
Roboty internetowe są bardzo różne. Niektóre dbają o nasze bezpieczeństwo czy z nami czatują, inne napędzają wyszukiwarki, a jeszcze inne starają się złośliwie zużyć nasz budżet reklamowy lub zawiesić nam serwer. Tak czy inaczej - nie ma już internetu bez botów, więc skoro się w nim obracamy, dobrze co nieco o nich wiedzieć.
W tej części SEO Samodzielnych przedstawiamy zagadnienie robotów internetowych w kontekście, a jakżeby inaczej, SEO. Opowiadamy o tym, czym jest robot internetowy i jak działa. Wyjaśniamy, dlaczego Google bot jest tak ważny w pozycjonowaniu oraz pokazujemy jak zablokować roboty internetowe (oraz kiedy warto to robić).
Spis treści:
- Czym jest robot internetowy?
- Roboty internetowe to niemal połowa ruchu
- Jak działają wyszukiwarki internetowe?
- Jak działa robot wyszukiwarki?
- Zły robot internetowy
- Złe roboty internetowe - klasyfikacja
- Atakujące roboty internetowe
- Dobre roboty internetowe - rodzaje
- Dygresja: boty, keywordy i wolumeny
- Jak zablokować roboty internetowe?
- Jak zablokować roboty bez wartości User-Agent?
- Kiedy blokować roboty internetowe?
- Jak sprawdzać roboty internetowe?
- Nie tylko Google robot
Powiązane:
Czym jest robot internetowy?
Słysząc “robot”, lubimy myśleć o wszelkich humanoidach, takich jak C-3PO z Gwiezdnych Wojen, T-800 z Terminatora czy Bender z Futuramy. Często na to słowo pojawiają się też skojarzenia z tymi bardziej “robocimi” robotami znanymi z kultury, jak słynny R2D2 czy Wall-E. Co po niektórym do głowy przychodzą za to widziane czasem w mediach roboty Boston Dynamics, z najbardziej rozpoznawanym robo-psem o nazwie Spot na czele.
Robot internetowy nie ma jednak żadnej fizycznej prezencji (poza serwerem, na którym operuje). Mówiąc najprościej, jest to program wykonujący zgodnie z wytycznymi zadane mu instrukcje. Oprogramowanie stworzone do określonego celu, zwykle do przeglądania stron internetowych i wykonywania w ich obrębie specyficznych dla siebie czynności.
To właśnie ze względu na poruszanie się po witrynach roboty internetowe znane są też pod innymi nazwami. Crawlery (crawler - gąsienica, pełzacz), pająki (web spider), po prostu boty lub “sieciowi wędrowcy” (web wanderers) - to wszystko roboty internetowe, w tym najpowszechniej przytaczany w kontekście SEO robot wyszukiwarki.
Zapamiętaj
Robot internetowy (web crawler) to bot, który poszukuje, przegląda i indeksuje treści w internecie. Zasadniczo, jest odpowiedzialny za zrozumienie treści na stronie, tak, by dało się ją sklasyfikować w indeksie.
Istnieją też boty inne, funkcjonujące wyłącznie w obrębie danej strony, np. czatboty, ale w artykule tym będziemy skupiać się głównie na botach “chodzących” po naszych stronach i na tym, jak mogą one oddziaływać, tak na nie, jak i na ich pozycjonowanie.
Roboty internetowe to niemal połowa ruchu
W tym roku roboty internetowe (wszystkie, nie tylko te wyszukiwarki) odpowiadają za 42,3% całego ruchu w sieci (wszystkich wyświetleń, sesji, kliknięć, odtworzeń czy pobrań). Więcej niż co czwarte odwiedzenie każdej strony w sieci jest więc odwiedzinami robota, który przychodzi tam zwykle po jakieś konkretne informacje.
Informacja ta zwykle jest szokująca lub dociera do świadomości z opóźnieniem. Zamieszczamy ją, żeby zaznaczyć wyraźnie, że robot internetowy to nie jakaś nowinka czy jeden trybik w maszynie, ale integralna, ważna i właściwie niezbywalna już część sieci.
Jako że w tytule tego tekstu wspominamy o blokowaniu robotów, a tutaj posługujemy się statystyką, dorzućmy jeszcze przy okazji do pieca. Gotowi? Z tych 42,3% ruchu za który odpowiadają boty, aż 27,7% to ruch generowany przez tzw. złe roboty internetowe - sklasyfikowane jako intencjonalnie szkodliwe lub niebezpieczne.
Dla dociekliwych: dane pochodzą z dostępnego za darmo raportu “2022 Bad Bot Report” firmy Imperva.
Jak działają wyszukiwarki internetowe?
Żeby opowiedzieć, jak dokładnie działają Google roboty, musimy zrobić szybki krok w tył i opowiedzieć jak działają wyszukiwarki internetowe. Generalnie, Google (jak i praktycznie każda duża współczesna wyszukiwarka) działa w 3 etapach: skanując, indeksując i wyświetlając wyniki.
Skanowanie to etap, w którym wykorzystywane są właśnie nasze roboty internetowe, a konkretnie jakiś robot wyszukiwarki (dla Google będzie to zwykle Googlebot imitujący użytkownika odwiedzającego serwis z urządzenia mobilnego). Skanując, wyszukiwarka wykorzystuje boty do przeczesywania sieci i odnajdywania coraz to kolejnych stron. Głównie za pomocą linków.
Indeksowanie strony, czyli etap kolejny, zachodzi w trakcie gdy robot internetowy odwiedza daną stronę. Pobiera on jej zawartość, analizuje ją i zapisuje (lub nie) w indeksie, czyli bazie danych, z której dobierane są wyniki wyszukiwania. To właśnie wówczas do gry wchodzą słynne algorytmy Google, według których postępują roboty.
