
Przedstawiamy drugie badanie korelacji czynników zewnętrznych z pozycjami w wyszukiwarce. Drugie, bo pierwsze, obejmujące 100 tys. stron, wykazało m.in. że ilość linków nie ma bezpośredniego wpływu na pozycję (jeśli nie widziałeś – link znajdziesz pod spisem treści). A co wynikło z tego? Odpowiedzi poniżej!
Spis treści:
1. Po co drugie badanie, skoro pierwsze pokazało brak korelacji?
Nasze pierwsze badanie nie wykazało praktycznie żadnych korelacji liniowych.
To oznaczałoby, że stare metody pozycjonowania (często bardzo kosztowne, takie jak linkowanie zewnętrzne) mogą być już totalnie nieopłacalne — wbrew temu co twierdzi duża część specjalistów.
Nie chcieliśmy jednak popełnić błędu. Dlatego zweryfikowaliśmy nasze badanie na dwa sposoby:
- Sprawdziliśmy oczywiste wnioski (np. że im więcej fraz na wysokich pozycjach, tym większy całkowity ruch)
- … No i wykonaliśmy dodatkowe badanie.
Widzisz, brak korelacji liniowej... nie oznacza całkowitego braku korelacji!
Pierwsze badanie sprawdzało tylko korelację liniową Pearsona, a zależności pomiędzy czynnikami mogą być też nieliniowe.
A poza tym, zrobiliśmy je głównie po to, żeby sprawdzić, czy możemy zbudować model przewidujący, czy zmiana danego czynnika da nam gwarancję lepszej pozycji w Google.
Wnioski nie był pod tym kątem zbyt optymistyczne, ale Kacper (nasz programista od Machine Learningu) twierdził, że nie przekreślają one jeszcze szans na stworzenie modelu... Dlatego właśnie zrobiliśmy drugie badanie :)
W końcu, skoro większość branży nadal wydaje mnóstwo pieniędzy na kupowanie linków zewnętrznych to może faktycznie coś przeoczyliśmy?
2. Cel i metodologia
Zależności nieliniowe można sprawdzać na różne sposoby, m.in. za pomocą drzew decyzyjnych i wielomianowych sieci neuronowych.
My, na potrzeby stworzenia modelu, chcieliśmy najpierw sprawdzić, czy dane tworzą jakieś krzywe albo skupiska (klastry). Gdyby tak było, wskazywałoby to, że warto sięgnąć po kolejne metody i tworzyć model.
Co dokładnie zrobiliśmy?
- Wzięliśmy ten sam zbiór danych co w pierwszym badaniu (100 tysięcy wyników organicznych — po 100 wyników dla 1000 różnych fraz z różnych branż),
- … oraz te same czynniki, takie jak liczba linków zewnętrznych, czas ładowania strony, wielkość plików, częstotliwość słów kluczowych czy jakość meta description.
- Za pomocą funkcji pairplot (która przedstawia relacje między parami zmiennych) z biblioteki Seaborn utworzyliśmy wizualizację danych.
- Stworzyliśmy wykresy punktowe pokazujące relacje między parami zmiennych.
Dodatkowo, strony z pozycją w TOP10 zaznaczyliśmy na pomarańczowo, dla lepszej czytelności. Ułatwiło to analizę wpływu innych zmiennych na pozycję strony oraz ocenę możliwości stworzenia modelu AI.
Na koniec, dla pewności, nasz programista opracował na podstawie tych danych model Random Forest (który opiera się na wykorzystaniu wielu drzew decyzyjnych).
