
Linki kanoniczne to dwa w jednym: adresy, które Google uznaje za najodpowiedniejsze do pokazania spośród wszystkich podobnych treści oraz specjalne znaczniki, które pomagają wyszukiwarce w tej ocenie. Stosowanie ich na stronie nie jest obowiązkowe, ale pomaga zabezpieczyć się przed duplikacją i kanibalizacją. Tym samym: może znacznie wspomóc skuteczność SEO.
W tej części SEO Samodzielnych wyjaśniamy, czym jest kanoniczny adres URL - dla Google i pod pozycjonowanie. Pokazujemy, jak audytować i wdrażać linki kanoniczne oraz kiedy i gdzie to tak właściwie robić. Wyjaśniamy różnice pomiędzy teorią i praktyką, oraz przedstawiamy nasze sprawdzone rozwiązania.
Spis treści:
- Czym są linki kanoniczne?
- Jak umieścić link kanoniczny na stronie?
- Kiedy stosujemy linki kanoniczne?
- Na jakich stronach umieszczamy linki kanoniczne?
- Jak Google ustala kanoniczny adres URL?
- Jak sprawdzić kanoniczny adres URL danej strony?
- Jak audytować linki kanoniczne?
- Dobre praktyki wokół linków kanonicznych
- Czy kanoniczny URL przekazuje “moc rankingową”?
- Link kanoniczny, przekierowanie czy “noindex”?
- Kanoniczny URL Twojej strony w social media
- Podsumowanie
Czym są linki kanoniczne?
Dokumentacja Google mówi, że linki kanoniczne (a właściwie kanoniczne URL-e) są adresami stron, które wyszukiwarka uznaje za “najbardziej reprezentatywne” w zbiorze duplikatów. Taka jest podstawowa definicja tego pojęcia - dość prosta zresztą do zrozumienia.
Jeśli na co najmniej dwóch stronach występuje powielony content, to Google zawsze wybierze sobie spośród nich tylko jedną, a właściwie jeden adres. To on będzie właśnie kanoniczny, więc częściej indeksowany i pokazywany w wynikach. Mechanizm ten jest dla Google podstawowy i dość niezbędny. Pozwala na oszczędność zasobów i utrzymanie jakości (pozbycie się duplikatów z wyników).
W SEO link kanoniczny nie oznacza jednak tylko adresu wybranego przez Google. To też (a może i przede wszystkim) specjalny link oznaczony tagiem rel="canonical". Linkiem tym, umieszczanym w sekcji <head> strony, wskazujemy wyszukiwarce, co MY uznajemy za kanoniczne (czyli który adres chcielibyśmy pokazać w wynikach).
Jak umieścić link kanoniczny na stronie?
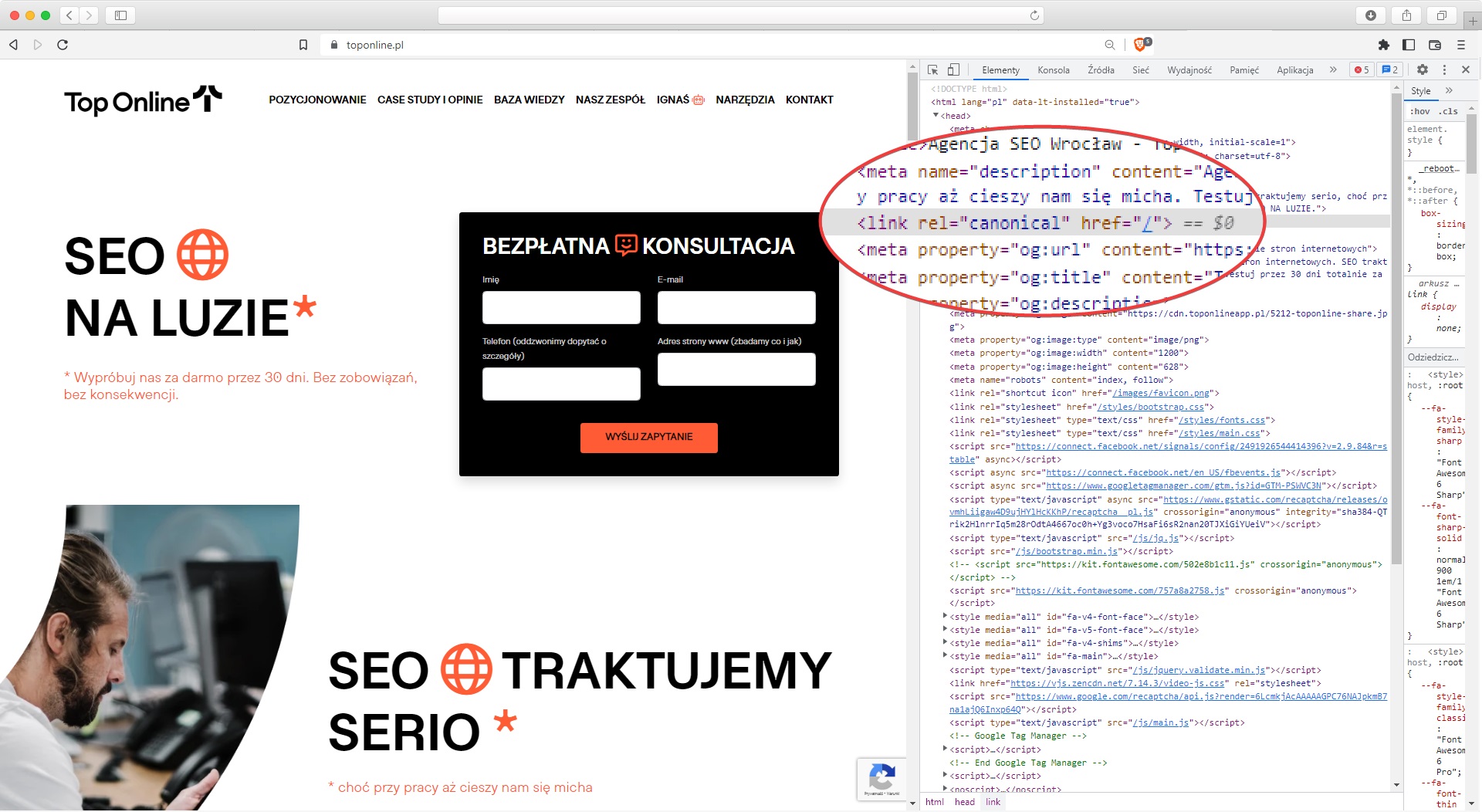
Link kanoniczny umieszczamy w kodzie strony, a dokładnie, w sekcji <head>. URL kanoniczny umieszamy w znaczniku <link>, do którego dodajemy tag rel="canonical". W praktyce wygląda to tak:
<html>
<head>
<link rel="canonical" href="https://example.com/">
</head>
Kanoniczny URL może znaleźć się także w nagłówku HTTP (czyli komendzie używanej do komunikacji serwera z przeglądarką):
