
Znajdź i napraw orphan pages na swojej stronie! To niepozorny błąd, przez który możesz regularnie tracić ruch i utrudniać sobie SEO, kompletnie nic o tym nie wiedząc. W tym przypadku sam defekt ciężej zdecydowanie znaleźć niż naprawić, ale spokojnie, pokażemy co i jak. SEO Samodzielność gwarantowana!
Ta część naszego kursu dostarczy Ci skondensowanej wiedzy o stronach sierotach, które pojawiają się, kiedy prowadzisz pozycjonowanie. Wbrew pozorom wcale nie jest to obraźliwe określenie na nieudolnych specjalistów SEO. Dowiesz się, czym są orphan pages (oraz czym nie są, bo jest tu parę haczyków). Nauczysz się też krok po kroku jak ich szukać i jak je naprawiać.
Spis treści:
- Czym są orphan pages?
- Dlaczego orphan pages to nic dobrego?
- Jak powstają orphan pages?
- Sieroty, duchy i ślepe uliczki
- Jak znaleźć orphan pages? Instrukcja
- Analiza orphan pages przez Screaming Frog + API
- Inne sposoby poszukiwania orphan pages
- Jak naprawić orphan pages?
- Gdzie dodać linki?
- Wyjątki od reguły
- Podsumowanie: orphan pages to strata potencjału!
Powiązane:
Czym są orphan pages?
Najprościej: orphan pages to podstrony, do których nie prowadzą żadne linki.
Najdokładniej: orphan pages to podstrony nieposiadające żadnych lub posiadające bardzo niewiele wewnętrznych linków przychodzących. Niewidoczne z poziomu nawigacji witryny, dostępne jedynie poprzez dokładny adres URL lub w wyszukiwarce (sporadycznie także w pliku sitemap). Z reguły nie odwiedzane zarówno przez użytkowników, jak i roboty wyszukiwarki oraz trudne do odnalezienia.
Na “chłopski rozum”: orphan pages (strony-sieroty) to podstrony, których, choć powinniśmy, z jakiegoś powodu nie pokazaliśmy nigdzie użytkownikom (przez linki: ani w menu, ani w treści). Ani ludzie, ani roboty nie mogą trafić na nie ze strony, bo po prostu ich na niej nigdzie nie widać.
Zapamiętaj
Orphan pages to nie tylko podstrony pominięte w optymalizacji. Sieroty na stronie bardzo często powstają przypadkiem!
Orphan pages w porównaniach:
- Gdyby serwis internetowy był archipelagiem, sierota na stronie byłaby wysepką, do której nikt nie pływa (i o której nikt nie wie).
- Gdyby był budynkiem, strona sierota byłyby ukrytym pokojem, do którego nie prowadzą żadne drzwi.
- A gdyby strona była podręcznikiem? Sierota byłaby losowym rozdziałem, którego nie ma w spisie treści.
Okej, chyba już rozumiesz, ale trzy analogie podaliśmy nie bez powodu. Wiesz, co łączy orphan pages z nieznaną opuszczoną wysepką, ukrytym pokojem i niezaznaczonym rozdziałem? Na wszystkie z nich ciężko trafić. Nie są zbyt użyteczne, a choć ich nie widać, mogą całkiem nieźle namieszać…
Dlaczego orphan pages to nic dobrego?
Zjawisko orphan pages dotyczy praktycznie każdej większej strony internetowej i jest przy tym trochę jak wirus opryszczki. Niewidoczny, mają go praktycznie wszyscy, ale doskwiera tylko niektórym. Różnica polega na tym, że sierot możemy się pozbyć, a wirusa nie.
A jak orphan pages mogą nam szkodzić? Opcji jest kilka.
Do orphan pages nie da się dostać inaczej niż przez ręczne wpisanie dokładnego adresu URL (poza paroma wyjątkami, o których potem). W połączeniu z tym, jak działają roboty Google, sytuacja taka sprawia, że strony te często pozostają niezaindeksowane lub są trudno dostępne.