Czynniki wykorzystane w badaniu
competition— konkurencyjność badanego słowa kluczowego,competition_index— konkurencyjność badanego słowa kluczowego na podstawie zajętych slotów reklamowych,search_volume— potencjał słowa kluczowego (liczba zapytań miesięcznie),cpc— cost per click badanego słowa kluczowego,rank_group— pozycja zajmowana przez stronę w wyszukiwarce na badane słowo kluczowe,organic_count— liczba zindeksowanych podstron serwisu, którego pozycja była badana,visibility_top_10/50— widoczność serwisu w TOP10/50 (liczba fraz, na które widać stronę w danym przedziale pozycji),backlinks— liczba linków zewnętrznych przychodzących do domeny,referring_pages— liczba podstron odsyłających od domeny za pomocą linków zewnętrznych,referring_domains— liczba domen i subdomen odsyłających do domeny za pomocą linków zewnętrznych,referring_main_domains— liczba domen odsyłających do domeny,dofollow_ratio— proporcja linków przychodzących oznaczonych jako rel=dofollow do tych oznaczonych jako rel=nofollow,etv— szacowany ruch organiczny w całej domenie,domain_age_seconds— wiek domeny w sekundach (data pobrania minus data rejestracji w DNS),onpage_score— ocena ogólnej optymalizacji technicznej podstrony, na którą składają się meta tagi, atrybuty ALT, linki kanoniczne itd.,top_10— oznaczenie czy badana strona zajmuję pozycję w TOP10 na frazie (w tym badaniu, czynnik ten pominęliśmy, bo nie przyjmuje on wartości innych niż 0/1, więc nie można mówić w jego przypadku o korelacjach nieliniowych).
3. Dlaczego badamy zależności nieliniowe?
Gdy w pierwszym badaniu sprawdzaliśmy korelację liniową, szukaliśmy prostych zależności typu "im więcej X, tym lepiej/gorzej Y". Życie nie zawsze jest jednak takie proste, prawda? Szczególnie w SEO.
To dlatego chcieliśmy prześledzić zależności nieliniowe.
Hipotetycznie zależności takie mogą występować na przykład w linkowaniu. Jeśli np. dodawanie kolejnych linków daje dobre efekty, ale w pewnym momencie nie daje już ich prawie wcale — wtedy mamy do czynienia właśnie z korelacją nieliniową.
…albo gdy nowa domena ma pod górkę z budowaniem widoczności, ale po jakimś czasie efekt ten się osłabia i jej wiek nie ma już później większego znaczenia (zależność między danymi jest na początku, ale w pewnym momencie znika i już się nie pojawia).
I to właśnie takich sytuacji, w postaci "krzywych" i "progów" szukaliśmy w drugim badaniu.
4. Wyniki badania
Tak przedstawia się wizualizacja danych:

Co na niej widać?
- Pomarańczowe kropki to strony znajdujące się w TOP10 na badanych frazach,
- Niebieskie kropki to pozostałe wyniki,
- Każda kropka to jedna strona (w praktyce, jest to wiele kropek “na sobie”).
A co można z tego wyczytać?
W skrócie — dane nie wykazały żadnych wyraźnych zależności.
Pomarańczowe kropki są rozrzucone dość przypadkowo między niebieskimi.
Nie tworzą ani ładnych krzywych, ani wyraźnych skupisk. To sugeruje, że stworzenie skutecznego modelu AI na podstawie tych danych będzie bardzo trudne.
Jedyne skupiska jakie widać w wizualizacji, to te w osiach, w których porównujemy pozycję (rank_group) z innymi cechami (co jest logiczne).
