
Zespół Google DeepMind pracuje nad nowym modelem BlockRank ulepszającym analizowanie treści przez LLM-y. Zalecenia od Google dot. weryfikacji dostawców hostingu chmurowego w Search Console. Pierwsze testy asystenta głosowego Gemini for Home. Oprócz tego: funkcja “What’s happening” w profilach firmowych Google, badanie Ahrefsa, Grokipedia już zaindeksowana, a także nowy user-agent powiązany z Chrome Web Store.
1. Model BlockRank od Google DeepMind
Zespół Google DeepMind zaprezentował nowy model o nazwie BlockRank, który może w przyszłości całkowicie zmienić sposób, w jaki sztuczna inteligencja ocenia i porządkuje informacje.
Technologia ma rozwiązać jeden z kluczowych problemów współczesnych modeli językowych – wolne i kosztowne analizowanie dużych zbiorów danych w kontekście zapytania użytkownika (ICR, czyli In-context Ranking).
Do tej pory modele takie jak GPT czy Gemini porównywały każde słowo w dokumencie do innego słowa (w procesie tzw. attention) – co prowadziło do dużego obciążenia obliczeniowego.
BlockRank upraszcza ten proces, sprawiając, że dokumenty są w pewnym sensie izolowane – ich wewnętrzne relacje między sobą nie są analizowane. Z kolei model zapytania ma dostęp do wszystkich dokumentów i porównuje je w odniesieniu do wspólnego kontekstu.
Dzięki temu system działa znacznie szybciej i skuteczniej – w testach DeepMind był nawet 4,7 razy szybszy od tradycyjnych rozwiązań i potrafił ocenić 500 dokumentów w sekundę.
Wyniki porównań pokazują, że BlockRank nie tylko przyspiesza działanie modeli, ale też zachowuje lub przewyższa jakość rankingową w porównaniu z dotychczasowymi metodami.
Jeśli technologia zostanie wdrożona w usługach Google (a jest na to spora szansa), może to wpłynąć na sposób, w jaki systemy AI wybierają i prezentują treści – od wyników organicznych po odpowiedzi generatywne.
Więcej informacji o modelu BlockRank znajdziecie tutaj: Scalable In-context Ranking with Generative Models.
2. Google zaleca weryfikację dostawcy hostingu w chmurze za pomocą Search Console
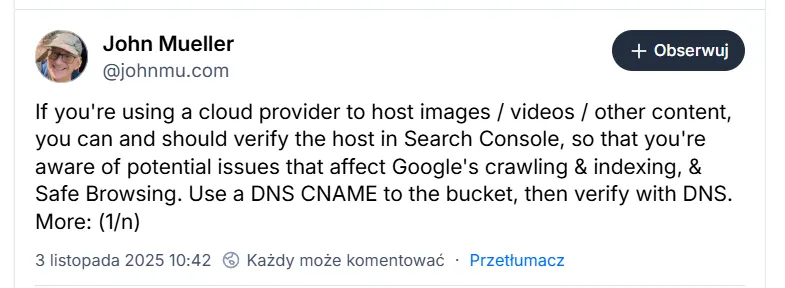
Google przypomina właścicielom stron, by weryfikowali swoich dostawców hostingu chmurowego w GSC. Jak wyjaśnił John Mueller, to szczególnie ważne dla firm, które przechowują obrazy, wideo lub inne pliki poza własną domeną – np. w usługach takich jak AWS, Google Cloud czy Azure.
Dzięki takiej weryfikacji właściciel strony zyskuje pełen wgląd w sposób, w jaki Google widzi i indeksuje jego zasoby. Można monitorować błędy crawlowania, alerty bezpieczeństwa oraz wydajność hostowanych plików.
Bez tego część treści – mimo że dostępna dla użytkowników – może pozostać niewidoczna dla wyszukiwarki.
Google zaleca, by w takich przypadkach skonfigurować rekord CNAME w ustawieniach DNS swojej domeny, tak aby wskazywał on na zewnętrzny zasób chmurowy.
W praktyce oznacza to utworzenie subdomeny, np. content.twojadomena.com, która będzie przekierowywać na konkretny kontener w chmurze – a następnie dodanie jej jako osobnej usługi w Search Console.
