
Paginacja strony, czyli jej podział (stronicowanie), choć u podstaw wcale nie jest żadnym trudnym mechanizmem, to w SEO potrafi nieźle namieszać. Głównie ze względu na swój charakter, który nijak nie pasuje do działania tak wyszukiwarki, jak i jej indeksu. Szczególnie głośno mówi się o tym od 2019 roku, gdy Google ogłosiło oficjalnie zmianę dotychczasowego podejścia.
Co to jest paginacja strony? Jak Google traktowało paginację dawniej, a jak robi to teraz? Gdzie leżą zagrożenia, jak ich uniknąć i na co zwrócić uwagę, by paginacja stron internetowych nie rozbiła na części razem z nimi potencjalnych efektów SEO? No i kiedy stronicowanie jest w ogóle potrzebne? Na te wszystkie pytania odpowiadamy w tej części SEO Samodzielnych.
Spis treści:
- Czym jest paginacja strony i skąd to całe zamieszanie?
- Jak Google traktowało dawniej paginację strony?
- Jak Google traktuje paginację strony dzisiaj?
- Jak zoptymalizować stronicowanie?
- Paginacja stron a linki kanoniczne
- Czy paginacja strony powinna mieć noindex?
- Jak wygląda Twoja paginacja strony?
- Kiedy paginacja strony jest potrzebna?
- Paginacja stron internetowych od strony użytkownika
- Infinite scroll
- Znaczniki ”next/prev” - dodawać, usuwać?
- Paginacja nie taka straszna (Podsumowanie)
Powiązane:
Czym jest paginacja strony i skąd to całe zamieszanie?
Paginacja strony (inaczej stronicowanie) to proces dzielenia treści na kilka powiązanych ze sobą, kolejnych stron. To bardzo częsta i powszechnie używana technika, dzięki której strony internetowe mogą w użyteczny sposób prezentować listy artykułów czy produktów.
Mówiąc najprościej, jest to podział jednej strony na kilka adresów, który stosuje się tam, gdzie dla jednego URL-u treści byłoby zwyczajnie za dużo. Paginacja stron internetowych występuje dzisiaj właściwie wszędzie, ale najczęściej widzimy ją w sklepach, ze względu na dużą liczbę podstron z listami produktów.
A dlaczego stronicowanie, jako coś tak naturalnego i codziennego jest wyzwaniem dla SEO?
Cóż, odpowiedź jest dość prosta: każda kolejna podstrona paginacji to osobny adres URL. Jak nietrudno się więc domyślić, dla wyszukiwarki jedna strona podzielona paginacją na 20 adresów stanowi… 20 osobnych stron. Często zoptymalizowanych na te same frazy albo niezoptymalizowanych niemal wcale. I tutaj zaczynają się schody.
Jak Google traktowało dawniej paginację strony?
Żeby lepiej pojąć “co jest pięć”, na początek trochę kontekstu. Paginacja jako taka zaczynała mieć znaczenie pod pozycjonowanie mniej więcej wtedy, gdy znaczenie zaczynała mieć treść - czyli od wprowadzenia pierwszej wersji algorytmu Panda.
Około 7 miesięcy od opublikowania Pandy, w połowie września 2011 pojawiły się atrybuty linków rel=”next” i rel=”prev”. Google opublikowało wówczas stronę pomocy, która wyjaśniała i rekomendowała ich użycie w paginacji.

Jeśli stosowaliśmy stronicowanie, mogliśmy znacznikami tymi wspomóc wyszukiwarkę w zrozumieniu, że odwiedza adres będący jedynie elementem większej, podzielonej strony. Od wtedy stosowanie rel=”next” i rel=”prev” stało się właściwie jedynym dodatkowym, co powszechnie robiło się w SEO z paginacją.
Sprawa była banalnie prosta: pierwsza strona paginacji znacznikiem “next” linkowała do drugiej, druga znacznikiem “prev” do pierwszej i znacznikiem “next” do trzeciej itd., ostatnia natomiast jedynie do poprzedniej.
Google widząc te znaczniki, otrzymywało wskazówkę, że linkujące tak do siebie podstrony trzeba skonsolidować. Połączyć w jedną i tak oceniać, a wyświetlać w wynikach tylko pierwszą. Po 8 latach okazało się jednak, że wyszukiwarka znaczników tych wcale już do niczego nie potrzebuje.
Jak Google traktuje paginację strony dzisiaj?
