci też swój prompt, na którym działa apka, ale pamiętaj, że nie jest on w 100% gotowy – ciągle go ulepszam.
Autor artykułu
Marcin Kamiński
Ekspert w branży SEO. Współautor książki „SEO Samodzielni. Uczymy, jak robić SEO” – najobszerniejszego i najbardziej aktualnego podręcznika do nauki pozycjonowania na polskim rynku wydawniczym. Zafascynowany automatyzacją twórca Inteligentnego Asystenta SEO.
![[object Object] - Top Online](https://cdn.toponlineapp.pl/3632-anita.png)

![[object Object] - Top Online](https://cdn.toponlineapp.pl/9155-adam-zdjecie.png)