Googleboty nie mogą dowiedzieć się o ich istnieniu, lub dowiadują się “z zewnątrz”, co powoduje zjawisko crawl waste, czyli marnowania crawl budget. Z kolei brak uwzględnienia ich w strukturze serwisu zdecydowanie nie wspiera ogólnej jakości serwisu. No i nie jest też odbierany pozytywnie pod kątem użyteczności.
Wszystko to wzmacnia fakt, że zazwyczaj orphan pages to strony wątpliwej jakości lub duplicate content. Dodatkowo, jeśli będą występować nagminnie, mogą zostać odebrane za próbę manipulacji rankingiem, tzw. ghost pages, o których przeczytasz niżej.
W skrócie: orphan pages szkodzą indeksacji, zaniżają jakość i użyteczność serwisu, a w skrajnych przypadkach Google może za nie ukarać.
Jak powstają orphan pages?
Orphan pages powstają przez nieuwagę prowadzących serwis, ale też przez czysty przypadek, błędy techniczne lub przez brak optymalizacji. Zazwyczaj przyczyną jest jakiegoś rodzaju mieszanka tych przyczyn.
Przykłady?
- Wdrożenie certyfikatu SSL i nie ustawienie odpowiednich przekierowań po zamianie protokołu,
- Przypadkowe usunięcie jednego linku wewnętrznego do podstrony,
- Lub nie dodanie takiego linku po stworzeniu nowego adresu,
- Wygaśnięcie podstron (np. zawierających ogłoszenia albo tymczasową ofertę),
- Link zewnętrzny z błędem, prowadzący roboty do nieistniejącego adresu,
- Googlebot stwierdzający, że trzeba crawlować stronę zwracającą błąd 404 (co się czasem zdarza).
To tylko kilka potencjalnych przyczyn, by dać Ci jakiś ogląd. Możliwości powstawania orphan pages jest mnóstwo, a jak widzisz, niektóre są od nas kompletnie niezależne.
Zapamiętaj
Orphan pages mogą znajdować się w mapie witryny. Wówczas łatwiej je znaleźć, ale nadal stanowią problem, przez brak innych linków wewnętrznych.
Sieroty, duchy i ślepe uliczki
Orphan pages bywają często mylone z tzw. ghost pages (stronami-duchami) oraz dead-end pages (ślepymi uliczkami). Te trzy określenia, choć dość bliskie, mówią o zupełnie różnych sytuacjach. Zanim przejdziemy więc do naprawiania sierot, rozprawmy się szybko z tym tematem, dla jasności, żeby wiedzieć, z czym mamy do czynienia.
- Ślepa uliczka to podstrona, na której nie ma żadnego odnośnika (a orphan page to podstrona, do której nie prowadzi żaden odnośnik).
- Ghost pages to strony świadomie ukryte przed użytkownikami, ale dostępne dla robotów (w przeciwieństwie do orphan pages powinny być uwzględnione w strukturze serwisu).
- Technicznie rzecz biorąc orphan pages mogą być jednocześnie ślepymi uliczkami lub nawet ghost pages, ale raczej się to nie zdarza.
Tak na marginesie, ślepe uliczki, czyli dead-end pages to dzisiaj rzadkość. W erze wszechobecnych szablonów stron internetowych i CMS-ów praktycznie każdy serwis ma w obrębie całego serwisu to samo menu, stopkę czy breadcrumbs, a to przecież nic innego jak linki.
Ghost pages, czyli “Black and White” Hat SEO
W wielu miejscach w sieci można przeczytać, że ghost pages, czyli strony niewidoczne bezpośrednio w serwisie (np. w menu), a dostępne dla robotów to Black Hat SEO. Czy faktycznie? I tak i nie. Wszystko zależy, od tego, jak je wykorzystujemy.