Przykładowo, na zaznaczonym poniżej wykresie zestawione są pozycje zajmowane przez badane strony (oś X) oraz ogólna ocena optymalizacji (oś Y):
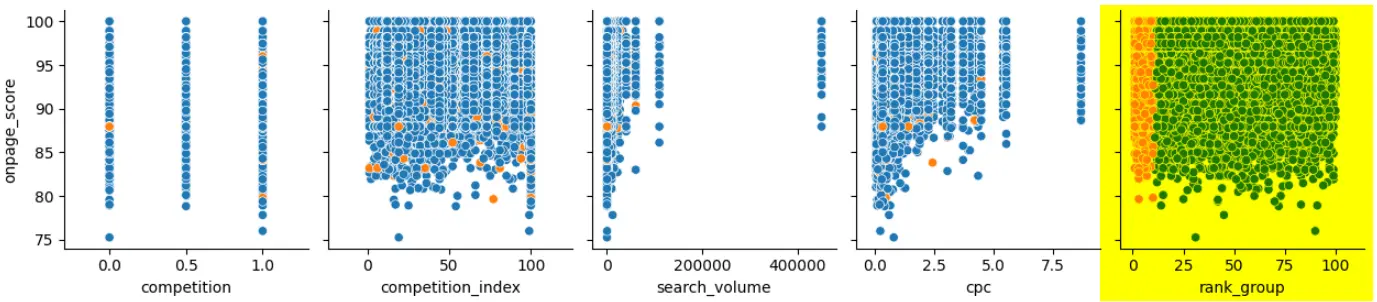
Skupisko pomarańczowych punktów pojawia się tutaj, bo strony zaznaczone na pomarańczowo, to właśnie te, które są w TOP10 (pomiędzy 0, a 10 na osi) — a to jest jedna z porównywanych cech.
Jak widać, w TOP10 praktycznie nie ma serwisów o ocenie niższej niż 80, ale są już te, które przyjmują dowolne wartości powyżej 80.

5. Wnioski
W ramach wniosków, porównaliśmy wykresy zależności nieliniowych dla tych samych danych z wnioskami z poprzedniego badania.
1. Domeny o dużej widoczności mają dużo backlinków, ale nie przedkłada się to na pozycje pojedynczych stron.
Pierwsze badanie wykazało, że domeny o większej widoczności mają zwykle więcej linków przychodzących, ale liczba ta nie ma nic wspólnego z obecnością pojedynczych stron w TOP10.
Wizualizacja danych potwierdziła z kolei, że faktycznie, widoczność (liczba fraz w TOP10 czy TOP50) wiąże się z rosnącą liczbą linków (choć nie jest to zależność 1:1):
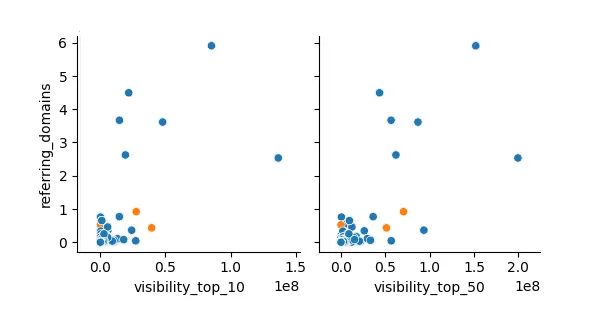
Pokazała też, tak samo jak pierwsze badanie, że same linki nijak nie wiążą się z zajmowanymi pozycjami:
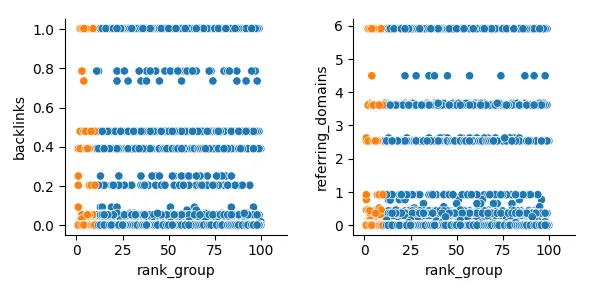
W przebadanych wynikach w TOP10 pojawiały się równomiernie zarówno strony kompletnie bez linków zwrotnych, jak i te o największej ich liczbie w całym zbiorze.
Tak samo było w przypadku ilości domen linkujących do serwisu (referring_domains).
2. Wiek domeny nie oddziałuje na pozycję
Pierwsze badanie pokazało, że wiek domeny nie wpływa bezpośrednio na jej pozycję.
Wizualizacja danych to potwierdza. Rozkład serwisów w zestawieniu z wiekiem domen jest praktycznie losowy, a w TOP10 są zarówno domeny ledwie założone, jak i istniejące od wielu lat.