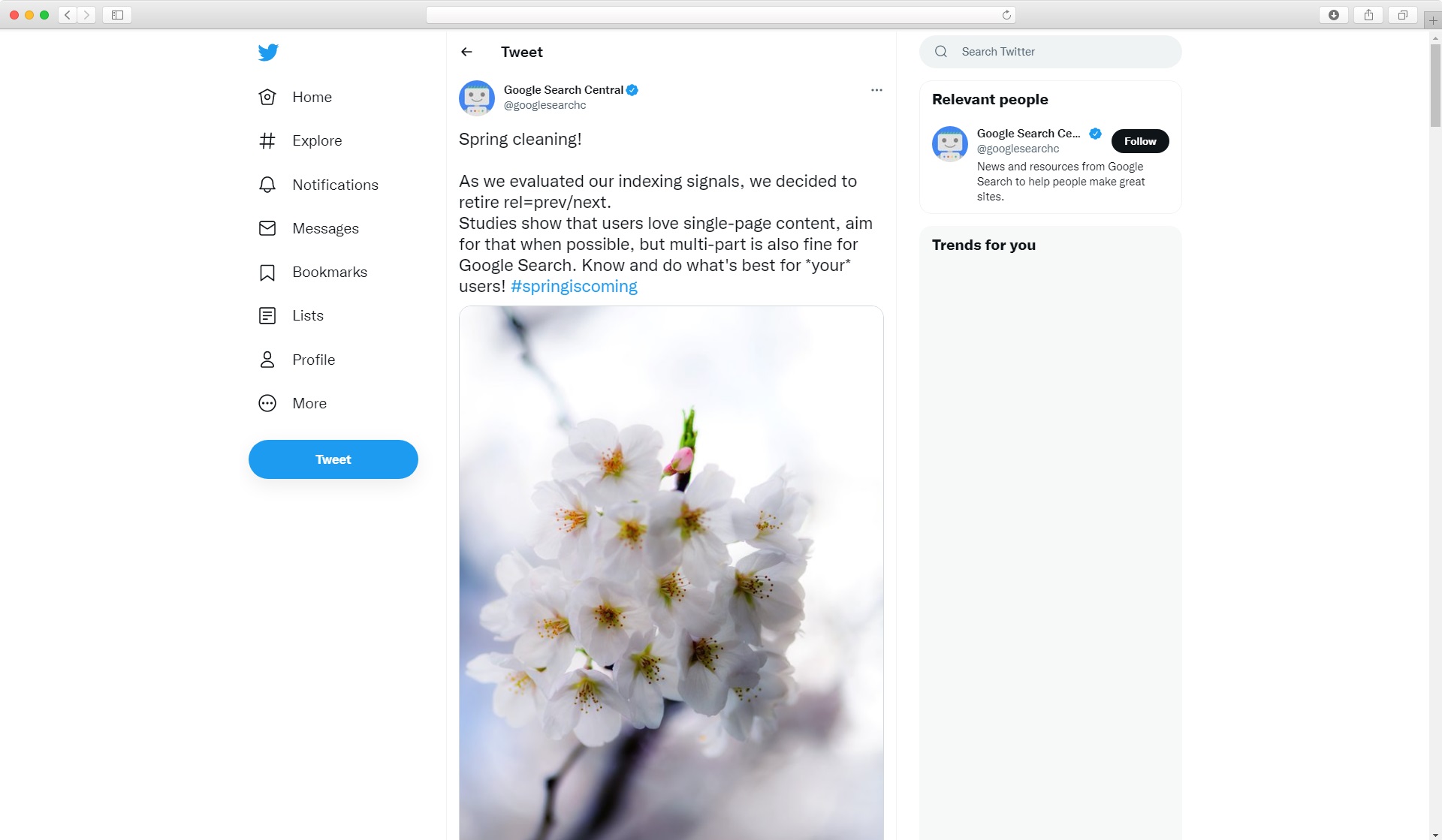
W 2019 jak grom z jasnego nieba runęła wiadomość, a właściwie pojawił się tweet. Google Search Central poinformowało: “Wiosenne porządki! Oceniliśmy znaczenie czynników oddziałujących na indeksowanie i zdecydowaliśmy, że czas wycofać rel="next/prev”.
Choć dobre pół branży nieźle się zdziwiło, w rankingach nie zmieniło się oczywiście nic - bo znaczniki po prostu nie były już od dłuższej chwili potrzebne. Algorytm nie zwracał na nie uwagi. Największą zmianą było to, że razem z tą informacją, okazało się, że właściwie nikt nie wie, jak powinna być wykonana przyjazna SEO paginacja strony.