Celem tworzenia ghost pages jest z reguły rozbudowa widoczności na kolejne frazy, przez stworzenie i optymalizacje na nie kolejnych podstron. Chodzi o takie słowa kluczowe, które mogłyby zaburzyć intuicyjność menu (np. long taile lub różne wariacje fraz już używanych). Całe clue sprawy leży jednak właśnie w optymalizacji.
Czy podstrona, która posiada unikalną treść i pozwala spełnić intencję użytkownika, jest jakkolwiek szkodliwa? No nie, jest przydatna. Nawet jeśli nie widać jej w głównym menu.
A czy szkodliwa będzie podobna, też niewidoczna w menu podstrona, ale będąca już kopią innej, na której zmieniliśmy tylko słowa kluczowe i nie zrobiliśmy nic więcej? Tak, bo będzie to duplikacja i manipulacja rankingiem.
W obu przypadkach mamy do czynienia z ghost pages. W pierwszym mamy jednak po prostu kolejną, bardziej szczegółową i użyteczną stronę, a w drugim spam, próbę oszukania Google i zero wartości dla użytkownika.
Reasumując: Ghost pages to technika w pełni bezpieczna, jeśli nie pomieszamy jej z innym Black Hat SEO, takim jak cloaking czy keyword stuffing. Najważniejsze, żeby na pierwszym miejscu stał użytkownik, a dodatkowa podstrona była dla niego użyteczna.
Na idei użytecznych ghost pages tworzymy tzw. ukryte kategorie, które stosujemy z powodzeniem w prowadzonym przez nas pozycjonowaniu sklepów internetowych. Więcej o tej technice znajdziesz w webinarze Praktycy SEO: Rozwiń swój sklep internetowy, przeprowadzonym przez Marcina, CEO & Head of SEO Top Online.
Jak znaleźć orphan pages? Instrukcja
Znalezienie orphan pages nie należy do najprostszych, ale nie jest to też żadna wyższa matematyka. Przejdźmy do rzeczy.
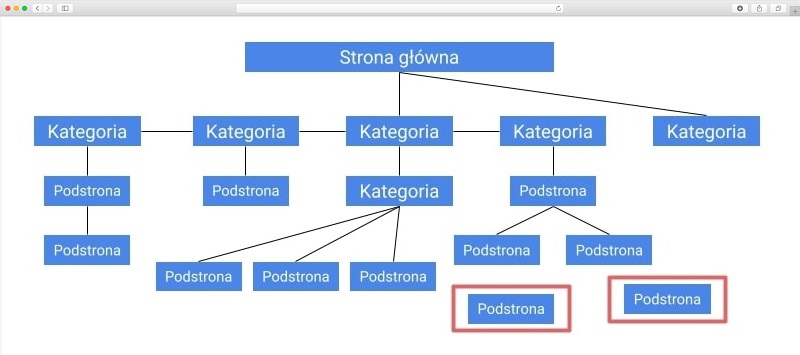
1. Lista adresów dostępnych dla crawlerów
Na początek naszych poszukiwań będziemy potrzebować listy wszystkich adresów URL, które są możliwe do odnalezienia przez roboty, tj. mają linki i są indeksowalne. Do tego przyda się nasz własny robot (SEO-crawler), który przeskanuje dla nas serwis, np. Screaming Frog.
Zapamiętaj
Alternatywy dla Screaming Frog to m.in.: Visual SEO Studio i Sitebulb Website Crawler.
Niezależnie od użytego programu, ważne żeby crawlowanie serwisu nie obejmowało adresów niezindeksowanych i ukrytych przed wyszukiwarką poprzez robots.txt albo meta tagi.
Skan zaczynamy od strony głównej, używając pełnych, kanonicznych adresów (odpowiednio z HTTP/HTTPS i WWW lub bez WWW). Efektem powinna być lista wszystkich dostępnych dla Google adresów w naszym serwisie.