Link: <https://www.example.com/>; rel="canonical"
Takie rozwiązanie stosuje się jednak znacznie rzadziej, głównie przy oznaczaniu kanonicznych wersji plików innych niż HTML, np. PDF-ów. Najczęściej, jeśli to tylko możliwe, link kanoniczny trafia po prostu do sekcji <head> w kodzie strony.
W CMS’ach oraz platformach i rozwiązaniach dedykowanych dla e-commerce linki kanoniczne często ustawiamy bez ingerencji w kod, z poziomu interfejsu czy panelu administracyjnego. Jeśli korzystasz z tego typu oprogramowania, koniecznie poszukaj takiej opcji w konfiguracji.
Co warte odnotowania, linki kanoniczne określamy też mimowolnie, wpisując adresy do mapy witryny (sitemap). Nie jest to jednak sygnał tak wyraźny, jak rel="canonical". Mając jedynie do dyspozycji tylko wykaz linków z mapy strony, Google musi samodzielnie określić, które duplikaty dotyczą których adresów i odpowiednio je do nich przypisać. Jest to więc spore pole do błędnej interpretacji i ryzyko powstania kanibalizacji.
Linki kanoniczne jako URL względny czy bezwzględny?
URL bezwzględny (znany też jako adres lub link absolutny) to po prostu pełna ścieżka dostępu do danego zasobu, zawierająca protokół, prefiks oraz trailing slash (jeśli występuje), np. “https://example.com/podstrona”. URL względny (link wewnętrzny lub relatywny) to z kolei jedynie ścieżka dostępu względem strony głównej, czyli np. “/podstrona”.
Zapamiętaj
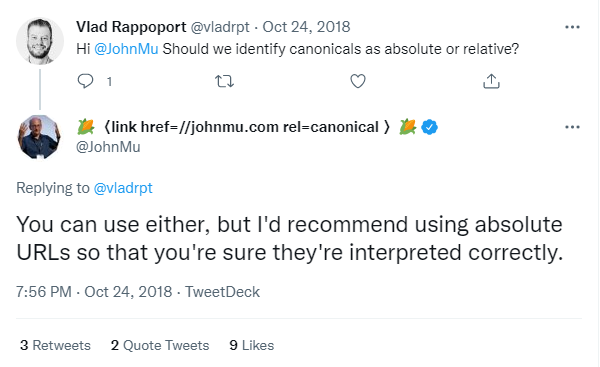
Jako kanoniczny URL możemy śmiało wskazać zarówno link relatywny, jak i bezwzględny, według własnych preferencji.
John Mueller rekomendował kiedyś na Twitterze, że lepiej użyć wariantu pełnego - co ma dać pewność prawidłowej interpretacji ze strony Google. My jednak od lat stosujemy w linkach kanonicznych (u siebie i u Klientów) adresy relatywne, czyli wskazujące tylko ścieżkę.
Jest to zgodne z zasadami konstrukcji HTML (tak samo wskazujemy przecież link wewnętrzny - bez domeny) i nigdy jeszcze nie doprowadziło to do “błędnej interpretacji” ze strony Google. Zapewne nie ma więc różnicy, ale sprawę zostawiamy pod Wasz osąd :)
Kiedy stosujemy linki kanoniczne?
Linki kanoniczne nie są z definicji czymś, co trzeba stosować zawsze, jak np. meta tagi title. Logika podpowiada więc, że po kanoniczny adres URL sięgniemy wtedy, gdy na stronie wystąpi duplikacja, a więc i ryzyko kanibalizacji treści.
Można powiedzieć, że kanoniczny URL umieszczamy też wszędzie tam, gdzie ze względu na funkcjonalność strony nie możemy zastosować przekierowania. Na przykład na stronie produktu w nieco innym wariancie czy rozmiarze, który nie powinien być indeksowany ze względu na ryzyko kanibalizacji ze stroną produktów “głównego”.