Taka konfiguracja sprawia, że wszystkie pliki przechowywane w chmurze – obrazy, filmy, dokumenty, arkusze czy pliki PDF – są technicznie powiązane z konkretną domeną, a nie z obcym adresem URL dostawcy. Dla Google to sygnał, że zasoby należą do tej samej witryny, co strona główna, dzięki czemu mogą być analizowane i raportowane w jednym miejscu.
To prosty, ale często pomijany krok, który może poprawić indeksowanie multimediów, bezpieczeństwo strony i spójność danych SEO.
3. Niektórzy użytkownicy mogą już testować asystenta głosowego Gemini for Home
W USA rozpoczęły się testy nowego asystenta głosowego Gemini for Home, opartego na modelu językowym Gemini.
To pierwsze podejście Google do stworzenia w pełni konwersacyjnego asystenta domowego, który potrafi prowadzić naturalny dialog z użytkownikiem – nie tylko wykonywać proste komendy.
Gemini for Home ma rozszerzyć możliwości klasycznego Asystenta Google. Zamiast prostych poleceń typu „włącz światło” czy „zagraj piosenkę X”, użytkownicy mogą z nim rozmawiać w bardziej naturalny sposób, np. pytać o plan dnia, przepisy, informacje z sieci czy osobiste rekomendacje.
Program działa na urządzeniach z serii Google Home i Nest – od pierwszych modeli po nowsze wersje Hub i Audio. Użytkownicy mogą zgłaszać chęć udziału w testach poprzez aplikację Google Home, a dostęp na razie obejmuje jedynie język angielski i rynek amerykański.
Globalne wdrożenie planowane jest na 2026 rok.