Eksportujemy znalezione adresy do Google Sheets lub Excela.
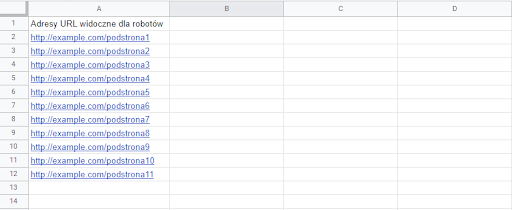
2. Lista adresów z Google Analytics
Skoro mamy adresy do których mogą dostać się roboty, potrzebujemy jeszcze listy wszystkich URL-i w serwisie. A jako że crawlery z definicji nie znajdą nam nielinkowanych stron, bo poruszają się po linkach, musimy poszukać inaczej.
Jeśli serwis nad którym pracujemy jest śledzony przez Google Analytics lub inne narzędzie analityczne, to jesteśmy w domu. Sprawa jest prosta. Jeśli dany adres URL został choć raz odwiedzony przez kogokolwiek lub cokolwiek (Googlebota lub inne roboty), to powinniśmy móc “wyciągnąć” go z narzędzia.
W Analytics:
- Wchodzimy kolejno w “Zachowanie” > “Zawartość witryny” > “Wszystkie strony”.
- Ustawiamy datę zakresu danych maksymalnie w przeszłość (by objąć wszystkie dostępne dane).
- Sortujemy jeszcze otrzymaną listę pod względem liczby odsłon, od najmniejszej do największej.
- Tak otrzymane URL-e eksportujemy i wklejamy do naszego Google Sheets lub Excela.
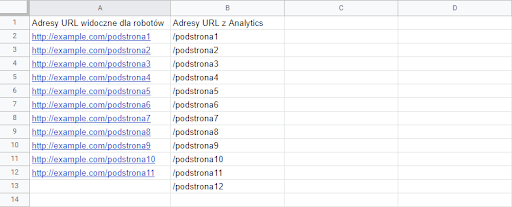
3. Przygotowanie i porównanie danych
Skoro mamy już listę (potencjalnie) wszystkich istniejących adresów i listę adresów mających linki, to praktycznie mamy już nasze sierotki. Pozostaje tylko porównać ze sobą te dane i znaleźć różnice. Zanim jednak do tego przejdziemy, sprowadźmy nasze URL-e do tej samej (porównywalnej postaci).
By to zrobić, do adresów z Analytics musimy dodać naszą domenę z właściwym protokołem, dodając jeszcze jedną listę wypełnioną samą domeną i łącząc ją z listą z Analytics. Brzmi strasznie, ale to nic trudnego, co widać najlepiej na screenshocie.
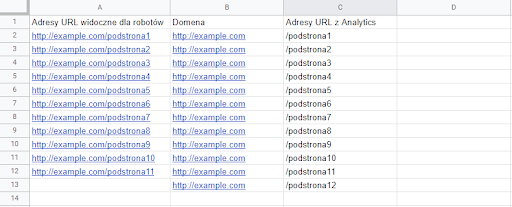
Następnie, w kolejnej kolumnie do gry wchodzi formuła =CONCAT(B2;C2), czyli połączenie wskazanych wartości: domeny i adresu. Przeciągamy formułę w dół i gotowe, mamy listę porównywalnych URL-i.
