
Sprawdź, na czym polega optymalizacja crawl budget i jak ją przeprowadzić! Budżet indeksowania to pojęcie używane w SEO do określania ilości mocy przerobowej robotów Google przypadającej na indeksowanie Twojej strony. To aspekt ważny dla pozycjonowania i prawidłowego funkcjonowania wszystkich dużych witryn internetowych.
Z tej części SEO Samodzielnych dowiesz się, na czym polega Google crawl. Poznasz jego składowe, tj. crawl rate limit oraz crawl demand. Zrozumiesz też, co na nie wpływa i kiedy trzeba przyjrzeć się temu bliżej. Poza tym, przede wszystkim praktyka: przydatne narzędzia, sposoby weryfikacji oraz optymalizacja crawl budget krok po kroku.
Spis treści:
- Co to jest crawl budget?
- Jak działa Google crawl? Skąd ograniczenia?
- Z czego składa się istotny dla SEO crawl?
- Czy crawl budget jest dla Ciebie istotny?
- Jak sprawdzić, czy crawl budget jest poprawny?
- Co może wpływać na Google crawl?
- Analizujemy crawl budget - jakie narzędzia SEO?
- Zbieranie i analiza danych na temat crawl budget
- Optymalizacja crawl budget - jak to zrobić krok po kroku?
- Kolejność działań
- Podsumowanie
Powiązane z:
Co to jest crawl budget?
Crawl budget nie doczekał się jednej, sztywnej definicji. To nieoficjalny termin używany przez SEO-wców i innych specjalistów, służący określeniu zasobów, jakie wyszukiwarka przeznacza na indeksowanie danej strony. Nikt nie próbuje jednak doliczać się tutaj mocy obliczeniowej.
Zasoby te (crawl budget) odzwierciedlają dwa składniki:
- częstotliwość, z jaką boty mogą indeksować stronę,
- ilość adresów, które mogą być skanowane równolegle / przy jednej wizycie,
Można więc powiedzieć, nieco na około, że crawl budget to ilość uwagi poświęcanej danemu serwisowi przez roboty indeksujące. Pod kątem pozycjonowania interesuje nas przede wszystkim jej prawidłowe wykorzystanie. Równie ważne jest też jednak dbanie o to, by nasz SEO crawl nie malał, do czego może dojść w efekcie zaniedbań lub braku optymalizacji.
Jak działa Google crawl? Skąd ograniczenia?
Google crawl można podzielić na dwa osobne procesy: discovery crawling oraz refresh crawling. Pierwszy to to, o czym pisaliśmy w wymienonej już części, Indeksacja strony w Google. Roboty wyszukiwarki szukają nowych stron, skanują je i dodają do indeksu. Refresh crawling dotyczy z kolei adresów znanych już wyszukiwarce, mający na celu odświeżenie ich statusu (i zawartości) w indeksie.
Oba te “typy” Google crawl zachodzą równolegle, ale na ich limity mogą wpływać różne aspekty.
Discovery crawling, mający dodać nową stronę do indeksu zachodzi na dwa sposoby. Niezależnie, poprzez skanowanie zawartości serwerów w poszukiwaniu nowych witryn lub poprzez trafienie na link, co ma miejsce gdy nowa witryna zostanie już zlokalizowana lub w trakcie refresh crawl.
Proces ten jest ograniczony poprzez przydzielone mu odgórnie zasoby obliczeniowe. Ogromne, aczkolwiek skończone, w przeciwieństwie do non stop rozszerzających się zasobów internetu.
Refresh crawling również jest ograniczony w ten sposób, tutaj jednak sprawa jest bardziej złożona i co ważne, możemy mieć na nią wpływ. Google nie przydziela bowiem wszystkim znanym sobie stronom “po równo”, a dostosowuje częstotliwość i ilość skanowanych adresów do przeciętnej częstotliwości aktualizacji ich zawartości.