Jeden fakt ze strony Google sprawił, że cała dotychczasowa wiedza okazała się nagle przestarzała. Wszyscy, którzy zrozumieli, co się stało, wrócili więc do podstaw. I tak zaczęły się poszukiwania.
Spore wyjaśnienie przyszło dzień po Tweecie, w trakcie cyklicznego spotkania Google Webmaster Office-hours, które odbyło się akurat 22 marca. Wówczas to, prowadzący je John Mueller, Webmaster Trends Analyst Google, powiedział społeczności o tym, że paginacja stron internetowych jest teraz traktowana identycznie jak wszystkie inne strony.
Oznaczało to tyle, że na dobre zakończyła się idea konsolidacji paginacji w indeksie. Google zaczęło traktować każdy adres stronicowania jako indywidualną podstronę. Jeśli sklep miał więc np. kategorię podzieloną na 6 stron paginacji, to zamiast jednej strony “dla wyników” oraz stron paginacji dla użytkowników, miał teraz dodatkowe 5 osobnych stron.
Przyszedł więc czas, by wziąć się do pracy i zacząć optymalizację. Pozostawało tylko pytanie: jak to tak właściwie zrobić?
Jak zoptymalizować stronicowanie?
Jeśli Twój serwis stosuje paginację strony, to najpewniej czeka Cię zmierzenie się z jej optymalizacją. Od razu jednak uspokajamy, to wcale nie takie trudne. Najważniejsze: zrozumieć jak widzi to Google i nie starać się za wszelką cenę oszukać algorytmu.
Zapamiętaj
Dobrze zoptymalizowana paginacja strony to taka, w której Google uznaje pierwszą stronę paginacji za najistotniejszą i najlepiej dopasowaną do fraz, więc tym samym to ją (z całej paginacji) wyświetla najwyżej w wynikach.
Stronicowanie jest dość naturalne i wcale nie jest tak, że trzeba je “schować” przed wyszukiwarką. Każda w miarę poprawnie wykonana paginacja strony nie będzie stanowić dla Google większego wyzwania. Trzeba tylko przypilnować paru technicznych kwestii, żeby roboty internetowe wyszukiwarek wiedziały, z czym mają do czynienia.
Reasumując: staramy się zrobić tak, żeby Google chciał wyświetlać i pokazywać tylko pierwszą stronę paginacji (np. stronę kategorii w sklepie).
Pierwsza strona paginacji
W wielu systemach CMS świeżo wdrożona paginacja stron internetowych tworzy za pierwszą stronę paginacji duplikat dzielonego pierwotnego adresu. Zacznijmy więc od sprawdzenia, czy tak się nie stało.
Przykładowo: pierwszym adresem stronicowania dla kategorii (example.com/fotele-biurowe) może stać się jej duplikat, który utworzy się np. pod (example.com/fotele-biurowe/strona-1).
Sprawdzamy to, wchodząc w kategorię, na której wdrożona została paginacja strony. Wchodzimy na drugą lub dalszą stronę z linków, które wygenerowało stronicowanie (zwykle numerów stron na dole listy produktów czy artykułów) i wracamy z niej (tymi samymi linkami) do strony pierwszej. Teraz wystarczy zobaczyć, pod jakim jesteśmy adresem.
Zapamiętaj
Pierwsza strona paginacji to tzw. root page - podstrona, którą podzieliliśmy, o oryginalnym adresie URL, np. kategorii sklepu internetowego.
Jeśli okaże się, że nie jest to URL naszej kategorii (root page) - to wystąpił wspomniany błąd. Gdy dojdzie do takiej sytuacji, usuwamy świeży duplikat naszej podstrony. Jeśli to niemożliwe - bo np. znalazł się on już w indeksie, stosujemy przekierowanie 301 na pierwotną kategorię. Aktualizujemy też linkowanie wewnętrzne (numery stron paginacji).
Gdy paginacja strony internetowej (np. w sklepie) jest wdrożona w dziesiątkach kategorii, a w każdej z nich występuje analogiczny błąd, to warto poszukać rozwiązania w samych ustawieniach paginacji dostarczanych przez CMS. Ostatecznie można też zgłosić się o pomoc do dostawcy oprogramowania - aby rozwiązać źródło problemu (błędne generowanie), zamiast tylko leczyć ciągle jego objawy ustawianiem przekierowań.