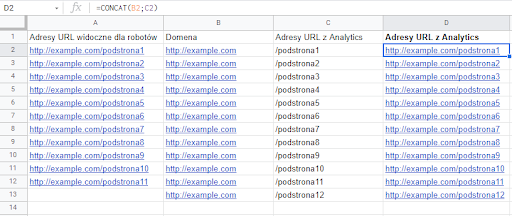
No to cóż, pozostaje porównać. Dla Google Sheets sprawę załatwia następująca formuła: =MATCH(A2;$D$2:$D$13;0)
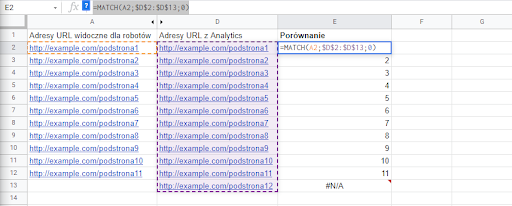
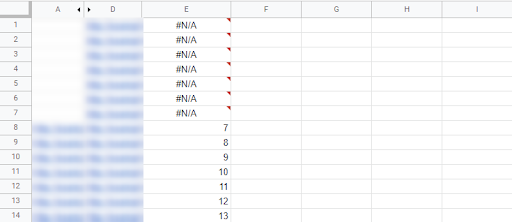
Formuła ta sprawdza, czy wartość (adres) znajdująca się w komórce A2 znajduje się w zakresie danych D2:D13, czyli na liście adresów mających linki. Jeśli tak, zwraca jej pozycję w zakresie, a jeśli nie, zwraca błąd, czyli “#N/A”. Wystąpienie błędu dla danego adresu będzie znaczyć, że jest on jedną z istniejących w naszym serwisie orphan pages.
*Wyjaśnienie do formuły =MATCH:
Znaki dolara tworzą tutaj wartość stałą, która dzięki temu nie zmienia się przy przeciągnięciu formuły do wierszy niżej. Wartość “0” na końcu formuły jest z kolei wskazaniem typu wyszukiwania, wymaganym, zgodnie z dokumentacją Sheets, gdy przeszukiwany zakres nie jest posortowany.
W przykładzie wszystko widać gołym okiem, ale przy prawdziwych danych warto jeszcze na koniec posortować arkusz. W Google Sheets będzie to kolejno “Dane” > “Sortuj arkusz” > “Od Z do A”, oczywiście przy zaznaczonej kolumnie wyników porównania.
Analiza orphan pages przez Screaming Frog + API
Screaming Frog pozwala podpiąć dane z Analytics oraz Search Console poprzez API. Przy takiej integracji poszukiwanie orphan pages można przeprowadzić bez korzystania z arkuszy kalkulacyjnych. Narzędzie posiada nawet dedykowany im filtr danych.
By przeprowadzić taką analizę, crawlujemy kolejno z uwzględnieniem (konfiguracja): wszystkich istniejących na stronie map witryn oraz nowych adresów odkrytych przez Search Console i Analytics. Po crawlowaniu całej strony z uwzględnieniem danych z konsoli i analityki trzeba będzie też dodatkowo przetworzyć dane (zakładka “Crawl Analysis”).
Screaming Frog porówna wówczas za Ciebie zebrane dane wskaże Ci orphan pages. Będą one dostępne w zakładkach “Sitemaps”, “Analytics” i “Search Console” (będzie tam figurował odpowiedni filtr).
Poza tym, dodatkowo, możesz szukać ich też ręcznie, w zakładce z wszystkimi adresami (“Internal”). Na osierocenie wskazywać może tutaj pusta wartość “crawl depth” dla poszczególnych URL-i. Przefiltruj dane wg. tej wartości na sam koniec i porównaj z tym, co udało Ci się odkryć wcześniej pod filtrem orphan pages.
Pełna, szczegółowa instrukcja jest dostępna na stronie narzędzia: https://www.screamingfrog.co.uk/find-orphan-pages/
Inne sposoby poszukiwania orphan pages
Poza tymi dwoma podstawowymi sposobami, orphan pages znaleźć możesz jeszcze z pomocą innych, płatnych narzędzi SEO. Nie polecimy tu niczego konkretnego, ale wskażemy gdzie szukać. Dwa najpopularniejsze rozwiązania posiadające dedykowane temu moduły lub po prostu uwzględniające sieroty na stronie w audytach to SemRush i Ahrefs.