Tyle według teorii, bo praktyka SEO pokazuje, że link kanoniczny najlepiej jest zastosować na dosłownie każdej niezduplikowanej podstronie serwisu internetowego, którą chcemy indeksować.
Linki kanoniczne “na siebie”
Tzw. link kanoniczny “na siebie” (self-referencing canonical), to kanoniczny adres URL odnoszący na tę samą stronę, na której został umieszczony. Wskazujący, niezgodnie ze swoim przeznaczeniem z duplikatu na stronę docelową, a ze strony docelowej na dokładnie ten sam adres - czyli właśnie “sam na siebie”.
Taki kanoniczny URL nie jest błędem, a stosując go, niemal kompletnie zapobiegamy powstawaniu duplikacji treści poprzez parametry adresów. Co więcej, jest to dobra praktyka, którą wskazujemy Google, że dany adres jest przez nas wersją preferowaną do wyświetlania w wyszukiwarce.
Wiele CMS-ów dopuszcza dzisiaj stosowanie dowolnych parametrów adresów URL, przez co nawet sam fakt udostępnienia przez kogoś linku z parametrem może doprowadzić do duplikacji. Poza tym mogą ją wygenerować też różne protokoły, obecność lub brak prefiksu www czy zjawisko trailing slash.
https://example.com/
https://example.com/?przyklad
https://www.example.com/
http://example.com/
https://example.com
Wszystkie powyższe adresy to jedna i ta sama strona, ale tylko dla człowieka, nie dla Google. Zgodnie z tym jak działa wyszukiwarka, każdy z powyższych URL-i zostanie potraktowany jako indywidualna strona. I to właśnie w taki niewidoczny sposób powstaje najczęściej duplikacja treści.
Kanoniczny URL na stronie głównej (https://example.com/) kierujący pod tę samą stronę (https://example.com/) rozwiązuje problem. Dzięki niemu każdy działający błędny adres, np. niczego nie zmieniającym parametrem, będzie od razu zawierać link kanoniczny.
Linki kanoniczne “na siebie” zalecał nawet kilkukrotnie pracownik Google, John Mueller (w 2015 oraz w 2017).
Na jakich stronach umieszczamy linki kanoniczne?
To wynika już w pewnym stopniu z tego, co napisaliśmy wyżej, ale odpowiemy bezpośrednio na pytanie, bo nie wyczerpaliśmy tematu. Linki kanoniczne umieszczamy na wszystkich stronach, które chcemy indeksować i pokazywać w wyszukiwarce. Poza tym dodajemy je też na stronach, co do których podejrzewamy możliwość powstawania kanibalizacji.
Przykładami takich stron mogą być adresy filtrowania lub sortowania wyników w sklepach internetowych, które powinny mieć linki kanoniczne skierowane na główny URL kategorii. To także podstrony produktów z powtarzającymi się opisami (np. produktów w innym rozmiarze, kolorze czy wariancie, który nie musi być indeksowany). Klasycznymi przykładami wymagającymi kanonicznego URL-u są też paginacja strony oraz jej inne wersje (np. wersja mobilna lub AMP).
Co ważne, kanoniczny URL możemy dodać też do strony znajdującej się w innej domenie, jeśli tylko mamy nad nią kontrolę. Taka sytuacja zapobiega powstawaniu duplikacji zewnętrznej, gdy np. w ramach promocji publikujemy nasz artykuł blogowy w innym serwisie. W praktyce takie rozwiązanie jest jednak bardzo rzadkie - bo wymaga kontrolowania obu domen oraz powielania właściwie tej samej treści.
Aktualizacja maj 2023: Google zmieniło dotychczasowe zalecenia dotyczące stosowania linków kanonicznych pomiędzy różnymi domenami. Zamiast tego dokumentacja wyszukiwarki zaleca teraz po prostu blokowanie indeksowania duplikatów treści opublikowanych przez nas na innych stronach.
Jak Google ustala kanoniczny adres URL?
Jak to w SEO, sprawa nie jest oczywista. Link kanoniczny w sekcji <head> czy w nagłówku HTTP jest ważny, ale niczego nie gwarantuje. Dla Google to tylko sygnał wskazujący nasze preferencje co do wersji kanonicznej adresu. Wyszukiwarka bierze go pod uwagę, ale i tak ustala kanoniczny URL samodzielnie.
Zapamiętaj
Link kanoniczny umieszczany na stronie jest sygnałem, a nie dyrektywą! Google uwzględnia go więc w wyborze wersji kanonicznej, ale nie traktuje jako regułę.
W dokumentacji wyszukiwarki czytamy, że Google za wersję kanoniczną strony uznaję tę, która jest “najpełniejsza i najbardziej przydatna”. Co to oznacza w praktyce? Że wyszukiwarka zawsze prześwietli strony pod kątem wielu różnych czynników i to dopiero na ich podstawie dokona wyboru wersji kanonicznej. Znacznik rel=canonical jest tu tylko jednym elementem.
Sygnały brane przez algorytm pod uwagę w wyborze wersji kanonicznej strony nie są oczywiście znane, ale Google ujawniło kilka najistotniejszych. Mają być to: certyfikat SSL, obecność URL-a w mapie witryny, link kanoniczny określony w tagu oraz jakość strony.