Jeśli okaże się, że nie jest to URL naszej kategorii (root page) - to wystąpił wspomniany błąd. Gdy dojdzie do takiej sytuacji, usuwamy świeży duplikat naszej podstrony. Jeśli to niemożliwe - bo np. znalazł się on już w indeksie, stosujemy przekierowanie 301 na pierwotną kategorię. Aktualizujemy też linkowanie wewnętrzne (numery stron paginacji).
Gdy paginacja strony internetowej (np. w sklepie) jest wdrożona w dziesiątkach kategorii, a w każdej z nich występuje analogiczny błąd, to warto poszukać rozwiązania w samych ustawieniach paginacji dostarczanych przez CMS. Ostatecznie można też zgłosić się o pomoc do dostawcy oprogramowania - aby rozwiązać źródło problemu (błędne generowanie), zamiast tylko leczyć ciągle jego objawy ustawianiem przekierowań.
Dla pewności polecamy też poszukać duplikatów w jakimś SEO crawlerze (np. Screaming Frog SEO Spider).
Jakie adresy powinna mieć paginacja stron internetowych?
Dla stron paginacji najlepiej jest używać adresów URL z parametrami np.: (/kategoria?page=2).
Jak donosi Adam Gent z DeepCrawl, który przeprowadził w 2019 jedną z najszerzej zakrojonych analiz odnośnie optymalizacji paginacji: przy takim rozwiązaniu Google o wiele łatwiej jest poprawnie zinterpretować schemat podziału stron do celów crawlowania.
Adresy statyczne też są w porządku, ale Google może mieć z nimi nieco “pod górkę”. Sugerują one bardziej algorytmowi indywidualny charakter podstron. Z kolei na pewno w paginacji powinno unikać się identyfikatorów fragmentów (#), np. (/kategoria#page=2).
Zapamiętaj
Zgodnie z dokumentacją Googlebota, wyszukiwarka zignoruje kompletnie wszystko, co znajdzie się w URL-u po znaku #.
Meta title i description
Paginacja stron pozostawiona “sama sobie” prowadzi często do duplikacji treści, a w efekcie i jej kanibalizacji. Zwykle ze względu na to, że powiela ona meta tagi (a czasem także i treści - ale o tym dalej). Żeby temu zapobiec, musimy więc rozróżnić strony, tak, żeby Google wiedziało, z czym ma do czynienia.
Rozwiązanie jest tutaj banalnie proste, a nawet całkiem łatwe do zautomatyzowania na większą skalę. Po prostu: sugerujemy kolejność podstron w tagach według jednego, określonego schematu, czyli np.:
Pierwsza strona (kategoria “Paginacja strony”):
- Meta title: Paginacja stron internetowych - wszystkie elementy optymalizacji
- Meta description: Wszystkie elementy optymalizacji paginacji strony internetowej. Sprawdź, jak stworzyć stronicowanie w zgodzie z wyszukiwarką!
Strona druga:
- Meta title: Strona 2: Paginacja stron internetowych - wszystkie elementy optymalizacji
- Meta description: 10 - 18 (z 25) elementów optymalizacji paginacji strony internetowej. Sprawdź, jak stworzyć stronicowanie w zgodzie z wyszukiwarką!
Przykładu chyba nie trzeba już wyjaśniać. Takie numerowane wyraźnie tytuły i opisy pomogą Google odnaleźć się w kolejności. Ponownie jednak, podobnie jak w URL-ach, nie nazywamy pierwszej strony paginacji “pierwszą” czy “stroną 1” - zostaje nią po prostu kategoria.
Co ważne, meta tagi zmieniamy w paginacji o statycznych linkach. W przypadku stosowania parametrów (adresów dynamicznych) rozwiązanie to wymagałoby stworzenia specjalnego skryptu, który generowałby razem ze stronami dynamiczne tagi. Jest to oczywiście osiągalne, ale spokojnie, obejdzie się i bez tego.
Paginacja strony a sitemap.xml
W całym światku SEO przyjęło się, że w pliku sitemap nie ma pojawić się cała paginacja strony, a jedynie jej root page (strona pierwsza, kategoria podlegająca paginacji).
Zabieg ten ma sprawiać, że Google nie będzie tracić czasu na crawlowanie wszystkich adresów stronicowania. Dodatkowo wydaje się też dość logiczny, bo mapa witryny ma co do zasady zawierać wszystkie adresy strony, a kategoria czy blog z paginacją z punktu widzenia architektury informacji nadal stanowi jedną stronę, tylko podzieloną.
Analogicznie jednak, z punktu widzenia czysto technicznego stronicowanie jest osobnymi adresami URL i ze względu na to (mapa witryny ma zawierać wszystkie adresy strony) powinno być wykazane w pliku sitemap.