Na stronie, która zmienia się co godzinę, np. publikującej newsy, roboty będą nawet co godzinę. Na stronie, która zmienia się raz w tygodniu czy rzadziej, z czasem crawl budget znacznie zmaleje. Google stara się zarządzać swoimi zasobami obliczeniowymi możliwie jak najefektywniej. Stara się też przy tym nie obciążać skanowanych serwerów.
Jeszcze szybkie porównanie: Crawl budget jest jak opona, z której powoli ucieka powietrze. Chcąc jechać dalej, musimy je co jakiś czas uzupełniać (publikować i aktualizować content czy pozyskiwać linki). Bez tego częstotliwość wizyt Googlebota spadnie, ciężej będzie więc kontynuować SEO serwisu i utrzymywać pozycję. Odnotowanie wszelkich działań w serwisie zajmie znacznie dłużej.
Z czego składa się istotny dla SEO crawl?
Termin crawl budget nie jest oficjalny. Poza wzmianką o tym, że są nim “zwykle nazywane czas i zasoby, jakie Google poświęca na zeskanowanie określonej witryny” w dokumentacji Google nie znajdziemy żadnej oficjalnej definicji czy przedstawienia budżetu indeksacji. Znajdziemy za to przedstawienie dwóch pojęć składających się na zarządzanie zasobami crawlowania.
Limit wydajności crawlowania (ang. crawl rate limit)
Crawl rate limit, czyli limit wydajności crawlowania to maksymalna liczba jednoczesnych połączeń równoległych Googlebota z daną witryną. Obliczana przez Google w celu zminimalizowania obciążenia serwerów procesem indeksacji. Dzięki niej firma może pobierać całą istotną zawartość, nie wpływając przy tym nadmiernie na działanie stron. To swoisty próg bezpieczeństwa, który pozwala Google nie ingerować w wydajność naszych maszyn.
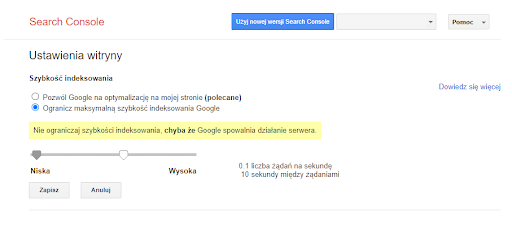
Co ciekawe, limit ten można zmienić ręcznie w Google Search Console, ale ta opcja nie jest dostępna dla wszystkich. Zwiększenie go nie wpłynie jednak na zwiększenie crawl budget. Funkcja ta służy jedynie ograniczeniu liczby żądań Googlebota w specyficznych przypadkach, w których spowalnia on serwer.
Zapotrzebowanie na indeksowanie (ang. crawl demand)
Drugie pojęcie wpływające na budżet indeksowania to tzw. zapotrzebowanie na indeksowanie. To aktywność wokół strony, o czym wspominaliśmy wyżej, w tym podejmowane działania SEO. Crawl demand to wartość odpowiadająca temu, ile uwagi robotów potrzebuje strona. Im więcej się dzieje (pojawiają się linki, treści, zmiany), tym większy crawl demand. Co ważne, w tej kwestii liczy się też to, czy adres URL jest popularny.
Czy crawl budget jest dla Ciebie istotny?
Wiesz już i (mamy przynajmniej taką nadzieję) rozumiesz, czym jest crawl budget oraz jak działa Google crawl. Zanim przejdziemy jednak do optymalizacji, musimy wspomnieć o tym, że budżetem indeksacji nie trzeba zajmować się absolutnie zawsze.
W oficjalnym przewodniku po zarządzaniu budżetem indeksowania Google wskazuje, że zarządzanie to jest przydatne dla:
- dużych witryn z treścią zmieniającą się umiarkowanie często (liczących ponad milion unikalnych stron i aktualizowanych np. raz w tygodniu),
- średnich lub większych witryn, których treść zmienia się bardzo szybko (liczących około 10 tys. unikalnych stron i aktualizowanych codziennie),
Oczywiście, nie są to dane sztywne, co jest też zaznaczone w dokumentacji. My jednak radzilibyśmy zainteresować się optymalizacją crawl budget już od progu kilkuset podstron. Szczególnie jeśli na stronie ciągle publikowane jest coś nowego lub dokonywane są jakieś zmiany.