Linki kanoniczne w wynikach Google
Strony określone przez wyszukiwarkę jako kanoniczne stanowią dla algorytmów główne źródło oceny treści i jakości serwisu pod kątem rankingu. To właśnie one są prezentowane w wynikach wyszukiwania i to one stanowią dla Google “trzon” strony. Duplikaty są “mniej ważne”, o wiele rzadziej indeksowane oraz o wiele mniej wpływające na ranking.
Warto jednak zaznaczyć, że w niektórych przypadkach Google może wyświetlać w wynikach także duplikaty. Głównie wtedy, gdy są one odpowiedniejsze do potrzeb szukającego użytkownika. Przykładowo: gdy mamy mobilną wersję strony uznaną przez osobny adres URL za duplikat, a użytkownik szuka ze smartfona.
Kanoniczny URL przy różnych wersjach językowych
Jeśli Twoja strona posiada różne wersje językowe, to Google musi być w stanie je rozpoznać - i wyświetlać w wynikach odpowiednich dla danego języka. W tym pomagają oczywiście linki kanoniczne, skierowane “na siebie” w poszczególnych wersjach językowych.
Bez linków kanonicznych wyszukiwarka może uznać inną wersję językową za duplikat. Niezależnie od obecności tagu, stanie się tak też wtedy, gdy pod innym językiem znajdzie się nieprzetłumaczona główna treść strony.
Gdy główny tekst jest w tym samym języku co w oryginale, a przetłumaczone zostaną np. tylko tytuł, stopka i menu strony, to niezależnie od kanonicznych URL-i Google nie uzna takiej “wersji językowej”. Zaindeksuje ją jako duplikat wersji oryginalnej.
Jak sprawdzić kanoniczny adres URL danej strony?
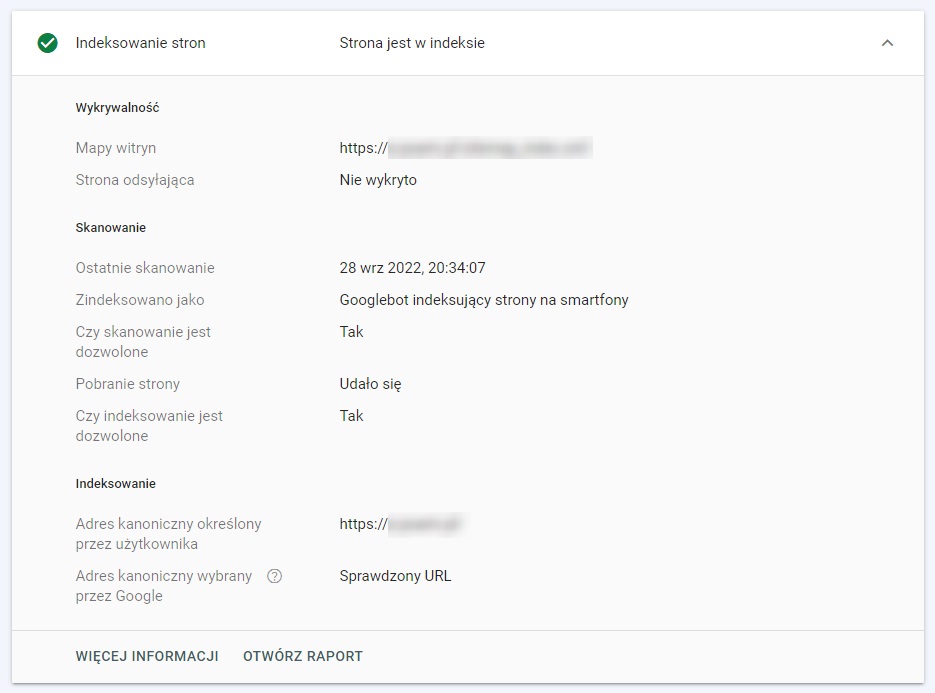
Skoro wiemy już, że Google samodzielnie wybiera sobie kanoniczny adres URL oraz może przy tym ignorować nasze preferencje, to dobrze byłoby móc jakoś ustalić, na który adres ostatecznie padło. Na szczęście nie jest to trudne - wystarczy skorzystać z Google Search Console, a konkretnie z narzędzia do sprawdzania adresów URL.
Wpisujemy adres, który chcemy sprawdzić w narzędziu (w pasku, który znajduje się na samej górze interfejsu GSC) i wciskamy enter. Następnie, w raporcie, rozwijamy sekcję “Indeksowanie stron”. To właśnie tutaj, na samym dole, znajduje się informacja o tym, jaki adres kanoniczny wybrało Google.
Jak audytować linki kanoniczne?
Weryfikacja z pomocą Search Console jest dobra, gdy sprawdzamy wyrywkowo lub analizujemy najważniejsze strony. Wiadomo jednak, że nie sprawdzimy w ten sposób całego serwisu - np. gdy będziemy chcieli zoptymalizować po raz pierwszy linki kanoniczne. Jak więc przeanalizować ten element bardziej globalnie?