Wyświetlanie wyników wyszukiwania jest z kolei etapem końcowym, w którym na zapytanie wpisane w wyszukiwarce przez użytkownika zwracane są pasujące najlepiej (wg. algorytmu) wyniki - prosto z indeksu. Tutaj generowane są tzw. SERP-y, czyli Search Engine Result Pages, strony wyników.
W tym miejscu trzeba jeszcze dodać, że Google boty odwiedzają stronę cyklicznie, żeby sprawdzić jej status i zaktualizować zawartość w indeksie. Całość jest oczywiście maksymalnie uproszczona, ale jak widać, robot internetowy tworzy w pewnym sensie krwioobieg wyszukiwarki. Bez niego nic nie mogłoby działać.
A czy Google bot może szkodzić stronie?
Takie pytanie nasuwa się szybko gdy połączymy kropki odnośnie “złych botów” i robotów wyszukiwarki. Odpowiedź brzmi, jak ze wszystkim w SEO: to zależy. W teorii Google bot może szkodzić, obciążając nadmiernie serwer swoimi odwiedzinami. W praktyce jednak, analogicznie do innych operatorów wyszukiwarek, firma robi wszystko, by temu zapobiegać.
Google roboty są zaprogramowane tak, by nie indeksować witryn zbyt szybko. Nie przeciążają więc nadmiarem żądań. Spowalniają również cały proces, jeśli w odpowiedzi od serwera uzyskają kody błędów HTTP 500. Według dokumentacji, Google posiada też jest “wyrafinowane algorytmy pozwalające zdeterminować optymalną prędkość crawlowania Twojej strony”.
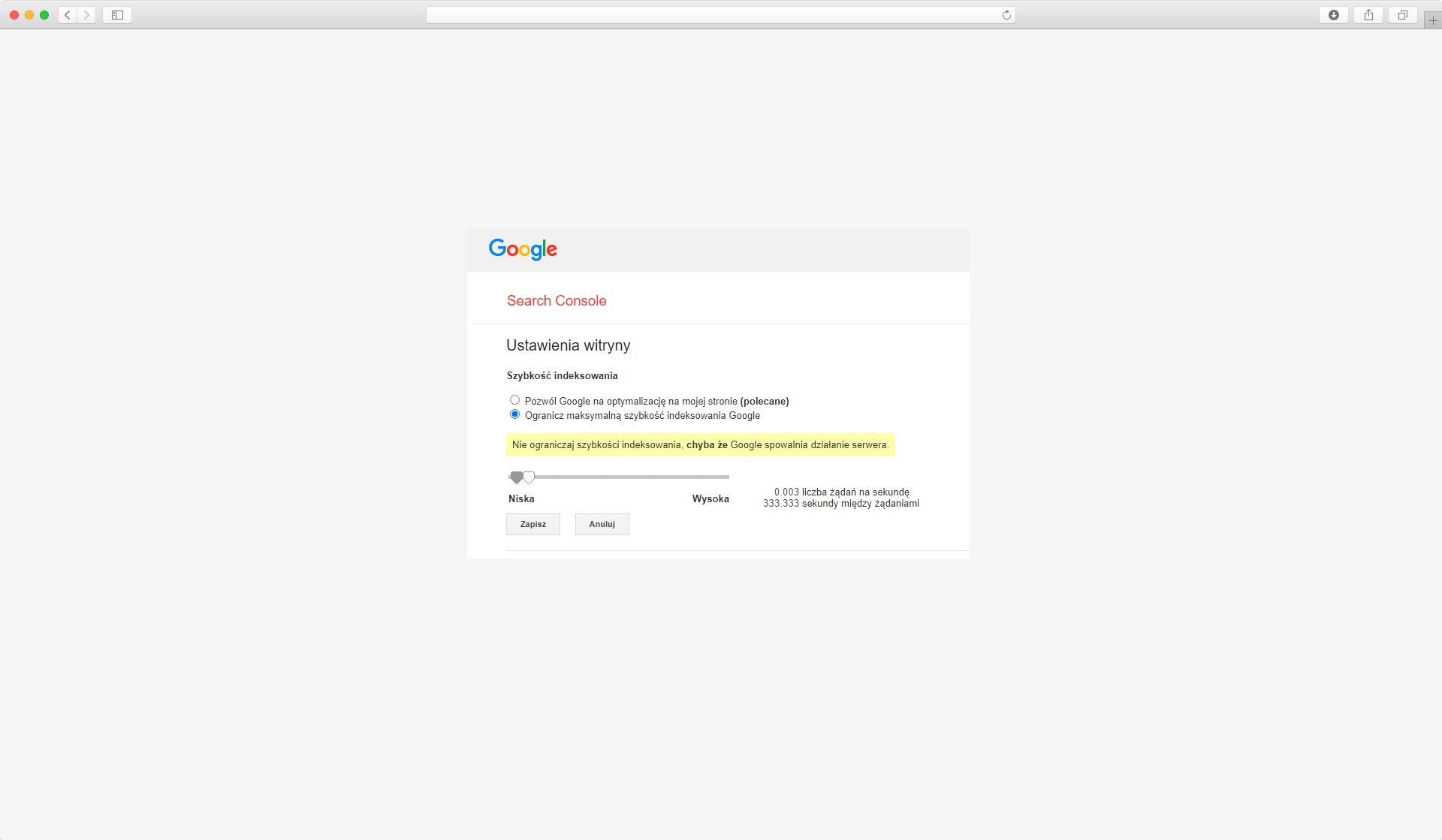
Z doświadczenia wiemy, że zwykle problem stanowi to, że Google odwiedza stronę zbyt rzadko. Mimo wszystko, jeśli faktycznie zdarzyłaby się sytuacja przeciążania witryny przez boty, Google zostawia furtkę. Pod postacią narzędzia służącego do ograniczania maksymalnej szybkości indeksowania w Search Console.