Brak precyzyjnego zarządzania budżetem indeksowania raczej nie odbije się negatywnie na SEO przy takich ilościach adresów, ale poświęcenie tej kwestii nieco uwagi może pomóc w usprawnieniu indeksacji. Zawsze warto też budować dobre nawyki. Szczególnie jeśli planujemy systematyczny rozwój serwisu (np. poszerzamy asortyment sklepu internetowego).
Niektóre aspekty optymalizacji Google crawl mogą wpłynąć korzystnie nie tylko na skuteczność indeksowania, ale i na samo działanie serwisu, a o to zawsze warto zadbać.
Zapamiętaj
Optymalizację crawl budget trzeba przeprowadzać na stronach dużych i często aktualizowanych. W przypadku stron mniejszych nie jest konieczna. Warto jednak zainteresować się nią już przy kilkuset podstronach w serwisie.
Jak sprawdzić, czy crawl budget jest poprawny?
Przejdźmy do rzeczy. Jak stwierdzić, czy crawl budget jest poprawny bądź nie? Przede wszystkim, trzeba wykluczyć podstawowe problemy z indeksowaniem, takie jak brak treści, analizy i właściwego wykorzystania słów kluczowych czy słabe linki (lub ich brak).
Dopiero później, gdy mamy pewność, że brak indeksowania się nowych podstron (lub zmian na stronie) nie wynika z innych błędów, możemy analizować pod kątem SEO crawl budget. Do tego, będziemy musieli przede wszystkim odpowiedzieć sobie na kilka pytań. Dotyczących tego jak długo zajmuje przeciętnie indeksowanie nowych podstron od momentu publikacji oraz jak długo zajmuje odświeżenie zaktualizowanej treści w indeksie.
Kolejno będziemy musieli przyjrzeć się także temu, jak roboty poruszają się po naszych stronach.
Co może wpływać na Google crawl?
Wśród czynników mogących wpływać na Google crawl, poza częstotliwością zmian i popularnością strony, znajduje się całkiem sporo elementów technicznych. Poniżej przedstawiamy ich syntetyczną listę.
Zapamiętaj
Jeśli uważasz, że możesz mieć problem z crawl budgetem, przyjrzyj się poniższym czynnikom w swoim serwisie. Bardzo możliwe, że zlokalizujesz element hamujący roboty jeszcze przed przystąpieniem do właściwej analizy (o której piszemy niżej).