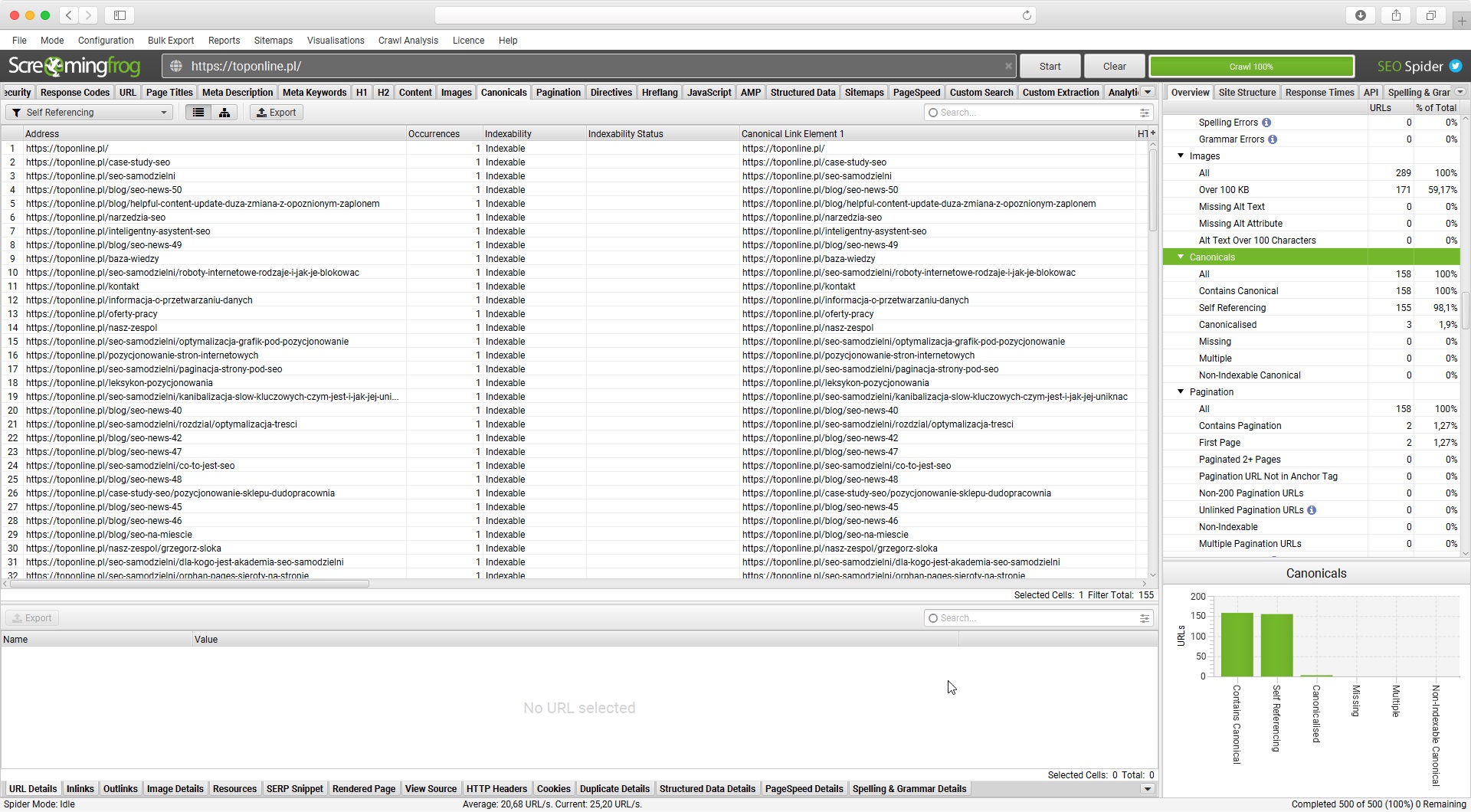
Niestety, nie sprawdzimy “hurtowo”, jakie linki wybiera Google, ale możemy łatwo sprawdzić obecność i poprawność tagów na stronach. Pomoże nam w tym Screaming Frog SEO Spider (lub inny SEO-crawler). Sprawa banalnie wręcz prosta: skanujemy serwis ze standardowymi ustawieniami crawlowania, i przechodzimy do zakładki “Canonicals”.
Poniżej zamieszczamy definicje poszczególnych oznaczeń:
- Contains Canonical - strona posiada oznaczony kanoniczny URL (poprzez tak w
<head>lub nagłówek HTTP), - Self Referencing - URL wykrytej strony posiada link kanoniczny wskazujący “na siebie”, czyli na ten sam adres,
- Canonicalised - strona posiada kanoniczny adres URL kierujący na inną stronę (wykryty URL jest oznaczony jako duplikat),
- Missing - pod wykrytym adresem nie został oznaczony żaden link kanoniczny (Google może uznać tę stronę za kanoniczną),
- Multiple - wykryty adres zawiera więcej niż jeden kanoniczny URL,
- Non-Indexable Canonical - link kanoniczny wykryty pod tym adresem jest nieindeksowalny, czyli niedostępny dla robota (może to być m.in. usunięta strona, błąd serwera, oznaczenie URL jako noindex lub blokada w pliku robots).
Jak interpretujemy linki kanoniczne w Screaming Frog?
Pierwszy typ wykrytych danych, czyli “Contains canonical” to informacja o tym, ile adresów posiada oznaczone linki kanoniczne. Drugi natomiast (“Self Referencing”), mówi, ile z tych wykrytych kanonicznych URL-i wskazuje “na siebie”.
Te dwie rubryki właściwie nas nie interesują. No, chyba że wszystkie wykryte URL-e posiadają link kanoniczny, który wskazuje na siebie - wtedy mówią nam one, że wszystko jest w porządku i nie ma większych problemów.
Najbardziej interesują nas z reguły adresy znajdujące się pod kolejnymi etykietami. Te, które narzędzie wykryje jako “Canonicalised” weryfikujemy pod kątem tego, czy linki kanoniczne z danych adresów wskazują tam, gdzie powinny i czy pojawiły się tutaj jakieś błędy.