Jak działa robot wyszukiwarki?
Zasadniczo robot wyszukiwarki odnajduje adresy stron, odwiedza je rozpatrując przy tym najpierw plik robots, a potem skanuje ich zawartość i decyduje o indeksowaniu lub nie. Crawlery w większości przypadków zachowują też odnalezione w rozpatrywanej aktualnie treści linki zewnętrzne i wewnętrzne, by podążyć za nimi w dalszych działaniach.
Robot wyszukiwarki może także posługiwać się plikiem sitemap.xml i wykorzystywać (poza robots.txt) inne elementy tzw. Robots Exclusion Protocol, czyli meta tagi na podstronach oraz atrybuty linków.
Co warto mieć z tyłu głowy: roboty internetowe są co prawda programami, ale nie są banalne i trudno je oszukać. Potrafią w pełni autonomicznie m.in. określać hierarchię adresów w strukturze podstron i jej znaczenie oraz rozumieć treść. Na podstawie historii odwiedzin i wprowadzanych zmian w indeksie są też w stanie dostroić częstotliwość swoich wizyt do tego jak często aktualizujesz stronę. A to tylko kilka przykładów.
Jako dobrą lekturę uzupełniającą polecamy część SEO Samodzielnych pt. Crawl budget - moc przerobowa robotów Google.
Który Google robot skanuje moją stronę?
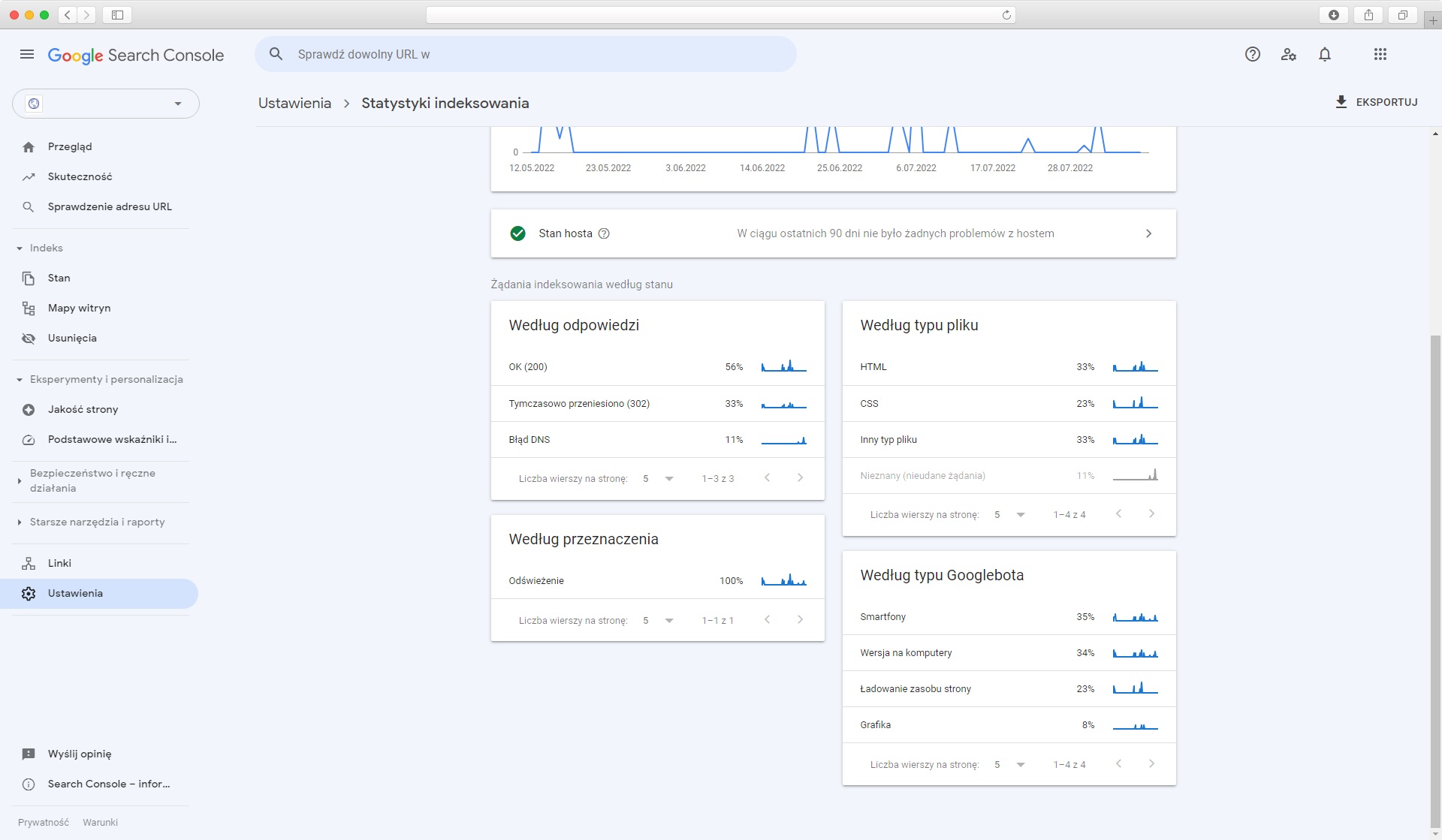
Google to nie tylko jeden uniwersalny robot wyszukiwarki, a kilka osobnych systemów. Dokładnie, Google wykorzystuje co najmniej 8 typów botów, spośród których można wyróżnić 18 konkretnych robotów.
Najczęściej, za ogólne crawlowanie stron odpowiada przede wszystkim Googlebot Smartphone imitujący użytkowników smartfonów (od aktualizacji Mobile First). Sporadycznie stronę może analizować też jednak głównie Googlebot desktop, imitujący użytkownika komputera.