Poza nimi orphan pages pozwalają zidentyfikować też m.in. MajesticSEO, Sitechecker, Moz, OnCrawl, Botify czy RavenTools. Dla WordPressa, właściwą funkcję ma też YoastSEO w wersji premium.
Nie polecamy jednak wykupywać abonamentu do narzędzi tylko po to by szukać sierot. Szczególnie jeśli chciałbyś/abyś rzucić się na taki pomysł przez to, że Twoja strona nie ma podpiętej analityki czy Google Search Console. W takim przypadku zacznij od początku, czyli od wdrożenia śledzenia i podstawowej optymalizacji, a sieroty zostaw sobie na później.
Jak naprawić orphan pages?
Najkrótsza odpowiedź brzmi: dodając do nich linki. W praktyce jednak wszystko zależy od tego, jak dane orphan pages powstały i co chcemy z nimi zrobić. Poza dodawaniem linków zawsze można jeszcze usunąć lub zastosować przekierowanie, czasem nie trzeba też robić absolutnie nic.
Lista konkretnych przypadków orphan pages i ich rozwiązań:
- Wysokiej jakości, zoptymalizowane i ważne dla serwisu podstrony bez linków wewnętrznych, będące efektem zaniedbania, pomyłką lub błędem automatyzacji.
Rozwiązanie: dodajemy linkowanie wewnętrzne do znalezionej podstrony.
- Podstrony pozostałe po migracji serwisu, wdrożeniu SSL i wszelkie nielinkowane wewnętrznie duplikaty (w tym te powstające przez trailing slash).
Rozwiązanie: Przekierowanie 301, jeśli mamy na stronie podobną treść, do której możemy przekierować. Jeśli nie, usuwamy zawartość (serwer powinien zwracać kody 404 lub 410).
- Usunięte podstrony, które nadal zwracają treść (np. usunięto produkt z katalogu, ale nie samą podstronę, adres nadal istnieje).
Rozwiązanie: Usunięcie podstrony, tj. upewnienie się, że adres zwraca kod 404 lub 410, ew. przekierowanie 301, jeśli strona ma jakiś ruch.
- Strony, które już nie istnieją, ale posiadają backlinki, przez co Google stara się je odwiedzić.
Rozwiązanie: Jedyny sposób na pozbycie się takiej stron-widmo, to odezwanie się do administratora serwisu, z którego wychodzi błędny lub nieaktualny link. No i oczywiście prośba o usunięcie linku lub zamienienie go na inny.
- Adresy nieistniejące i usunięte (404/410) lub przekierowanie (30x).
Rozwiązanie: Czas. Jeśli nic nie linkuje do usuniętych lub przekierowanych przez nas adresów to prędzej czy później boty Google przestaną je odwiedzać. Nie ma się więc czym przejmować, chyba że pod danym URL-em powinno coś ciągle być.
- Podstrony powstałe przez błędy systemów, np. w trakcie generowania map witryn lub linków kanonicznych.
Rozwiązanie: Tutaj niestety, trzeba będzie sięgnąć głębiej, tj. zgłosić problem do supportu platformy (CMS/SaaS) lub programiście odpowiadającemu za stronę (rozwiązania dedykowane).
Gdzie dodać linki?
Przede wszystkim w treści. W tej kwestii nikt tak dobrze jak Ty nie będzie wiedział, skąd najlepiej podlinkować daną podstronę w serwisie. Jeśli Twoja strona jest już zindeksowana, w poszukiwaniu właściwego miejsca możesz też wspomóc się wyszukiwarką. Wystarczy zastosować operatory zaawansowane Google, a konkretnie “site:twojadomena.pl keyword”.
Dodatkowo, w ramach wzmocnienia linkowania wewnętrznego, polecamy sprawdzić Leksykon - autorskie rozwiązanie Top Online, które możesz wdrożyć na swojej witrynie. To nic trudnego, a przy odrobinie kreatywności leksykon pozwoli Ci naturalnie podlinkować praktycznie każdą podstronę.