“Missing” to właściwie lista adresów, które będą wymagały uzupełniania linków kanonicznych (lub przekierowań czy wyłączenia z indeksowania - jeśli okaże się, że nie powinny być widoczne).
“Multiple” to lista zdublowanych lub wielokrotnych oznaczeń, którym musimy się przyjrzeć bliżej. Dużo adresów w tej kategorii może wskazywać na błędne działanie np. systemu CMS lub wtyczek.
Jeśli na stronie wystąpi “Non-Indexable Canonical”, to również musimy przyjrzeć się mu bliżej. Tutaj jednak nie będziemy tylko sprawdzać, jaki link kanoniczny został ustawiony, ale też, dlaczego wskazana w nim strona nie jest indeksowana.
Co ważne, wykrytą przez robota przyczynę nieindeksowania adresu można podejrzeć już w Screaming Frog. Wystarczy wybrać adres, którego dotyczy problem z listy, a następnie w zakładce “URL Details” (na dole domyślnego interfejsu narzędzia) odnaleźć kolumnę “Canonical Link Element 1 Indexability”.
Jeśli adresów z błędem “Non-Indexable Canonical” mamy w serwisie więcej niż kilka, to do analizy warto wyeksportować specjalny raport pod postacią arkusza kalkulacyjnego. Robimy to wchodząc w Reports > Canonicals > Non-Indexable Canonicals.
W tej zakładce wyeksportować można także raport “Canonical Chains”, który wykazuje łańcuchy linków kanonicznych. Są to sytuacje podobne do łańcuchów przekierowań; łańcuch taki polega na tym, że kanoniczny URL strony wskazuje na stronę, która posiada jeszcze inny kanoniczny URL (i tak dalej).
Zapamiętaj
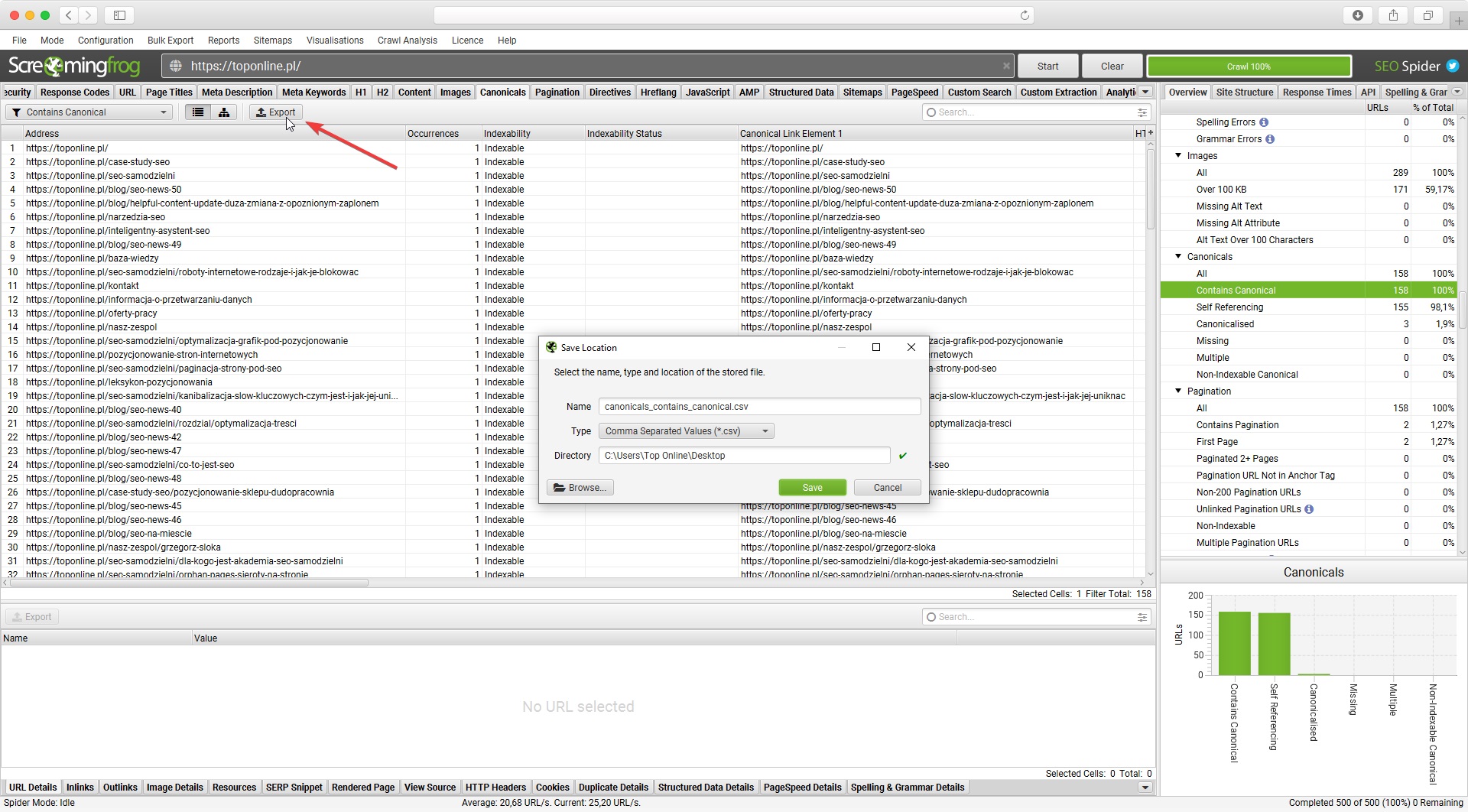
Z analizy strony w Screaming Frog SEO Spider możesz wyeksportować do pliku właściwie wszystkie dane - wystarczy wybrać dowolną etykietę danych i kliknąć przycisk “Export”.