Google boty odwiedzające witryny rzadziej to między innymi Googlebot image odpowiedzialny za indeksowanie zdjęć do Google Grafika, Googlebot video indeksujący filmy, Googlebot Ads weryfikujący jakość reklam na stronie czy Googlebot News pobierający nowinki do Google News.
To, jakie boty Google odwiedzają serwis, można prześledzić w logach serwera, oraz w Search Console, w raporcie Statystyki Indeksowania.
Zły robot internetowy
Właściwie, robot internetowy z definicji nie jest ani zły, ani dobry - koniec końców to oprogramowanie, które realizuje postawione przed nim zadania. No ale filozofia na bok: jak to rozróżnić? Nie ma definicji dla złych robotów internetowych, ale zasada jest dość prosta: jeśli dany bot szkodzi jakkolwiek lub może szkodzić Twojej stronie, warto uznać go za tego “złego”.
Gdybyśmy mieli to ująć w jedno zdanie, pewnie brzmiałoby ono “zły robot internetowy wykonuje zautomatyzowane zadania ze złośliwym zamiarem”. Same poszukiwania tego, jakie boty odwiedzają witrynę i co na niej robią, przeprowadzamy, analizując logi serwera.
Złe roboty internetowe - klasyfikacja
Zły robot internetowy nie jest zwykle prosty i oczywisty do wychwycenia. Zazwyczaj stara się jak najlepiej imitować użytkownika, często nawet do poziomu w którym podobnie do człowieka porusza kursorem w trakcie sesji.
Naturalnie, nie będzie miał żadnej etykietki mówiącej “jestem złym botem, zablokuj mnie” - żeby go zidentyfikować, trzeba będzie prześledzić jego akcje i historię wizyt. Tylko właśnie, czego w niej szukać? Poniżej klasyfikacja, która powinna dać Ci solidny ogląd.
Clickbot - roboty internetowe, które klikają
Clickbot (lub Fraudbot) to robot internetowy, który ma za zadanie klikać w płatne reklamy, imitując przy tym możliwie jak najwierniej użytkownika. Takie roboty internetowe można spotkać na stronie wówczas, gdy serwis udostępnia przestrzeń reklamową w ramach AdSense. Nie szkodzą one oczywiście bezpośrednio samej stronie, a reklamodawcom, których komunikaty są na niej akurat wyświetlane w ramach systemu reklamowego.
Clickbot ma za zadanie wykradać budżet marketingowy i zaburzać statystyki. Niestety nie da się przed nim w 100% uchronić, ale istnieją sposoby zapobiegania - np. poprzez wykluczanie adresów IP w kampaniach Ads.
Naturalnie, ze względu na charakter bota, blokowanie z poziomu strony właściwie nie jest tutaj możliwe. Zresztą, nie specjalnie nawet by pomogło, bo jeśli promowany serwis działa w AdSense to system nie będzie wyświetlać przecież reklam naszej strony na niej samej.
Zapamiętaj
Złośliwy robot internetowy rzadko jest dzisiaj jednym botem. Zwykle są to tzw. botnety, często działające poprzez wykorzystanie urządzeń nieświadomych niczego użytkowników (poprzez Malware).
Download bot - roboty do pobierania
Clickbot ma klikać, download bot - pobierać. Tutaj nie trzeba chyba zbyt wiele tłumaczyć. Jeśli hostujemy jakieś zasoby na stronie, na których popularności lub dostępności nam zależy (np. darmowy e-book), to download boty mogą zaburzać nam statystyki i przeciążać serwer. W tym przypadku analiza jest już jednak łatwiejsza, bo mamy do czynienia z powtarzalną czynnością w obrębie naszego serwisu.
Content scraper
Content scraper to typ bota, który technicznie rzecz biorąc - również pobiera, ale nie hostowane przez nas pliki, a zawarte na stronie treści (lub całe podstrony). Poza pobieraniem przetwarza także treści w jakichś określonych celach, np. wtórnego publikowania artykułu ze spamowymi linkami.
Content scrapery są również wykorzystywane do agregacji danych, np. z katalogów stron internetowych czy baz firm. Tam również pobierają one treści, z tym że przetwarzają je, by np. tworzyć bazy mailingowe lub bazy adresów i personaliów.
Price scraper
Price scraper także jest content scraperem, ale specyficznym. Ten robot internetowy porusza się przede wszystkim po sklepach internetowych, a jego zadaniem jest przechwytywanie cen produktów czy usług (często dynamicznych, jak np. przy lotach czy noclegach).
Co jest w tym złośliwego? To, że roboty internetowe tego pokroju mogą być częścią algorytmów dostosowujących ceny (szczególnie popularnych w branżach “okołoturystycznych”). Takie boty stają się w nich aparatami nieuczciwej konkurencji, dzięki którym “ich” cena będzie zawsze odrobinę korzystniejsza od konkurencji. Nie ważne, jak dobry nie byłby system dobierania ceny do użytkownika, zawsze będą o jeden nieuczciwy krok do przodu.
Spambot
Spambotów nikomu tłumaczyć za bardzo nie trzeba. Widoczne nadal m.in. na YouTube czy Facebooku (a jeśli korzystasz z Messengera, to pewnie masz kilka takich robotów w folderze “Inne” w swoich czatach). Obecnie bardzo rzadko spotykane na stronach internetowych ze względu na… brak możliwości komentowania czy umieszczania wpisów na większości prywatnych witryn firmowych.
Tam, gdzie napisać coś się da, przed spambotami jesteśmy już w dużej mierze zabezpieczeni. W sklepach zwykle można wystawiać opinie, ale do tego potrzebne jest konto i wcześniejsze dokonanie zakupu ocenianego produktu co równa się weryfikacji. Wiele stron mających opcje komentowania korzysta też ze sprawdzania wpisów przed ich publikacją. Bardzo popularne jest również implementowanie świetnie zabezpieczonych zewnętrznych rozwiązań, jak np. najpopularniejszy wśród nich Disqus.