Co więc zrobić? To zależy od tego, jak skonstruowana jest paginacja strony:
- Jeśli kolejne URL-e stronicowania są generowane dynamicznie, a w adresach pojawiają się parametry, np: (example.com/kategoria?page=2), to w pliku sitemap prezentujemy tylko root page (example.com/kategoria).
- Jesli z kolei URL-e stronicowania są statyczne, np. (example.com/kategoria/page-2) to w mapie wykazujemy już normalnie, tak root page, jak i każdy kolejny adres paginacji.
Linkowanie wewnętrzne
Paginacja strony internetowej powinna być dostępna dla Googlebotów - głównie dlatego, że jej podstrony są często jedynym sposobem dotarcia do produktów w sklepie czy artykułów na blogu. Musi więc zawierać nadające się do crawlowania adresy, bo jeśli Google nie będzie w stanie ich odwiedzić, to nie odwiedzi też listowanych przez nie podstron (produktów czy artykułów).
W tej kwestii upewniamy się, że linki naszej paginacji (numery stron lub przyciski “następna” / “poprzednia”) są normalnymi linkami wewnętrznymi. Powinny stosować atrybut a href i anchor tekst, np.
<a href=”https://example.com/kategoria?page=2″>
Nie powinny z kolei zawierać atrybutów, których Google nie jest w stanie śledzić, np.:
<span href=” https://example.com/kategoria?page=2″><a routerLink=” /kategoria?page=2″><a onclick=”goto(‘https://example.com/kategoria?page=2’)”>
Stronicowanie a blokowanie indeksacji
Tak jak pisaliśmy wyżej, nie chowamy naszej paginacji przed Google, wręcz przeciwnie - upewniamy się, że do niej łatwo dotrze. Wdrażając stronicowanie (lub audytując już to obecne) sprawdzamy więc, czy podstrony paginacji nie posiadają parametrów noindex lub, czy paginacja strony nie jest blokowana w pliku robots.
Zapamiętaj
Zdajemy sobie sprawę, że to zalecenie jest niezgodne z większością porad odnośnie paginacji w SEO dostępnych w polskim internecie - sprostowanie znajdziesz w dalszej części artykułu.
Tak w kontekście ew. blokowania indeksacji i odpowiedniego linkowania polecamy zastosować Screaming Frog (przeprowadzić symulację crawlowania jako Googlebot). Jeśli adresy paginacji zostaną znalezione i poprawnie przeskanowane - wszystko gra. W ten sposób sprawdzamy dwie rzeczy za jednym razem.
Paginacja strony a treści
Co do zasady treści takie jak opisy kategorii czy podstron pozostawiamy tylko na dzielonym root page’u, czyli pierwszej stronie paginacji. Jeśli content będzie powielał się na wszystkich jej stronach, to zaniżymy sobie w ten sposób widoczność.
Google wyłapie wówczas duplikacje i przyjmie wersję kanoniczną, nie indeksując pozostałych stron. Na pierwszy rzut oka może być to i opcją pożądaną, ale pamiętajmy o tym, że nie chodzi o to, żeby wyszukiwarka nie widziała paginacji, tylko żeby wiedziała, co jest w niej najistotniejsze pod kątem wyświetlania w wynikach.
Skupiamy się więc na tym, by tekst na pierwszej stronie paginacji był maksymalnie użyteczny i pomagał jej spełnić stojące za dobranymi frazami intencje użytkowników. Razem z brakiem treści i de-optymalizacją tagów (zmianą title) na dalszych podstronach paginacji pozwoli to uniknąć kanibalizacji.
Zapamiętaj
Istotną kwestią w kontekście unikania kanibalizacji paginacji są także linki wewnętrzne z odpowiednimi anchorami kierujące do root page’a z całego serwisu.
Paginacja stron a linki kanoniczne
Wokół linków kanonicznych w paginacji urosło sporo powtarzanych ślepo mitów, z czego najgłośniejszy mówi o tym, że cała paginacja strony (każdy URL) powinna mieć canonical ustawiony na jej pierwszą stronę (kategorię).
Nie robimy tak z prostego powodu: link kanoniczny ma z definicji sugerować oryginalną wersję treści na stronach zduplikowanych, a każda strona paginacji jest przecież czymś zupełnie innym. Zgodnie ze sztuką (teorią), na każdej stronie paginacji powinniśmy ustawić więc link kanoniczny odsyłający “sam do siebie”.