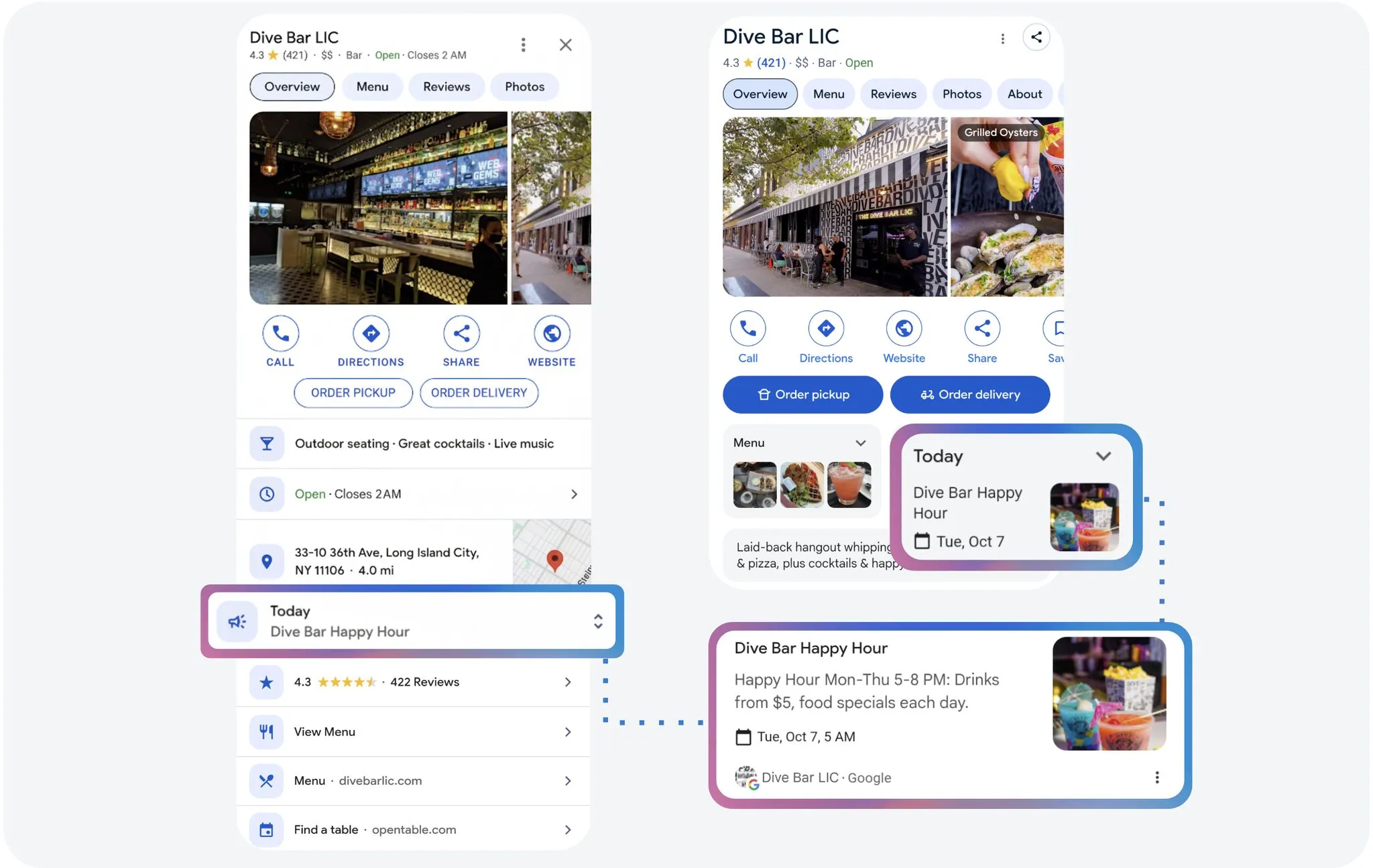
4. Funkcja “What’s happening” w profilach firmowych Google zostaje rozbudowana
Google ogłosiło rozszerzenie funkcji “What’s happening” w profilach GMF. Od teraz mogą z niej korzystać nie tylko pojedyncze lokale gastronomiczne, ale także sieci restauracji i barów z wieloma lokalizacjami – jednak na razie tylko w USA, Wielkiej Brytanii, Kanadzie, Australii i Nowej Zelandii.
Opcja pozwala właścicielom firm publikować na swoim profilu informacje o bieżących wydarzeniach, promocjach czy specjalnych ofertach – na przykład „Happy Hour” czy tematycznych wieczorach.
Dzięki temu użytkownicy, którzy szukają miejsca w okolicy, mogą zobaczyć aktualne atrakcje lub oferty w danym lokalu, zanim odwiedzą stronę internetową.
Google podkreśla, że testy funkcji przyniosły bardzo dobre wyniki i zapowiada jej stopniowe rozszerzanie na kolejne branże i kraje.
Dla restauratorów to szansa na zwiększenie widoczności w lokalnych wynikach wyszukiwania i skuteczniejsze przyciąganie klientów w czasie rzeczywistym.
5. 67% źródeł cytowanych przez ChatGPT jest poza zasięgiem marketerów – wyniki analizy Ahrefs
Jak pokazuje najnowsza analiza Ahrefs, większość stron, na które powołuje się ChatGPT, to treści praktycznie niedostępne dla działań marketingowych.
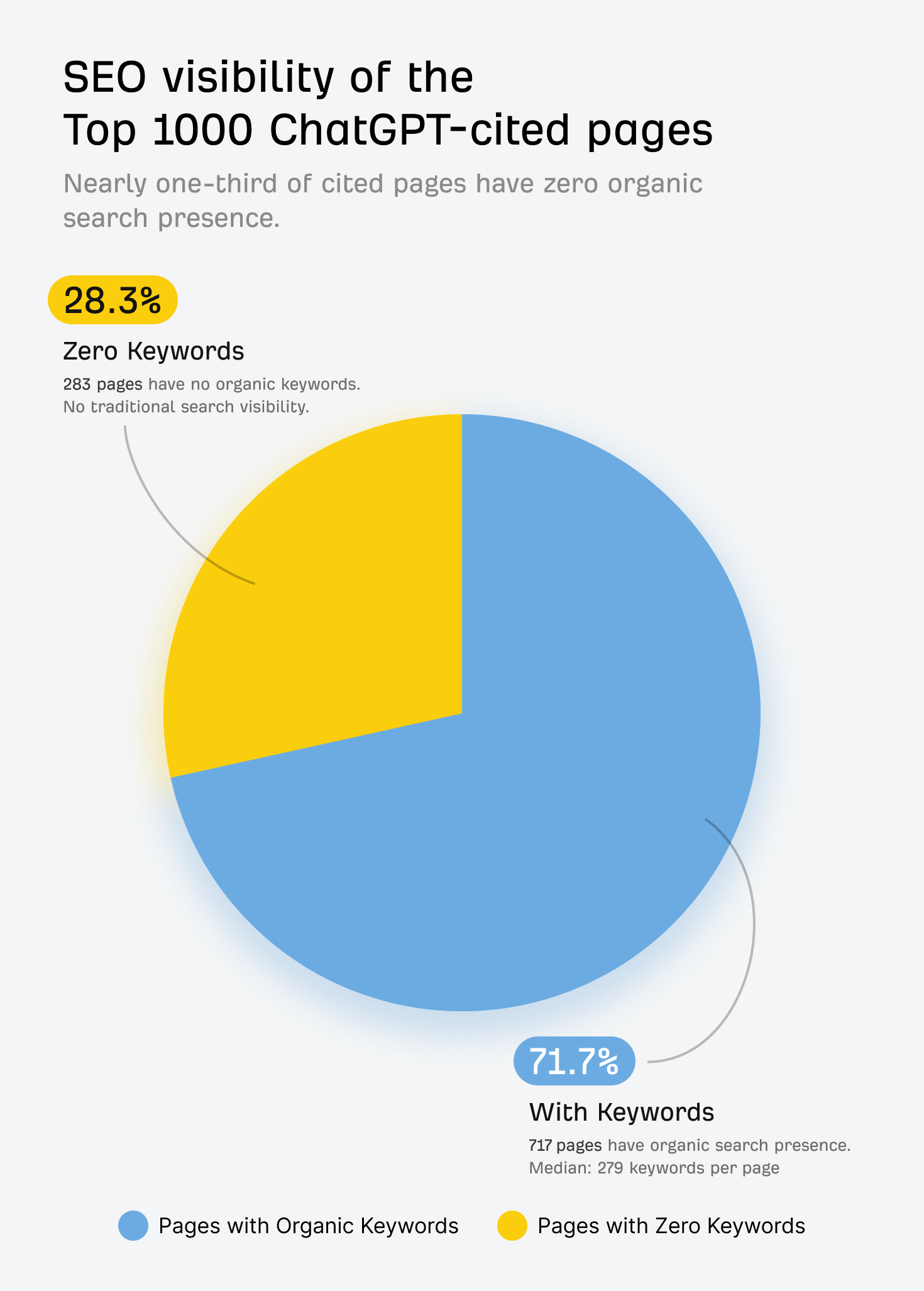
Spośród tysiąca najczęściej cytowanych źródeł aż 67% pochodzi z miejsc, na które specjaliści od pozycjonowania i marketerzy nie mają wpływu – takich jak Wikipedia, strony główne firm czy sklep z aplikacjami App Store.