Dobre praktyki wokół linków kanonicznych
Skoro wiemy już, czym są linki kanoniczne, jak je audytować oraz gdzie i kiedy powinno się je ustawiać, to postarajmy się odpowiedzieć jeszcze na pytanie jak to prawidłowo robić. Poniżej prezentujemy zbiór dobrych praktyk wokół linków kanonicznych.
Linki kanoniczne “na siebie”
O tym pisaliśmy już na początku, ale to w sumie jedna z najważniejszych dobrych praktyk, wspomnimy więc jeszcze raz. Na każdej podstronie serwisu, która ma być docelowo prezentowana w Google i rankowana ustawiamy link kanoniczny “na siebie”, czyli odnoszący się do tej samej strony, na której został umieszczony.
Nie jest to działanie obowiązkowe, ale dobrze jest je tak potraktować, bo w ten sposób chronimy stronę przed przypadkową duplikacją, kanibalizacją i późniejszymi problemami z widocznością.
URL kanoniczny na stronie głównej
Jak wyżej, kanoniczny URL odnoszący się do siebie ustawiamy też na stronie głównej. Nie wiedzieć czemu, wiele osób ją pomija, a to spore ryzyko, bo przypadkowo powstające duplikaty strony głównej są wyjątkowo częste.
Linki kanoniczne na podobnych stronach
Oczywiste jest, że kanoniczny adres URL może rozwiązać problem dokładnej duplikacji (np. gdy mamy dwie wersje adresu czy parametry w URL-ach). Co jednak z podstronami podobnymi, ale nie do końca zduplikowanymi, jak np. różne warianty produktów?
W takich wypadkach linki kanoniczne mogą być oczywiście używane, ale stosując je, musimy mieć z tyłu głowy, że:
- Wszystkie “podobne” adresy oznaczone jako niekanoniczne mogą zostać usunięte z indeksu i nie pojawiać się w Google.
- Jeśli strony są od siebie zbyt różne, Google może zignorować nasz tag i potraktować obie indywidualnie - co może skończyć się kanibalizacją.
Sytuacja nr 1 jest naturalnym efektem linku kanonicznego, ale trzeba o niej pamiętać, żeby nie ograniczyć sobie nieopatrznie widoczności. Przy takich “podobnych” stronach zawsze sprawdzamy, na jakie frazy pojawia się w Google kanoniczny URL i nasz potencjalny duplikat.
Możliwe, że Google rozpozna różnice na tyle wyraźnie, że będzie występować sytuacja nr 2. Wówczas rozwiązaniem jest jeszcze mocniejsze zróżnicowanie podstron (ich treści), tak by nie powielały one tych samych fraz i nie walczyły ze sobą o widoczność. Jeśli to niemożliwe, zostaje tylko dodanie tagu “noindex” do podstrony, którą chcieliśmy oznaczyć za niekanoniczną.
Dbajmy o prostotę
Linki kanoniczne są dla Google sygnałami, stosując je, starajmy się więc, by były one zawsze maksymalnie oczywiste i jednoznaczne. Chodzi przede wszystkim o unikanie wszystkich błędów, które wymieniliśmy wyżej przy okazji audytowania adresów kanonicznych w Screaming Frog.
Unikajmy tworzenia pętli linków kanonicznych (czyli kanonikalizacji adresu A do adresu B, adresu B do adresu A) oraz łańcuchów linków kanonicznych (kanonikalizacji adresu A do adresu B, a adresu B do adresu C itd.).
Tak samo pilnujmy, żeby każda strona miała tylko jeden kanoniczny URL. Jeśli zdecydujemy się już na stosowanie linków kanonicznych “na siebie”, to zadbajmy też o to, żeby znalazły się one na wszystkich głównych adresach w witrynie.
Linki kanoniczne między domenami
Jeśli kontrolujemy dwie domeny, pomiędzy którymi powielamy czasem jakieś treści, np. publikujemy artykuły w celu promowania, to na takich powielonych stronach możemy zastosować linki kanoniczne na adres zewnętrzny. Dzięki temu większość “uwagi” Google skupi się na adresie oznaczonym jako kanoniczny, a nasze domeny nie będą zjadać nawzajem swojej widoczności.
Przykładowo, my moglibyśmy opublikować artykuł na blogu Top Online i na portalu Ekomercyjnie, a link kanoniczny skierować tam, gdzie wolelibyśmy akurat mieć widoczność danej treści w Google. W praktyce jednak nigdy nie publikujemy jednego tekstu dwa razy. Wszystko, co pojawia się na stronie Top Online i na Ekomercyjnie jest zawsze unikalne.
Kontrole wyrywkowe
Podobnie jak z wieloma elementami krytycznymi dla prawidłowego indeksowania w Google (więc i widoczności), linki kanoniczne dobrze jest od czasu do czasu wyrywkowo wywołać do tablicy. Takie spontaniczne kontrole, nawet przeprowadzane bezpośrednio w przeglądarce bywają bardzo pomocne. Często pozwalają wykryć błędy, o których nie mieliśmy pojęcia, np. pojawiające się w efekcie aktualizacji oprogramowania czy wtyczek.