W praktyce stosujemy jednak oba rozwiązania, w zależności od tego, czy chcemy, żeby Google crawlowało daną paginację:
- Jeśli do listowanych elementów (np. produktów) da się dotrzeć tylko przez stronicowanie kategorii, to naturalnie chcemy, żeby Google crawlowało naszą paginację, tym samym przechodząc do produktów czy artykułów i je indeksując. Stosujemy więc canonical “na siebie”.
- Jeśli z kolei do listowanych elementów da się już dotrzeć (np. z paginacji głównych kategorii), a teraz implementujemy paginację dla kategorii n-tego rzędu, możemy już śmiało zastosować canonical na root page.
Gdy paginacja stron występuje w niewielkiej skali (np. kilkanaście kategorii sklepu po kilka stron produktów każda), śmiało możemy stosować canonical “na siebie”. Umocni to strukturę linkowania wewnętrznego serwisu i usprawni przepływ link juice do najważniejszych stron.
Gdy jednak stronicowanie jest jednak bardzo rozległe (np. setki kategorii po kilkadziesiąt stron), to warto zastosować już rozwiązanie mieszane. Z linkiem kanonicznym “na siebie” dla paginacji podstron najważniejszych w strukturze i z linkiem kanonicznym na root page dla paginacji podstron dalszych.
Taki schemat działania pozwoli lepiej zarządzać budżetem indeksowania. Przed wdrożeniem takiego wariantu mieszanego upewniamy się tylko, że każdy listowany “głębiej” element jest dostępny też w paginacji podstron indeksowanych.
View-All Page
Musimy jeszcze wspomnieć o rozwiązaniu pośrednim - czyli tworzeniu tzw. View-All Page, podstrony prezentującej pełną listę elementów, co do których stosowana jest paginacja strony. Rozwiązanie to można zastosować tam, gdzie paginacja nie jest ogromna - elementów jest na tyle mało, że można je załadować sprawnie na jednej stronie.
Na taką stronę można śmiało kierować linki kanoniczne z całej paginacji, a nawet root page’a. Rozwiązanie to jednak może zaburzać strukturę serwisu - bo nagle dodatkowy adres staje się ważniejszy od głównej, nadrzędnej stosunkiem do niego pierwszej strony paginacji. Ostatecznie to on też wyświetli się w wyszukiwarce zamiast dzielonych stron.
Użytkownik trafiający do kategorii “X” z Google zobaczy długą listę produktów, ale gdy trafi najpierw do kategorii “Y”, a dopiero potem przejdzie z nawigacji do kategorii “X”, to zobaczy już pierwszą stronę paginacji. Zabieg ten może wprowadzać więc niepotrzebne zamieszanie.
Zresztą, skoro możemy bezstratnie wyświetlać wszystko pod jednym adresem, to po co nam w ogóle paginacja strony internetowej?
Naszym zdaniem nie warto kombinować - jeśli jesteśmy w stanie stworzyć View-All Page, to niech będzie nią strona, którą chcieliśmy pierwotnie podzielić. Jeśli nie jest to rozsądne ze względu na czas ładowania i ogrom listowanych elementów - stosujemy tylko stronicowanie, w końcu to po to się je przecież wdraża.
Czy paginacja strony powinna mieć noindex?
Czas na wyjaśnienie naszego zalecenia odnośnie nieblokowania indeksacji stronicowania. W wielu miejscach można też przeczytać, że indeksować trzeba tylko pierwszą stronę paginacji, a resztę odciąć w pliku robots, oznaczyć jako noindex w tagach i “problem z głowy”. Rzecz w tym, że nie do końca.
Głównymi obawami w związku z którymi paginacja strony jest zwykle blokowana przed wyszukiwarką, są duplikacja i kanibalizacja treści. To jednak obawy złudne:
- Po pierwsze, przy zachowaniu odpowiedniej optymalizacji te po prostu nie wystąpią, bo nie będzie ku temu podstaw,
- Po drugie, Google doskonale zrozumie, że dane adresy są paginacją i nie będzie starać się zamieniać ich w wynikach.
To jednak nie jest najistotniejsze, bo, nie indeksując wszystkich podstron stronicowania w serwisie, odcinamy wyszukiwarkę od wszystkiego, co znajdzie się poza pierwszymi stronami paginacji.
Ten fakt może z kolei mieć już opłakane skutki, bo w sklepie internetowym czy na blogu nieindeksowanie paginacji:
- Może doprowadzić do niezindeksowania produktów lub artykułów, a nawet wyrzucenia ich z indeksu, jeśli są już widoczne.