Badanie przeprowadzono z wykorzystaniem narzędzia Brand Radar, które śledzi źródła cytowane przez LLM-y. Wychodzi na to, że tylko około jedna trzecia cytowań pochodzi z treści, na które mogą „wpływać” twórcy – głównie ze stron edukacyjnych, recenzji i blogów.

To oznacza, że klasyczne działania SEO czy content marketing nie zawsze przekładają się na obecność w odpowiedziach generowanych przez AI.
Ciekawe jest również to, że 28% cytowanych stron w ogóle nie ma widoczności organicznej w Google. ChatGPT czerpie więc wiedzę także z treści, które nie pojawiają się w klasycznych wynikach wyszukiwania.
Wśród cytowanych źródeł przeważają strony o bardzo wysokim autorytecie domeny (DR ok. 90), choć często są to podstrony o słabym profilu linków.
Pełne badanie możecie sprawdzić pod tym linkiem: 67% of ChatGPT’s Top 1,000 Citations Are Off-Limits to Marketers (+ More Findings).
A tutaj znajdziecie inne analizy Ahrefsa, które opisywałem w ramach SEO Newsów:
6. Grokipedia pojawiła się w indeksie Google oraz Bing
Niedawno w sieci pojawił się nowy projekt o nazwie Grokipedia – sztucznie generowana encyklopedia, która w zaledwie kilka dni od uruchomienia trafiła do indeksów Google i Binga.

Serwis wystartował 27 października 2025 r. i już w wersji 0.1 obejmuje ponad 885 tys. stron tworzonych w całości przez sztuczną inteligencję.