Wyjątki od reguły
Cały ten artykuł trzyma się raczej narracji mówiącej: “orphan pages są złe, musimy się ich pozbyć”. Tak zwykle jest, ale nie moglibyśmy zostawić Was bez wspomnienia o wyjątkach. Jest ich niewiele, ale nadal, istnieją.
Zamierzonymi i pożądanymi orphan pages mogą być np. stworzone specjalnie dla danej kampani landing pages. Nie będziemy do nich linkować, technicznie rzecz biorąc będą więc “osierocone”. W praktyce jednak nie będą szkodzić, ba, będą przekierowywać na resztę serwisu mnóstwo płatnego ruchu, bo właśnie do tego zostały stworzone.
W takim wypadku sierota na stronie, choć pasuje do technicznej definicji, nie musi, a często wręcz nawet nie powinna być naprawiana.
Przy okazji, jeśli zdarzyłoby Ci się znaleźć u siebie orphan pages z dużym ruchem organicznym, to najpewniej jest to źle zidentyfikowany ruch płatny z Google Ads (np. przez brak parametru w URL-ach). Oczywiście sierotki mogą być (i często są) widoczne w Google, ale przez brak prowadzących do nich linków (czyli brak połączenia z resztą strony) mają raczej bardzo mierne pozycje.
Jeśli w trakcie analizy trafił Ci się taki kwiatek, a poza prowadzeniem SEO nigdzie się nie promujesz, lub zwyczajnie, nie wiesz o co chodzi, daj nam znać na grupie SEO Samodzielni na Facebooku. Rozpracujemy to razem :)
Podsumowanie: orphan pages to strata potencjału!
Aby podsumować, wspomnimy jeszcze o innej stronie medalu, czyli o tym, że orphan pages mogą mieć też znaczenie pod kątem biznesowym, poza negatywnym wpływem na SEO. Możliwe, że sierota na stronie, gdyby tylko była właściwie linkowana, generowałaby (albo i generowała już w przeszłości!) dodatkowy ruch, a co za tym idzie, także leady i sprzedaż.
Pomyśl o tym w ten sposób: Nawet jeśli na taką jedną orphan page trafiłoby tylko 10 osób miesięcznie, a w skali roku przyniosłoby Ci to tylko 2 dodatkowych Klientów. Lepiej mieć dwóch dodatkowych Klientów czy nie? Mało kto odmówi. Tym bardziej, że często wystarczy jednorazowe poprawienie linkowania, a zyskujesz i czysto technicznie (SEO) i biznesowo. Plus, w praktyce, skala, zarówno ilości osieroconych podstron, jak i odzyskanych po ich naprawieniu efektów, jest zazwyczaj o wiele, wiele większa.
No i jeszcze na sam koniec, klasyczne SEO-przypomnienie:
Zapamiętaj
Systematyczna analiza orphan pages (np. raz na pół roku) pozwala uniknąć usunięcia z Google wartościowych, konwertujących stron!
Wbrew pozorom nieopatrzne usunięcie linku wewnętrznego wcale nie jest takie rzadkie, a z czasem, może skutkować zmniejszeniem crawlowania podstrony i wyindeksowaniem adresu. Wniosek: nie ryzykuj, dodaj orphan pages do swojego audyt SEO!
Powodzenia w analizie! :)
Z tego artykułu dowiedziałeś się:
- Czym są i czym nie są orphan pages
- Jak szukać orphan pages i jak je naprawiać
- Kiedy sieroty na stronie nie stanowią problemu
Autorzy artykułu
Zespół Top Online
Adam Przybyłowicz
Product Lead i specjalista od researchu i rozwoju w Top Online. Zdobywa dla nas wiedzę, szuka nowych rozwiązań i pracuje nad tym, żebyśmy nie zostali w tyle. Prowadzi zespół tworzący m.in. YOSA.AI.