Spamboty mają dziś ciężko, a nawet jeśli się im udaje - są banalnie łatwe do wychwycenia - bo z założenia już ich działalność ma być przecież widoczna gołym okiem.
Grinchbot
Grinchbot, tak samo jak Grinch, psuje wszystkim zabawę. Ten rodzaj robota internetowego ma na celu wykupić limitowane przedmioty: jak buty, bilety czy wszelkie inne przedmioty kolekcjonerskie. Korzystają z niego nieuczciwi resellerzy, czyli osoby zarabiające na wykupywaniu i odsprzedawaniu limitowanych dóbr.
Ten rodzaj bota jest problemem dla bardzo wąskiej grupy sprzedawców. Jeśli jednak handlujemy w sieci i opieramy kampanie reklamowe na bardzo korzystnych i limitowanych promocjach cenowych - warto czasem zajrzeć w logi i przyjrzeć się temu, jak tak przeceniane produkty się wyprzedają.
W przypadku produktów fizycznych wykorzystanie Grinchbota zdradzać może również powtarzający się adres do wysyłki - ale to tylko wskazówka, którą i tak trzeba potwierdzić analizą dziennika.
Fałszywy robot wyszukiwarki
Na pierwszy rzut oka Google bot czy Bing bot, a tak naprawdę dowolny złośliwy (szkodliwy), maskujący się w ten sposób robot internetowy. Wspominaliśmy o tym przy Clickbotach - wiele programów stara się imitować użytkowników lub inne znane crawlery. Niektóre boty mają też pustą wartość User Agent - w ten sposób starają się uniknąć wykrycia przez oprogramowanie tworzące statystyki odwiedzin i utrudniają blokowanie.
Tutaj pomaga zwykle weryfikacja adresów IP niepokojących nas pająków. Większość wyszukiwarek i dostawców oprogramowania crawlujących internet dostarcza listy adresów, z których pochodzą ich roboty.
Przykładowo, Google ma całą poświęconą temu stronę pomocy: https://developers.google.com/search/docs/advanced/crawling/verifying-googlebot?hl=pl
Atakujące roboty internetowe
Początkowo sekcja ta miała być elementem powyższej klasyfikacji, ale ostatecznie uznaliśmy, że tego rodzaju botom należy się “specjalne miejsce”. Nie są to typowe roboty internetowe przewijające się codziennie przez sieć, a boty używane do cyberataków.
Credential stuffing bot
Credential stufiing to rodzaj ataku polegający na masowym dopasowywaniu do siebie wykradzionych informacji identyfikacyjnych. Przykładowo: jeśli oszust pozyska skądś dwa adresy mailowe, trzy hasła i dwie nazwy konkretnego użytkownika, to poprzez credential stuffing może spróbować błyskawicznie użyć wszystkich ich kombinacji. W nawet setkach portali na raz.
Po stronie witryny udostępniającej logowanie, przed atakami takich botów można bronić się, przede wszystkim, ograniczając liczbę żądań uwierzytelniania / prób logowania. Warto też dbać o aktualizowanie wszelkich zabezpieczeń. No i żeby zapobiegać, zamiast leczyć - tam, gdzie to tylko możliwe, wprowadzać można uwierzytelnianie dwuskładnikowe.
Account creation bot
Account creation bot to robot internetowy stworzony do tworzenia - nowych kont na stronach. Często w celu autonomicznego poszerzania sieci spambotów czy clickbotów, ale i po to, by wykorzystywać maksymalnie bonusy dostępne dla nowych użytkowników.
Tego rodzaju boty są zmorą przede wszystkim dla operatorów e-mail oraz dla portali social media. Jeśli oferujesz jednak jakieś naprawdę korzystne bonusy za rejestrację niewymagające zakupu czy skorzystania z usługi, warto mieć się na baczności.
Carding bot
Tego rodzaju roboty internetowe są nieco podobne do botów wykorzystywanych w atakach typu credential stuffing lub password spraying. Nie próbują jednak uzyskać dostępu do kont użytkowników, a usiłują autoryzować kradzione dane kart kredytowych. W tym wypadku boty wchodzą jednak do gry w momencie przekierowania do płatności, w lwiej części obsługiwanych dzisiaj przez zewnętrzne bramki płatnicze. Poza dbaniem o zabezpieczenia i aktualność naszych CMS-ów wiele więc tutaj nie zdziałamy.
DoS bot
DoS bot (denial of service - blokada usługi) służy do przeprowadzania najbardziej rozpoznawalnych chyba cyberataków - ataków DDoS (distributed denial of service - rozproszona blokada usługi). Dla ścisłości: DDoS to odmiana ataku DoS przeprowadzana z wielu miejsc naraz.
Kwestia ochrony przed atakami DDoS to temat rzeka, w praktyce jednak gdy nie posiadamy rozwiązań dedykowanych, to po naszej stronie pozostaje jedynie dbanie o aktualność CMS oraz niekorzystanie z niepewnych szablonów czy wtyczek. Istotna jest też klasyczna higiena internetowa odnośnie korzystania z maila, klikania w linki czy aktualizowania oprogramowania urządzeń - nie bagatelizujmy tego, tak w domu, jak i w firmie.
Dobre roboty internetowe - rodzaje
Analogicznie do botów złych, stworzone w różnych celach roboty internetowe znajdują się też i po jasnej stronie mocy. To nie tylko robot wyszukiwarki.