- Może wygenerować orphan pages, ponieważ odetnie linkowanie wewnętrzne do podstron znajdujących się w paginacji.
- Może zniszczyć strukturę serwisu, odcinając tym samym przepływ link juice z kategorii do produktów (lub bloga do artykułów) i na odwrót.
- A wszystkie te efekty poskutkują znacznym spadkiem widoczności.
Analogicznie jednak, jak w przypadku linków kanonicznych: przy serwisach bardzo dużych, które rozbudowujemy o kolejne adresy (np. dodatkowe kategorie produktów zoptymalizowane na kolejne frazy) paginacja strony z noindex wszędzie poza root page’em może mieć sens.
Mimo to, z naszych doświadczeń wynika, że absolutna większość nawet bardzo rozbudowanych serwisów nie wymaga takich zabiegów. Jedyna sytuacja, w której częściowe wdrożenie noindex w paginacji mogłoby mieć sens jest wyraźny problem z crawl budget. A to już domena niemal wyłącznie największych sieciowych molochów.
Jak wygląda Twoja paginacja strony?
Nie będziemy się tutaj rozwodzić nad aspektem użyteczności poszczególnych designów, chodzi o głębokość struktury strony. Znasz zasadę trzech kliknięć? Mówi ona o tym, że wszystkie najważniejsze treści na stronie powinny znajdować się w zasięgu trzech kliknięć od strony głównej. Jak w zestawieniu z tą zasadą wypada Twoja paginacja strony?
Generalnie, powinniśmy zadbać o to, żeby struktura była maksymalnie “płaska”, czyli, żeby nie generowała niepotrzebnych zagnieżdżeń. Im mniej kliknięć do stron produktów w paginacji kategorii czy artykułów w paginacji bloga, tym lepiej.
Głębokość zagnieżdżenia najłatwiej sprawdzić symulując Googlebota, poprzez np. Screaming Frog SEO Spider. Interesuje nas metryka “Crawl depth”. Optymalizacji podlegają wszystkie najbardziej oddalone od strony głównej adresy, które powinny być widoczne w Google.
A jak zmniejszyć liczbę kliknięć? Poprzez odpowiednie linkowanie paginacji, np. do 5 kolejnych stron z root page’a. Zawsze można też dodać wszelkie dodatkowe linkowanie wewnętrzne do dalszych podstron paginacji.
Nic nie stoi na przeszkodzie także wszelkim rozwiązaniom nieszablonowym, jak np. dodatkowe sekcje “polecane” czy “popularne” w kategoriach lub na stronie głównej.
Zapamiętaj
Pamiętajmy, że każde potencjalne rozwiązanie problemu ze zbyt głęboką strukturą paginacji powinniśmy najpierw przetestować poprzez eksperyment z udziałem zewnętrznego crawlera.
Kiedy paginacja strony jest potrzebna?
Użytkownicy kochają mieć wszystko na jednej stronie - tak przynajmniej mówi Google. Zdecydowanie nie kochają jednak czekać na załadowanie strony, przeglądać lagujących się serwisów i nie móc się odnaleźć. Sprawa jest więc prosta.
Jeśli sklep czy blog urósł już na tyle, że lista prezentowanych na jego podstronach elementów może spowalniać serwis czy jakkolwiek utrudniać jego przeglądanie to potrzebna jest paginacja. Jeśli z kolei elementów listowanych jest sporo, ale nie na tyle, żeby ich liczba spowalniała serwis czy utrudniała przeglądanie, to stronicowanie może spokojnie poczekać.
Paginacja stron internetowych od strony użytkownika
Pokryliśmy już właściwie wszystkie SEO-we technikalia. Zostaje więc powiedzieć dwa słowa o wdrażaniu paginacji z myślą o użytkowniku. Tutaj właściwie zwracamy uwagę na dwa aspekty: przejrzystość i intuicyjność.
Po kolei:
- Przejrzystość paginacji polega na odpowiednim podziale stron - liczba elementów powinna nie być zbyt duża, elementy powinny mieć powtarzalny układ, a same strony paginacji powinny być odpowiednio oznaczone (żeby było wiadomo, na której się znajdujemy).
- Intuicyjność paginacji to przede wszystkim jej odpowiedni design, czyli odpowiednio duże, widoczne i oczywiste przyciski, możliwość szybkiego przechodzenia do konkretnych stron oraz jednoznaczny układ listy.
Zapisywanie elementów
W dużych serwisach dobrym rozwiązaniem jest dodanie jakiegoś rodzaju funkcjonalności zapisywania wybranych elementów. Może być to możliwość obserwowania produktów czy dodawania artykułów do ulubionych. To bardzo wygodne rozwiązanie.