U góry wykresu widać też, że najstarsze z domen, które znalazły się w badaniu, rzadko pojawiają się w TOP10 (co jest logiczne, bo najstarsze domeny to często serwisy, które są przestarzałe, od dawna nie aktualizowane i nie optymalizowane).
3. Większa konkurencyjność frazy nie sprawia, że strony w wynikach mają więcej backlinków.
Pierwsze badanie pokazało, że pomiędzy liczbą backlinków, a konkurencyjnością fraz nie ma praktycznie żadnej korelacji.
Wizualizacja danych w tym badaniu tylko to potwierdziła:
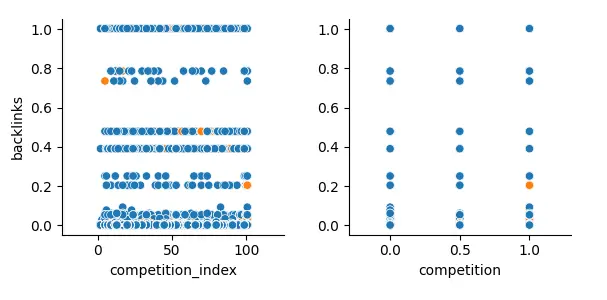
Rozkład pomarańczowych kropek nie tworzy krzywej ani klastrów (skupisk), co sugeruje, że zmienne nie są powiązane.
Mówiąc inaczej, drugie badanie potwierdza tezę z pierwszego.
Same linki zewnętrzne nie są dla Google sygnałem mówiącym o autorytecie czy wiarygodności serwisu, a fakt pozycjonowania na bardziej konkurencyjną frazę wcale nie oznacza, że trzeba pozyskać ich więcej czy mniej.
4. Liczba domen odsyłających nie świadczy o “jakości” linków zwrotnych.
Korelacje liniowe z pierwszego badania sugerowały brak istotnego wpływu liczby domen odsyłających (domen, które linkują do strony) na pozycję.
Wizualizacja tylko to potwiedziła:
Serwisy zajmujące pozycje w TOP10 są rozrzucone po praktycznie całej skali liczby linkujących do nich domen.
Na pierwszych dziesięciu pozycjach znalazły się zarówno strony, do których nie kierowały żadne zewnętrzne domeny (bez backlinków), jak i te, do których linkowało ich najwięcej.
5. Rosnący stosunek linków dofollow do nofollow również nie wiąże się z rosnącą pozycją.
W pierwszym badaniu wyciągnęliśmy wniosek, mówiący, że stosunek linków dofollow do linków nofollow nie ma żadnego związku z rosnącą pozycją. Tutaj znowu — mamy potwierdzenie.
W tym wypadku nie trzeba chyba komentarza, rozkład stron jest kompletnie losowy, co widać na pierwszy rzut oka:
6. Sama optymalizacja techniczna nie jest powiązana ze wzrostem pozycji.
Pierwsze badanie wykazało, że sama optymalizacja techniczna to za mało, żeby skutecznie pozycjonować strony (co jest logiczne, bo jej elementy są coraz częściej zautomatyzowane w CMS-ach i same w sobie nie stanowią wartości dla użytkownika).
Wizualizacja potwierdza nasz wniosek:
Dodatkowo, na wykresie doskonale widać to, o czym wspominaliśmy już poprzednio. Poniżej ogólnej oceny optymalizacji na poziomie 80/100 praktycznie nie ma już serwisów — bo mało która strona ma dzisiaj kompletnie niezadbaną optymalizację.
7. Większy potencjał frazy nie zawsze oznacza większą konkurencyjność.
Ten zaskakujący na pierwszy rzut oka wniosek z poprzedniego badania okazał się trafiony także tutaj.