Robot wyszukiwarki
Google robot (Googlebot) jest znany wszystkim, ale poza nim, na każdej w miarę widocznej stronie, prędzej czy później, pojawi się też Bingbot Microsoftu, Slurpbot Yahoo!, DuckDuckBot skanujący dla wyszukiwarki DuckDuckGo, chiński Baiduspider Baidu czy rosyjski Yandexbot Yandexa.
Poza nimi pojawić mogą się też inne roboty wyszukiwarek o wiele mniej u nas znanych, jak np. Sogou Spider chińskiej wyszukiwarki Sogou, czy Exabot - robot internetowy francuskiej wyszukiwarki Exalead.
Roboty internetowe z mediów społecznościowych
Swoje roboty internetowe mają nie tylko wyszukiwarki, ale i najpopularniejsze portale społecznościowe. Przykładem może być bot Facebook external hit, pobierający elementy naszej strony takie jak title czy grafika do generowania widgetów linków wyświetlanych w serwisie.
Robot internetowy wykrywający plagiat
Najlepszym przykładem takiego robota internetowego jest crawler DMCA - organizacji zajmującej się egzekwowaniem zasad wynikających z ustawy o identycznym akronimie (DMCA) Digital Millenium Copyright Act. Działa on tam, gdzie obowiązują te prawa, czyli w USA, na terytoriach zależnych i w Kanadzie.
Innego rodzaju popularnym “robocim antyplagiatem” jest także System Content ID działający na YouTube. To właśnie robotowi internetowemu zawdzięczamy wychwytywanie fragmentów piosenek pojawiających się w filmach na YT, usuwanie materiałów objętych prawami autorskimi czy wszelkich spiraconych filmów. Jako twórcy, dzięki temu systemowi mamy też o wiele większe możliwości ochrony swoich dzieł.
Roboty internetowe agregujące wiadomości
Bardzo podobne do robotów wyszukiwarek, ale działające o wiele intensywniej i w obrębie o wiele mniejszego zakresu witryn. Odwiedzają systematycznie (w niektórych przypadkach nawet co kilka minut!) portale publikujące wiadomości i wszelkie aktualne informacje. Najbardziej znany z nich to Google-News bot, szukający stron do wyświetlenia w Google News. Innym przykładem może być także np. Alexaspider zbierający newsy dla Alexy - asystenta głosowego Amazonu.
Robot sieci reklamowej
Robot internetowy należący do sieci reklamowej działa podobnie do robota indeksującego wyszukiwarki. Przykładowo, zdecydowanie najszerzej działający AdSense Bot (Mediapartners-Google) odwiedza serwisy partnerskie systemu AdSense i indeksuje je bardzo podobnie do wyszukiwarki.
Taki robot internetowy przede wszystkim analizuje i określa zawartość strony internetowej. Po to, by sieć reklamowa mogła dopasować oferowaną przez Ciebie przestrzeń na reklamy do grup docelowych i ją wycenić. Co tydzień ponawia też wizytę, żeby zaktualizować posiadane informacje.
Price scraper (!)
Ten rodzaj robota jest idealnym przykładem tego, o czym mówiliśmy na początku tych zestawień - nie da się jednoznacznie powiedzieć, że robot internetowy jest zły czy dobry.
Price scrapera wymieniliśmy już w złych robotach internetowych, ale wymieniamy go ponownie i w tych dobrych - bo bardzo podobne systemy crawlerów wykorzystywane są przez np. porównywarki cenowe. Dzięki nim nasze produkty mogą być w nich widoczne - a to przecież zawsze dodatkowa szansa na ruch i sprzedaż.
Oczywiście kwestią sporną pozostaje, czy robot porównywarki powinien być nazywany price scraperem, czy raczej pełnoprawnym robotem indeksującym - ale nie będziemy aż tak brnąć w teorię. Jakby nie patrzeć, taki robot przede wszystkim śledzi ceny produktów, spełnia więc definicję scrapera.
Robot narzędzia SEO
Niemałą aktywność robotów internetowych generuje też SEO. Tak w kwestii jednorazowego indeksowania z crawlerami typu Screaming Frog, jak i w kwestii ciągłego monitorowania sieci przez rozbudowane narzędzia. Jeśli poszperasz w logach swojej strony, możesz znaleźć w nich ślady wizyt robotów Ahrefs, Semrush, Semstorm, Moz, Senuto i wielu innych.
Jeśli kiedykolwiek zastanawiałeś/aś się nad tym, skąd narzędzia SEO czerpią te wszystkie dane o stronach - masz odpowiedź. W kwestii badania pozycji jest to zwykle kwestia robotów, wysyłanych automatycznie na cyfrowe zwiady setki tysięcy razy dziennie, a kwestii audytów czy analiz konkurencji - także robotów, tylko odsyłanych na “front” na życzenie, przez użytkowników narzędzi.
Dygresja: boty, keywordy i wolumeny
Skoro zahaczyliśmy już o roboty internetowe związane z narzędziami SEO, to warto zaznaczyć istotną kwestię, z której wiele osób działających w zakresie pozycjonowania swojej strony nie zdaje sobie sprawy. Roboty internetowe narzędzi SEO zawyżają szacowany potencjał słów kluczowych. Wszystko dlatego, że monitorując pozycję serwisów na dane frazy czy też ogólnie, monitorując SERP-y, używają Google.
Gdy trzech specjalistów ustawi w narzędziach sprawdzanie frazy “pierogi ruskie” raz na tydzień, to w miesiącu dojdzie nam 12 wyszukiwań. Gdy zrobi to dziesięciu, to zapytań będzie już 40, a gdy będą oni sprawdzać pozycje codziennie, liczba zakręci się około 300.
W obliczu setek rozwiązań monitorujących sieć i tysięcy pozycjonujących się serwisów liczby te szybko rosną. To dlatego dane o potencjale wyszukiwań pochodzące z narzędzi zawsze dobrze jest traktować z dystansem. Szczególnie przy popularnych “opłacalnych” frazach o intencjach zakupu.