Czynniki wpływające na crawl budget (crawl demand i crawl rate limit):
- Linkowanie wewnętrzne - słaba struktura linków wewnętrznych lub jej całkowity brak może wpływać na skuteczność indeksacji (w tym crawl budget); roboty podążają za linkami, brak linków, za którymi można iść to koniec crawlu,
- Duplicate content - duplikacja treści, szczególnie ta masowa wewnętrzna, obniża skuteczność indeksowania; robot skanuje wszystkie podstrony, ale ze względu na powieloną zawartość nie wpisuje ich do indeksu,
- Kanibalizacja treści - błąd w optymalizacji / doborze słów kluczowych sprawia, że robot nie jest w stanie rozstrzygnąć, które treści w serwisie najlepiej pasują do konkretnego zapytania; ogólna jakość spada, spaść może też skuteczność indeksacji,
- Brak treści - niemal całkowity brak treści lub tzw. thin content na podstronie; roboty mogą uznać bardzo niski text to code ratio za nieprawidłowe wczytanie strony, czyli pozorny błąd 404, co kończy się ograniczeniem indeksowania (często nawet istotnych podstron, dlatego rozbudowa treści jest tak ważna),
- Robots.txt - sporadycznie zdarza się, że indeksacja jest blokowana lub ograniczana przez dyrektywę w pliku robots.txt, czego nie jesteśmy świadomi; warto sprawdzić,
- Parametry adresów URL - mogą to być np. identyfikatory sesji lub niezablokowane parametry wewnętrznej wyszukiwarki; przez brak ograniczeń w tej kwestii Googlebot może dotrzeć do nieskończonej liczby wariantów jednego adresu, a stąd już prosta droga do indeksowania setek kompletnie zbędnych URL-i zamiast istotnych podstron,
- Przekierowania - a właściwie ich nadmiar, błędne 301-ki i pętle przekierowań, to wszystko może szkodzić indeksacji; roboty mniej skutecznie indeksują strony, do których prowadzi wiele przekierowań, każde przekierowanie adresu obniża też crawl rate limit (przez wydłużenie czasu odpowiedzi serwera),
- Błędy 404 - im więcej adresów zwraca błąd 404 (lub 410), tym z reguły gorszy przebieg indeksowania,
- Wydajność serwera - hosting w SEO ma znaczenie, im dłuższy czas odpowiedzi naszego serwera na żądania Googlebota, tym mniejszy crawl rate limit w przyszłości; roboty wyszukiwarki mają nie obciążać nadmiernie serwerów, przy bardzo słabej wydajności mogą więc ograniczyć swoją aktywność na tyle mocno, że odbije się to na skuteczności indeksowania,
Analizujemy crawl budget - jakie narzędzia SEO?
Crawl budget nie jest czymś, co da się jednoznacznie zmierzyć. Nie ma tutaj żadnego wskaźnika (nawet zewnętrznego) czy wartości, która byłaby porównywalna. To dlatego analiza opiera się raczej na stwierdzeniu występowania problemu (bądź nie), a następnie na wskazaniu jego źródeł i ewentualnych rozwiązań. Po ich wdrożeniu pozostaje jeszcze oczywiście weryfikacja.
Tylko skoro nie ma czego mierzyć, to tak właściwie czemu będziemy się przyglądać? Cóż, podejść jest kilka, ale najłatwiej będzie przedstawić je razem z rozwiązaniami. W analizie tego, jak przebiega Google crawl, potrzebne będą z pewnością Google Search Console i zewnętrzne crawlery (nasza rekomendacja: Screaming Frog SEO Spider).
Przydać mogą się jednak także inne podstawowe narzędzia SEO. Zastosowanie na pewno znajdzie coś do monitorowania pozycji adresów i analizy ich linków zewnętrznych. Do sprawdzenia, jak roboty poruszają się po stronie, będziemy potrzebować też narzędzia do analizy logów.
Reasumując, do analizy crawl budget potrzebne będą:
- Google Search Console,
- Dowolny SEO crawl tool (np. Screaming Frog),
- Dowolne narzędzia do analizy pozycji i linków (np. SEMSTORM + Ahrefs),
- Dowolne oprogramowanie do analizy logów (np. Ryte, SemRush).
Zbieranie i analiza danych na temat crawl budget
Poniżej prezentujemy krótką instrukcję tego, jak zbierać i analizować dane dotyczące crawl budget. Zebraliśmy tutaj wszystko, co naszym zdaniem najważniejsze. Jeżeli wcześniej przedstawione elementy nie zaburzają indeksacji, te metody powinny pomóc Ci znaleźć przyczynę problemu. Pamiętaj jednak, że skuteczność audytu zależy przede wszystkim od Twojego zaangażowania i skrupulatności.
1. SEO Crawl z narzędziem zewnętrznym
Pełny SEO crawl serwisu mający na celu za symulowanie tego, jak Googlebot porusza się po serwisie to podstawa analizy budżetu indeksacji. To najprostszy sposób na sprawdzenie, czy wszystko na naszej stronie działa tak jak powinno.