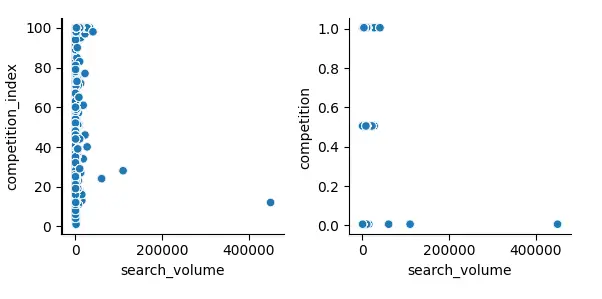
W lewym górnym rogu pierwszego wykresu znalazło się nieco więcej punktów “wystających” w prawo — co podpowiada, że faktycznie, w wielu przypadkach większy potencjał to także większa konkurencyjność.
Sam rozkład poniżej jest już jednak raczej równomierny (choć nie za dobrze niewidoczny najlepiej przez dużą skalę — w badaniu pojawiło się kilka fraz o ogromnym potencjale, co zaburzyło przejrzystość tego wykresu).
To oznacza, że tak jak przypuszczaliśmy już poprzednio, dla fraz o potencjale rzędu 100-5000 konkurencyjność wcale nie wzrasta równomiernie.
Często fraza o potencjale 500 zapytań na miesiąc może być tak samo konkurencyjna jak fraza o potencjale 50 zapytań (i na odwrót).
Szczególnie, jeśli weźmiemy pod uwagę przekrój wszystkiego, co ludzie wpisują w Google, a nie tylko najczęściej wybierane w SEO frazy sprzedażowe dotyczące produktów.
8. Im więcej fraz na wysokich pozycjach, tym większy całkowity ruch.
Ten wniosek to oczywistość, stworzyliśmy go w pierwszym badaniu, żeby zweryfikować i pokazać poprawność danych. Umieszczamy go więc i tutaj.
Wizualizacja pokazała, że zależność ta jest nieco rozproszona, ale faktycznie występuje (co też jest logiczne, bo przecież wysokie pozycje można mieć np. tylko na frazy rzadko wyszukiwane, o bardzo niskim potencjale).
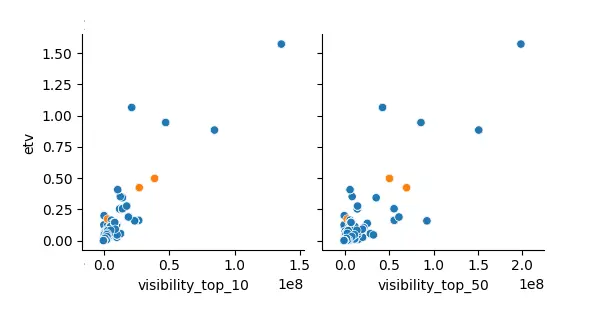
W tym przypadku wizualizację zaburzyły nieco największe serwisy, które znalazły się w badaniu (które zawyżyły skalę widoczności i całkowitego ruchu). Mimo to, zależność ciągle jest widoczna.
9. Im większy serwis tym większy przewidywany ruch i większa widoczność.
Ten wniosek z pierwszego badania również miał na celu potwierdzić poprawność danych, i tak też stało się w przypadku wizualizacji:
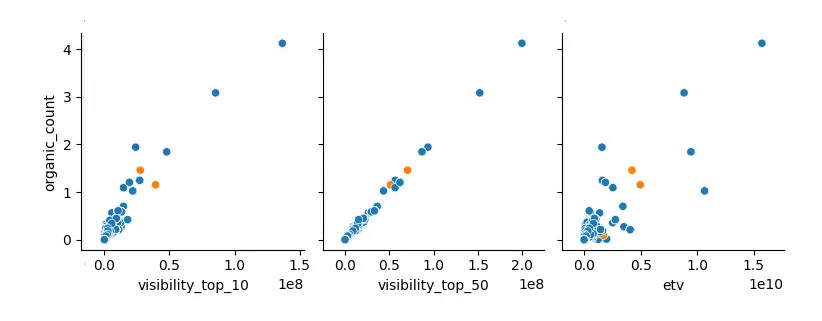
Na wykresach wyraźnie widać, że w miarę rosnącej liczby zindeksowanych stron (organic_count) rośnie widoczność (visibility_top_10/50).