Jak zablokować roboty internetowe?
Sposobów na to jak zablokować roboty internetowe jest kilka, ale właściwie wszystkie z nich polegają na edycji pliku .htaccess. Jest to domyślny plik konfiguracji na serwerach Apache, zwykle znajdujący się w głównym katalogu domeny. Jeśli nie masz do niego dostępu, a będziesz chcieć zablokować jakiegoś złośliwego robota, konieczne będzie skontaktowanie się z dostawcą hostingu.
Robot Exclusion Protocol - nie blokada, a prośba
Pierwszy krok w blokowaniu robotów to dodawanie dyrektyw do pliku robots.txt lub zastosowanie odpowiednich meta tagów. Więcej na ten temat znajdziesz w poświęconych tym tematom częściom SEO Samodzielnych. Pamiętaj jednak, że w przypadku robotów złośliwych elementy te nic nie dadzą - bo będą one ignorowane.
Zapamiętaj
Nie tylko “złe” roboty internetowe nie przestrzegają robots.txt i meta tagów, ignorują je też niektóre boty o intencjach neutralnych jak np. Google bot FeedFetcher.
Blokowanie IP w .htaccess
Najprostszym, choć niezbyt skutecznym w przypadku rozproszonych botów sposobem na zablokowanie niechcianego ruchu jest dodanie do .htaccess dyrektywy “deny from” i zablokowanie dokładnego adresu. Taka metoda może być przydatna również w przypadku ruchu niechcianego robota internetowego maskującego się fałszywą aplikacją kliencką.
Przykładowo, gdy namierzymy robota, który obciąża serwer, ale podaje się przy tym za Google Chrome, Googlebota czy Mozille, wtedy nie możemy zablokować wartości User-Agent - bo w ten sposób odetniemy sobie indeksowanie czy ruch użytkowników z danej przeglądarki. Blokujemy więc po adresach, z których łączą się boty.
Deny from "Tutaj adres IPv4"
Deny from "Tutaj adres IPv6"
Blokowanie przez RewriteCond i RewriteRule
Reguły RewriteCond i RewriteRule (moduł mod_rewrite) możesz kojarzyć już z ręcznego ustawiania przekierowań, o którym pisaliśmy w lekcji o przekierowaniach. Dla przypomnienia: służą one przepisywaniu adresów URL. RewriteCond jest opcjonalnym warunkiem, a RewriteRule regułą przepisania adresu (wykonywaną gdy spełniony zostanie warunek spełniony w RewriteCond - jeśli występuje).
Przykład konfiguracji blokującej robota “złodziejobot”:
RewriteEngineOn
RewriteCond %{HTTP_USER_AGENT} .*złodziejobot* [NC,OR]
RewriteRule ^.* - [F,L]
Zasada działania jest tutaj prosta. Jeśli wartość aplikacji klienckiej, czyli User-Agent klienta wysyłającego żądanie do serwera będzie równa wartości “złodziejobot”, to przy takim zestawie reguł serwer automatycznie odrzuci zapytanie i zwróci kod 403 (Forbidden).
Gdybyśmy chcieli dodać kolejnego bota do naszej blokady, to przed RewriteRule wystarczy dopisać kolejny RewriteCond, w ten sposób:
RewriteCond %{HTTP_USER_AGENT} .*inny_złośliwy_robot* [NC]
Żeby wszystko było jasne:
- [NC] - ignoruj wielkość liter,
- [OR] - wykonaj kolejną regułę RewriteCond,
- [F] - odmów dostępu, czyli zwróć kod 403,
- [L] - ostatnia reguła RewriteRule.
* Przy blokowaniu robotów w ten sposób, flagi “[NC,OR]” powinny znaleźć się na końcu każdej reguły RewriteCond poza ostatnią (na końcu której zamieszczamy wyłącznie “[NC]”).
Blokowanie przez moduł SetEnvIf
Moduł mod_setenvif pozwala ustawiać wewnętrzne zmienne środowiska serwera w zależności od tego, czy żądanie spełnia określone przez nas wyrażenia regularne. Z jego wykorzystaniem możemy stworzyć mechanizm blokowania niechcianych botów, w którym serwer będzie sprawdzał zawartość User-Agent w zapytaniach. Gdy te będą pasować do podanych w dyrektywie, serwer automatycznie zwróci 403.
SetEnvIfNoCase ^User-Agent$ .*User-Agent_złego_bota HTTP_SAFE_BADBOT
SetEnvIfNoCase ^User-Agent$
.*(inny_User-Agent|a_tutaj_kolejny|i_jeszcze_jeden|i_tak_bez_końca)
HTTP_SAFE_BADBOT
Order allow,deny
Allow from all
Deny from env=HTTP_SAFE_BADBOT
Rozwiązanie to ma przewagę nad powyższymi pod kątem szybkości - duża liczba indywidualnych reguł może spowalniać przetwarzanie zapytań, a tutaj możemy “upakować” wszystkie blokowane boty w jednej linijce. Niestety, w większości hostingów moduł ten jest domyślnie niedostępny, wymaga wykupienia serwera dedykowanego.
Jak zablokować roboty bez wartości User-Agent?
Wbrew pozorom jest to możliwe nie tylko po adresie IP. Wszystkie takie “cwane” roboty internetowe ukrywające swój nagłówek User-Agent można łatwo odciąć za pomocą mod_rewrite. I właściwie to nie ma co się martwić o to, że zablokujemy w ten sposób też coś istotnego - cokolwiek ukrywa swoją tożsamość, warte wpuszczania na serwis na pewno nie jest.