Czego szukamy w danych wygenerowanych przez taki SEO crawl? Przede wszystkim wszelkich błędów przekierowań, 404-ek oraz duplikacji (w tym tzw. near duplicate content). Naszą uwagę powinny zwrócić też wszelkie błędy pobierania zawartości (szczególnie gdy serwis nie ogromny, a nie zostaje zeskanowany w całości).
Zapamiętaj
Wskazówka: Jeśli używasz Screaming Frog SEO Spider, połącz go z danymi z Google Search Console oraz Google Analytics. Pomoże Ci to w analizie.
2. Eksport danych z Search Console
W kontekście analizy Google crawl, w Search Console interesują dwa miejsca: raport Stan oraz raport Statystyki indeksowania (dostępny w “Ustawienia” > “Indeksowanie”). To właśnie dane z tych dwóch raportów będziemy eksportować, a następnie weryfikować.
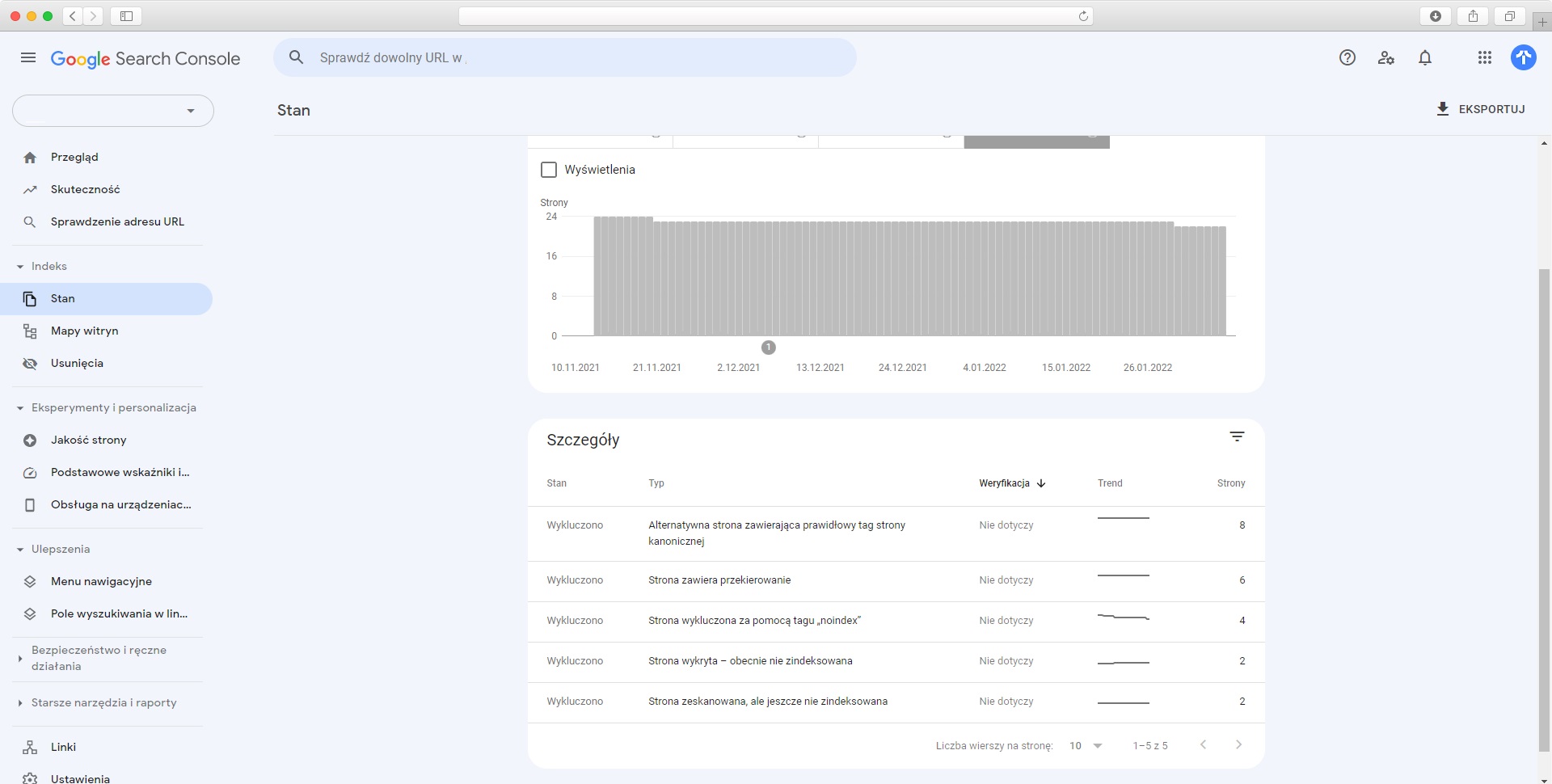
W raporcie Stan interesują nas przede wszystkim wykluczenia. To one mogą wskazać nie tylko skalę problemu z budżetem indeksacji, ale i potencjalne przyczyny jego powstania.