Bardziej rozproszony (choć ciągle wskazujący na zależność) jest za to wykres przewidywanego ruchu organicznego (etv).
Potwierdza to jednak tylko zgodność danych z rzeczywistością, bo właśnie tak działa pozycjonowanie.
Więcej podstron = większa widoczność = większy ruch (o ile dobrze dobierzemy frazy i nie wypozycjonujemy się na słowa, które są rzadko wyszukiwane — stąd rozproszenie punktów na ostatnim wykresie).
6. Co nam to mówi?
- Co najważniejsze — drugie badanie potwierdza wnioski z pierwszego (przeczytasz je tutaj).
- Między czynnikami zewnętrznymi a pozycjami nie występują wyraźne korelacje.
- Już wiemy, że raczej nie zrobimy modelu AI przewidującego pozycje…
Raczej nie oznaczało jednak jeszcze kompletnego braku szans.
Przy tak dużym zbiorze danych (100 tysięcy wyników) sama wizualizacja danych na wykresach to często za mało. Po prostu, trudno zauważyć subtelne wzorce czy bardziej złożone zależności między wieloma czynnikami, patrząc tylko na wykresy punktowe.
To dlatego, dla absolutnej pewności, postanowiliśmy sięgnąć jeszcze dodatkowo po bardziej zaawansowane narzędzie — algorytm uczenia maszynowego Random Forest, który potrafi wykrywać nieoczywiste wzorce w danych.
7. Analiza danych za pomocą modelu AI
Korzystając z tych samych danych, nasz programista ML przygotował model AI, który miał za zadanie przewidzieć, czy strona znajdzie się w TOP10 na podstawie wszystkich zbadanych przez nas czynników.
Jego skuteczność w testach wyniosła około 85%.
Czy to dobrze?
Niestety nie, po bliższym przyjrzeniu się wynikom szybko okazało się, że model zupełnie sobie nie poradził.
Dlaczego, skoro osiągnął aż 85% skuteczności?
To proste — wystarczy zrozumieć strukturę danych.
W danych tylko 10% stron jest w TOP10 (w końcu to tylko pierwsze 10 pozycji na 100 wyników), a to oznacza, że model mógłby osiągnąć 90% skuteczności... po prostu zawsze zgadując, że strona nie jest w TOP10.
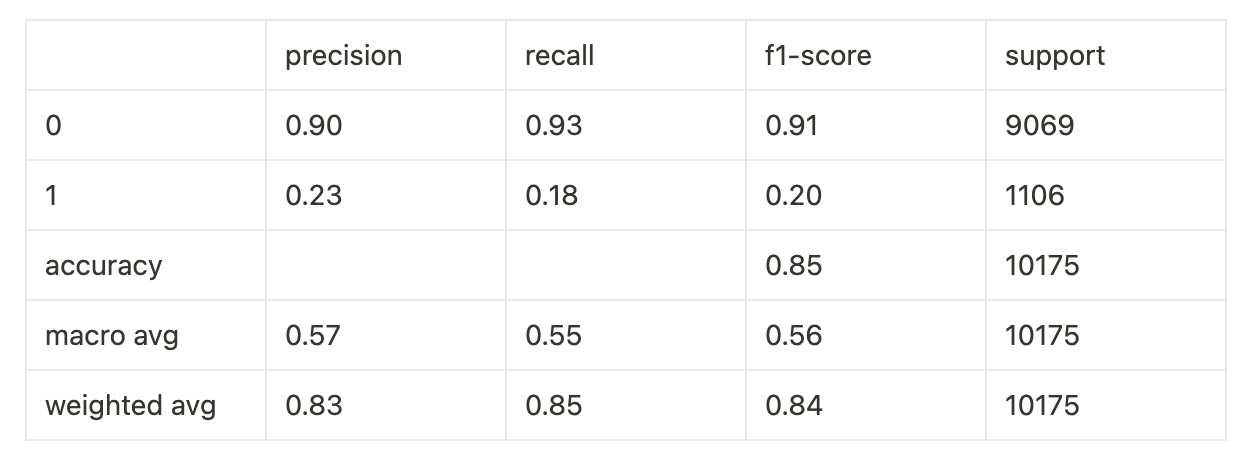
Widać to lepiej w dokładniejszych testach:
Classification Report (raport klasyfikacji):
Confusion matrix (macierz pomyłek):

W skrócie wynika z nich, że:
- Spośród stron, które model przewidział jako będące w TOP10, tylko 23% faktycznie tam było (precision dla cechy 1 = 0.23).