Jak to zrobić? Uzupełniamy .htaccess o następujące reguły:
RewriteEngineOn
RewriteCond %{HTTP_REFERER} ^-?$ [NC]
RewriteCond %{HTTP_USER_AGENT} ^-?$ [NC]
RewriteRule .* - [F,L]
Reguła ta sprawia, że serwer będzie zwracał 403 wszystkiemu, co będzie mieć puste wartości “Referer” oraz “User-Agent” i będzie chciało uzyskać dostęp do jakichkolwiek zasobów strony. Pusty Referer jest tu zabezpieczeniem przed jedynym wyjątkiem, w którym nie powinniśmy odcinać od siebie zapytania z pustym nagłówkiem User-Agent.
Wyjątek ten to użytkownicy używający mocno przestarzałych programów antywirusowych ukrywających identyfikator aplikacji.
Kiedy blokować roboty internetowe?
Roboty wyszukiwarki trzeba blokować wtedy, gdy nie chcemy, by nasza strona lub jej fragmenty były widoczne w Google - wówczas do gry wchodzą meta tagi i plik robots. Kiedy jednak blokować inne roboty internetowe? Gdy zauważymy coś niepokojącego czy może prewencyjnie? A może po analizie logów?
Z naszej strony nie zalecamy masowego blokowania robotów internetowych według list dostępnych w sieci “dla zasady”. Zwykle nic to nie zmienia, poza niepotrzebnym zwiększeniem obciążenia serwera. Polecamy jednak przyglądać się co jakiś czas temu, co dzieje się na stronie, w tym odwiedzającym nas robotom. Nie trzeba do tego nawet analizy logów (choć ta będzie przydatna), wystarczy Screaming Frog SEO Spider lub inny crawler.
Przyjmujemy prostą zasadę: jeśli ruch jakiegoś robota nas niepokoi, blokujemy go. Jeśli nie, nie poświęcamy temu uwagi. Z doświadczenia wiemy jednak, że zazwyczaj na stronach jest o wiele więcej istotniejszych problemów niż ruch nawet tych złośliwych robotów. Blokowanie ich ma sens wtedy, gdy jest potrzebne do rozwiązania problemów z indeksowaniem czy ogólnie działaniem strony. Na pewno nie jest to coś, na czym warto skupiać się w standardowej optymalizacji - jeśli nie prowadzą do tego inne problemy, z którymi się zmagamy.
Jak sprawdzać roboty internetowe?
Gdy zidentyfikujemy już jakiegoś potencjalnie podejrzanego robota, możemy go zablokować lub wcześniej postarać się ustalić jego tożsamość. To właśnie sposoby na to drugie wymieniamy poniżej.
Sprawdzanie po wartości User-Agent
Widząc, że naszą stronę wizytuje Bingbot czy Google bot raczej nie mamy wątpliwości co do pochodzenia robota, deweloperzy są jednak często o wiele kreatywniejsi i nadają swoim botom nazwy mocno niewskazujące na ich pochodzenie. Wówczas wskazówką stać może się pełny opis robota widoczny w żądaniu HTTP lub logach serwera.
Gdy opis nie istnieje, nadal możemy jednak poszukać wg. wartości User-Agent, np., w świetnym repozytorium aplikacji klienckich robotów internetowych tworzonym i aktualizowanym ciągle od ponad 5 lat przez społeczność na GitHubie: https://github.com/monperrus/crawler-user-agents
Śledząc, co dany robot robi na stronie w analizie logów
Dobrą wskazówką co do odnajdywania szczególnie szkodliwych botów może być prześledzenie ich aktywności. Gdy ta ogranicza się np. wyłącznie do systematycznego wchodzenia na strony produktów, prób logowania, ciągłego pobierania jednego pliku, wysyłania równolegle mnóstwa żądań itd. to “wiedz, że coś się dzieje”.
Czasem wystarczy przeklikać się przez logi zapytań danego bota, by od razu zauważyć, że coś jest nie tak. Zdecydowanie częściej roboty jednak starają się pozostać incognito, szczególnie te złośliwe, które maskują się na wszelkie możliwe sposoby.
Weryfikacja po IP
Ten element dotyczy popularnych crawlerów, takich jak Google robot, boty wyszukiwarek, sieci reklamowych, narzędzi czy inne. Jeśli User-Agent wskazuje na to, że dany robot internetowy należy np. do Bing, to najprawdopodobniej gdzieś w dokumentacji narzędzi znajdziemy listę oficjalnych adresów, z których Microsoft prowadzi crawlowanie.
Google ma nawet narzędzia pozwalające to automatycznie weryfikować. Większość operatorów robotów skanujących sieć na dużą skalę udostępnia ich adresację. W ten sposób można wychwycić złe roboty internetowe podszywające się pod inne, nieszkodliwe boty.
Nie tylko Google robot
Jak doskonale widać, roboty internetowe to temat rzeka. Warto się w nim orientować, ale na potrzeby podstaw SEO, poza kwestiami dotyczącymi indeksowania, nie jest to zdecydowanie kwestia priorytetowa. W każdym razie mamy nadzieję, że rzuciliśmy na to wszystko nieco światła i wiecie już, co i jak robić.
Jeśli coś pozostało niejasne, umknął nam jakiś błąd, czegoś tu zabrakło lub zwyczajnie, po ludzku, masz do nas pytanie, zapraszamy do grupy SEO Samodzielni na Facebooku :)
Z tego artykułu dowiedziałeś się:
- Czym są roboty internetowe
- Jak działają roboty internetowe
- Rodzaje robotów internetowych
- Jak analizować ruch i blokować roboty internetowe
Autorzy artykułu
Zespół Top Online
Adam Przybyłowicz
Product Lead i specjalista od researchu i rozwoju w Top Online. Zdobywa dla nas wiedzę, szuka nowych rozwiązań i pracuje nad tym, żebyśmy nie zostali w tyle. Prowadzi zespół tworzący m.in. YOSA.AI.