Czy kanoniczny URL przekazuje “moc rankingową”?
No właśnie, czy link kanoniczny przekazuje moc rankingową strony, tak samo jak przekierowanie lub chociaż częściowo, jak link wewnętrzny? Okazuje się, że odpowiedź nie jest oczywista.
Według Google “kanoniczny URL pomaga Google skonsolidować ze sobą sygnały wysyłane przez linki wewnętrzne oraz zewnętrzne podobnych lub zduplikowanych stron” (źródło). Oznacza to tyle, że umieszczenie linku kanonicznego może (ale nie musi) sprawić, że Google w jakimś bliżej nieokreślonym stopniu będzie traktować kanoniczny URL jako sumę wszystkich jego wersji. Oficjalnie nie ma więc mowy o bezpośrednim przekazaniu “mocy rankingowej” (link juice) przez link kanoniczny.
W jakimś stopniu zjawisko to może występować, i często nawet daje się zauważyć jakiś czas po wdrożeniu tagów. Tylko czy faktycznie jest efektem “przeniesienia” linków na adres kanoniczny? Czy może raczej jest efektem usunięcia duplikatów i zażegnania kanibalizacji treści? Nie sposób stwierdzić.
Tak czy inaczej, nie polecamy z góry zakładać, że taki mechanizm “przekazywania mocy rankingowej” przez linki kanoniczne istnieje i funkcjonuje, a tym bardziej próbować go jakoś “sprytnie” wykorzystywać. Jedynymi powodami, dla których stosujemy linki kanoniczne, są: rozwiązanie problemu duplikacji oraz kanibalizacji treści, a także usprawnienie indeksowania.
Link kanoniczny, przekierowanie czy “noindex”?
No właśnie, jak postąpić ze zduplikowaną lub bardzo podobną podstroną, która może szkodzić naszej widoczności? Ustawić link kanoniczny na adres pierwotnej treści, otagować duplikat jako “noindex” czy może ustawić przekierowanie strony na adres kanoniczny?
Z tych trzech opcji najłatwiej ustawić przekierowanie. Tutaj sprawa jest prosta: jeśli zastosujemy przekierowanie 301, to adres, który przekierujemy, nigdy nie będzie już dostępny dla użytkowników. Zamiast niego, zobaczą oni adres docelowy, kanoniczny. Takie rozwiązanie ma sens więc tylko wtedy, gdy mamy dokładny duplikat, wynikający np. z dwóch wersji adresów czy występowania trailing slash.
Jeśli nasz duplikat nie jest jednak efektem błędu, a np. wariantem produktu czy URL-em z parametrem filtrowania, to jest ważny pod względem funkcjonalnym i musi pozostać dostępny dla użytkownika. Pozostaje więc pytanie: link kanoniczny czy meta tag noindex?
Właściwie obie opcje zdają egzamin równie dobrze. Wybór tylko od tego, czy chcemy, żeby Google wiedział, że posiadamy też taki URL (link kanoniczny), czy raczej, żeby kompletnie wyłączył go z oceny (noindex).
Istotne jest też to, że w przypadku linku kanonicznego zduplikowany adres nadal może pojawić się w wynikach (np. wspomniana już wcześniej wersja mobilna strony, która może zostać zaprezentowana, gdy użytkownik szuka ze smartfona). Gdy zastosujemy noindex, Google najprawdopodobniej nigdy nie pokaże w wynikach oznaczonego nim adresu.
Kanoniczny URL Twojej strony w social media
Praktyczna ciekawostka na koniec: Facebook i Twitter śledzą linki kanoniczne. Sama ta informacja może i za wiele nie mówi, ale mówią efekty, bo fakt ten generuje ciekawe zjawisko. Gdy udostępnimy na Facebooku lub Twitterze URL posiadający link kanoniczny prowadzący pod inny adres, to tak Facebook, jak i Twitter pobiorą szczegóły wyświetlane w widżecie linku właśnie ze wskazanego adresu kanonicznego.
Podsumowując
Linki kanoniczne są dość wyjątkowym elementem SEO. Istotnym, a nawet można by powiedzieć “bardzo ważnym”, a jednocześnie zupełnie nieobowiązkowym. Czasami, przy bardzo małych stronach, wdrożenie ich kompletnie niczego nie zmienia, a czasami (szczególnie w rozbudowanych sklepach internetowych) jest wręcz kluczowe dla zbudowania solidnej widoczności.
Tak czy inaczej, kanoniczne URL-e dobrze jest rozumieć, znać i oznaczać, bo dobrze wdrożone nie mogą zaszkodzić, a jakby nie patrzeć, dotyczą każdej widocznej w Google strony internetowej. Powodzenia w uzupełnianiu!
Z tego artykułu dowiedziałeś się:
- Czym są linki kanoniczne
- Jak wdrożyć canonicale
- W jaki sposób audytować linki kanoniczne
- Jakie są dobre praktyki dla canonicali
Autorzy artykułu
Zespół Top Online
Adam Przybyłowicz
Product Lead i specjalista od researchu i rozwoju w Top Online. Zdobywa dla nas wiedzę, szuka nowych rozwiązań i pracuje nad tym, żebyśmy nie zostali w tyle. Prowadzi zespół tworzący m.in. YOSA.AI.