- Model potrafił wykryć zaledwie 18% stron, które rzeczywiście znajdowały się w TOP10 (recall dla cechy 1 = 0.18).
Mówiąc prościej — nasz model AI działał niewiele lepiej niż rzut monetą.
Oczywiście, próbowaliśmy jeszcze różnych sztuczek i balansowania danych (tak, żeby było w nich tyle samo wyników w TOP10, co tych poza TOP10), ale nic nie pomogło.
To kolejny dowód na to, że nie da się wskazać żadnych prostych kombinacji pojedynczych czynników, które wpływają na pozycję w Google.
8. Co dalej?
Można by powiedzieć, że temat zamknięty… ale spokojnie, to nie koniec badań!
Po publikacji pierwszych analiz spotkaliśmy się z opiniami, że "spoko, spoko, ale w niektórych branżach te czynniki na pewno mają znaczenie". Na przykład w e-commerce albo w branży medycznej (YMYL).
No to sprawdzimy... i damy Wam znać, co wyszło.
Może faktycznie w różnych branżach jest inaczej? W końcu czasem faktycznie…
…no dobra, nie gdybajmy, i tak się przecież dowiemy.
Do zobaczenia niebawem! :)
Podsumowanie w punktach
- Zrobiliśmy drugie badanie tych samych 100 tysięcy wyników Google, bo pierwsze (pokazujące brak korelacji liniowej) nie oznaczało kompletnego braku zależności.
- Tym razem szukaliśmy zależności nieliniowych, bardziej skomplikowanych — może coś działa, ale nie w prosty sposób?
- Niestety, tutaj również nie znaleźliśmy żadnego wyraźnego wpływu pojedynczych czynników zewnętrznych (takich jak linki czy wiek domeny) na pozycje.
- Do analizy wykorzystaliśmy też dodatkowo model AI (Random Forest), ale mimo wielu podejść i prób, jego skuteczność była porównywalna do rzutu monetą.
- To potwierdza wnioski z pierwszego badania — nie da się zagwarantować pozycji w Google na podstawie jednego czy kilku prostych czynników.
- Ale to jeszcze nie koniec — w kolejnym badaniu sprawdzimy, czy zależności te nie występują przypadkiem tylko w pojedynczych branżach lub dla pojedynczych kategorii fraz (np. e-commerce, YMYL).
Autorzy artykułu
Marcin Kamiński
Ekspert w branży SEO. Współautor książki „SEO Samodzielni. Uczymy, jak robić SEO” – najobszerniejszego i najbardziej aktualnego podręcznika do nauki pozycjonowania na polskim rynku wydawniczym. Zafascynowany automatyzacją twórca Inteligentnego Asystenta SEO.
Adam Przybyłowicz
Product Lead i specjalista od researchu i rozwoju w Top Online. Zdobywa dla nas wiedzę, szuka nowych rozwiązań i pracuje nad tym, żebyśmy nie zostali w tyle. Prowadzi zespół tworzący m.in. YOSA.AI.
![[object Object] - Top Online](https://cdn.toponlineapp.pl/5986-maciej-bednarski.png)

![[object Object] - Top Online](https://cdn.toponlineapp.pl/7474-hubert.png)

![[object Object] - Top Online](https://cdn.toponlineapp.pl/7496-ola-mlodzinska.png)