W sklepach funkcję tę pełni często koszyk, ale dla wielu użytkowników dodanie przedmiotu do koszyka jest już elementem procesu decyzyjnego. “Zaobserwowanie” z kolei jest o wiele mniej zobowiązujące, a może w przyszłości doprowadzić do zakupu.
Mając taką możliwość niektórzy użytkownicy klikną “na wszelki wypadek” wszystko, co wpadnie im w oko, by później się nad nimi zastanowić. Bez takiej funkcji, na dużą część wyświetlonych przedmiotów już nigdy nie więcej trafią.
Infinite scroll
Infinite scroll to alternatywa dla paginacji polegająca na tym, że lista elementów, którą normalnie dzieliłoby stronicowanie, jest dynamicznie doładowywana użytkownikowi, w miarę scrollowania strony. Takie rozwiązanie może być dobrym wyborem, ale wymaga ostrożności, szczególnie gdy mamy na stronie bardzo dużo listowanych elementów.
Zapamiętaj
Googlebot zawsze będzie starał się załadować całą stronę - więc jeśli ta (dynamicznie doładowywana) będzie zbyt duża, może zostać przez to niekorzystnie oceniona lub nawet niezindeksowana.
Niektóre warianty infinite scroll to tak naprawdę sprytnie “schowana” przed użytkownikiem paginacja stron internetowych. W miarę scrollowania serwis przechodzi na kolejne URL-e z parametrami paginacji. Taka implementacja jest optymalna - ponieważ zachowuje zalety niewdrażania stronicowania dla użytkownika (wszystko na jednej stronie), ale i daje pewność, że nie zostanie nieprawidłowo odczytana przez Googlebota.
Taki mechanizm nie powinien być jednak stosowany tam, gdzie użytkownik może chcieć móc szybko wrócić do konkretnych fragmentów, np. w większych sklepach internetowych. W przeciwieństwie do klasycznej paginacji infinite scroll na to po prostu nie pozwala. Nie da się tu szybko przejść do 3, 5 czy 12 strony listy, bo lista jest doładowywaną w miarę scrollowania całością.
Znaczniki ”next/prev” - dodawać, usuwać?
Na dodawanie znaczników rel="next/prev" dzisiaj, w naszej opinii, szkoda już czasu. No, chyba że prowadzicie SEO pod kątem innych wyszukiwarek, bo Google wyraźnie powiedziało, że tagów tych nie uwzględnia.
Jeśli next/prev pojawia się z kolei w efekcie generowania paginacji przez CMS, to śmiało możemy te znaczniki tam zostawić. Korzystają z nich inne wyszukiwarki, a to, że nie uwzględnia ich Google, nie znaczy, że szkodzą one widoczności. Po prostu są ignorowane, ponownie więc: nie ma więc co tracić na nie czasu.
Paginacja nie taka straszna (Podsumowanie)
Od kiedy Google przyznało się do tego, że paginacja strony nie jest już “sklejana” w indeksie w całość, a traktowana jako osobne podstrony, wyrosło przekonanie, że optymalizacja stronicowania jest skomplikowana. Jak jednak widzisz, w praktyce, nie stanowi to aż tak wielkiego wyzwania.
W największym skrócie: mając z tyłu głowy, że strony paginacji stanowią ważny punkt dostępowy do podstron produktów, artykułów czy innych elementów, traktujemy je tak samo, jak wszystkie inne strony. Pozwalamy im być indeksowanymi, dbamy o ich optymalizację (root page) i de-optymalizację (drugie strony paginacji i dalsze), by uniknąć kanibalizacji słów kluczowych.
Koniec końców chodzi o to, by na stronie powstała przyjazna, przejrzysta i użyteczna nawigacja w której odnajdą się bez mrugnięcia okiem wszyscy: My, Google i nasi użytkownicy. Powodzenia we wdrożeniach i optymalizowaniu!
Z tego artykułu dowiedziałeś się:
- Czym jest i jak działa paginacja strony
- Jak optymalizować strony pod paginacje
- Jakie są sposoby wdrożenia paginacji
Autorzy artykułu
Zespół Top Online
Adam Przybyłowicz
Product Lead i specjalista od researchu i rozwoju w Top Online. Zdobywa dla nas wiedzę, szuka nowych rozwiązań i pracuje nad tym, żebyśmy nie zostali w tyle. Prowadzi zespół tworzący m.in. YOSA.AI.