Wyszukiwarki bardzo szybko zaczęły indeksować zawartość nowego projektu – Google pokazywał już kilkaset wyników „site:grokipedia.com” po tygodniu od startu. Podobne dane odnotowano w Bing.
Tak szybka indeksacja wywołała (całkiem słusznie wg mnie) dość burzliwą dyskusję w środowisku SEO. No bo z jednej strony Google wszędzie przypomina o karach dla witryn, które masowo publikują treści generowane przez AI – a mimo to Grokipedia pojawiła się w wynikach bez przeszkód, i to praktycznie od razu.
Wygląda na to, że algorytmy odpowiedzialne za wykrywanie “scaled abuse content” działają dość wybiórczo.
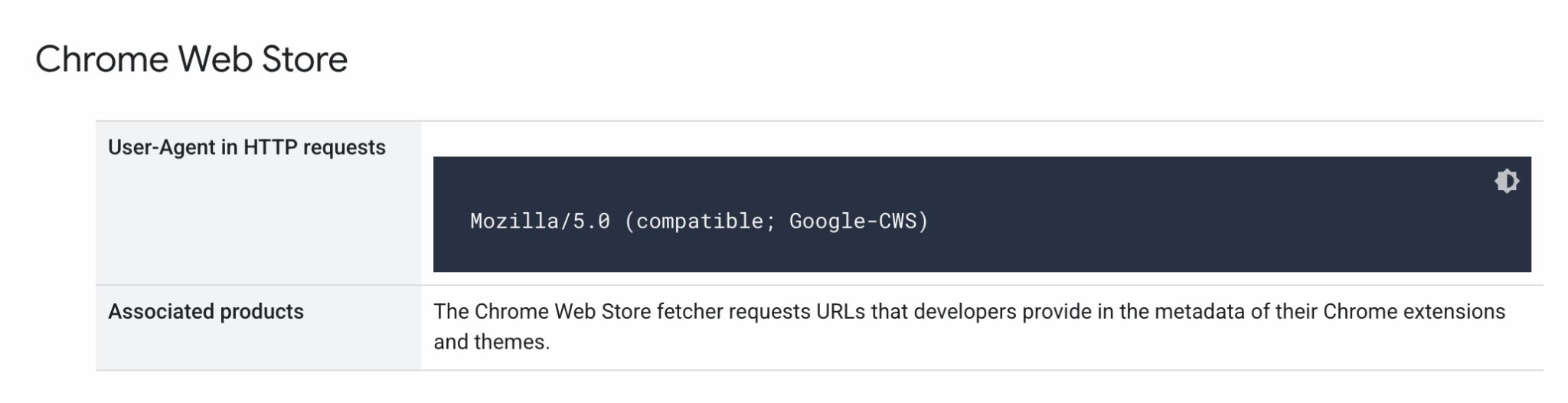
7. Google dodaje user-agenta powiązanego z Chrome Web Store
Google dodało do swojej listy oficjalnych crawlerów nowego user-agenta o nazwie „Google-CWS”, który jest odpowiedzialny za pobieranie informacji z metadanych rozszerzeń i motywów dostępnych w Chrome Web Store.
Nowy bot ma pomagać w analizowaniu i aktualizowaniu informacji o rozszerzeniach bezpośrednio z adresów URL wskazanych przez ich twórców.
Co istotne, Google-CWS należy do grupy tzw. user-triggered fetchers – czyli procesów pobierania inicjowanych przez działania użytkowników w produktach Google, a nie przez standardowe crawlery indeksujące strony w wyszukiwarce.
Oznacza to, że w niektórych przypadkach ten bot może nie respektować zasad określonych w pliku robots.txt, ponieważ jego zapytania wynikają z faktycznych akcji użytkownika (np. przeglądania lub instalowania rozszerzenia).
Autor artykułu
Szymon Anioł
Szymon tworzy SEO Newsy i redaguje artykuły ekspertów na naszym blogu. Pisanie do internetu to dla niego czysta frajda, zwłaszcza gdy może wykazać się kreatywnością. Interesuje się neuro- i psychomarketingiem. Po godzinach miłośnik dobrej muzyki, filmów i podróży.