Tutaj, w szczegółach, znajdziemy informacje m.in. o duplikatach i powodach ich wykrycia, tagach noindex, pozornych błędach 404 i problemach z renderowaniem zawartości (status “Strona zeskanowana, ale jeszcze niezindeksowana”). Najpoważniejszy błąd adresu, na który trzeba zwrócić uwagę w pierwszej kolejności to tutaj “Strona wykryta, niezindeksowana”.
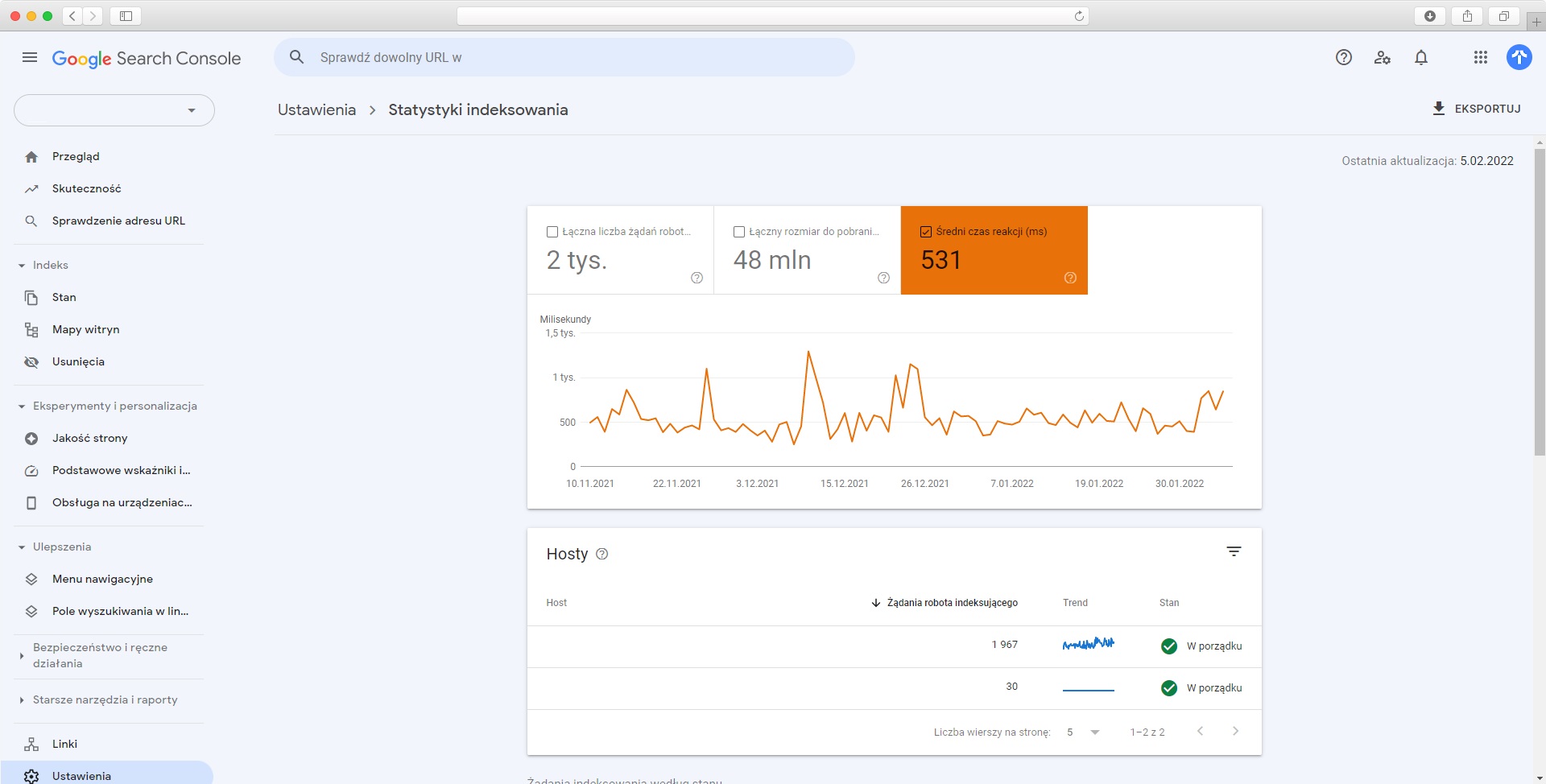
W Statystykach indeksowania interesuje nas głównie Średni czas reakcji. Zmiany tej wartości mogą świadczyć o niestabilnym działaniu serwera. Regularne skoki mogą z kolei wskazywać na zachodzenie jakiegoś zasobożernego procesu.
Poza tym warto posortować też żądania wg. przeznaczenia oraz typu odpowiedzi i poszukać w nich wszelkich nietypowych sytuacji. Ich przykładami mogą być choćby odświeżane przez Google puste adresy lub adresy z niechcianymi parametrami. Warto sprawdzić również, czy żaden adres nie zwraca do Google kodu 304: Not Modified.
3. Najlepsze podstrony jako punkt wyjścia optymalizacji
Jeśli zastanawiałeś/aś się, do czego w analizie crawl budget potrzebne będą narzędzia do analizy pozycji czy backlinków, śpieszymy z odpowiedzią. Posłużą one do wyznaczenia najbardziej wyróżniających się adresów URL w serwisie, tj. linków o największym ruchu, największej ilości wartościowych linków i największej organicznej widoczności.
Po co nam te adresy? Im większa popularność, tym większy crawl demand. Najlepiej działające podstrony analizowanej strony (wraz ze słowami kluczowymi, na które mamy najlepszą widoczność) pomogą nam zrozumieć rozkład budżetu indeksacji. Posłużą też później do jego optymalizacji (np. poprzez wdrożenie na nich dodatkowego linkowania wewnętrznego).
4. Logi serwerowe
Optymalny zakres czasowy logów serwerowych to ostatni miesiąc. Jeśli dysponujesz nimi, bardzo przydatne będą też logi historyczne, sprzed wystąpienia problemów z indeksowaniem, do porównania. Najistotniejszy aspekt w analizie logów to przeglądanie tylko danych dotyczących zweryfikowanych botów wyszukiwarki (może pomóc tutaj lista IP Googlebotów; niektóre narzędzia mają też wbudowane filtry).
Sprawdzamy tutaj przede wszystkim, czy roboty wchodzą na stronę. Jeśli tak, to sprawdzamy, jakie podstrony są przez nie odwiedzane i weryfikujemy czy (i jakie) odpowiedzi zwraca serwer. Najczęściej problem leży w wysokim poziomie odrzuceń generowanym zbyt długim czasem odpowiedzi. Szukamy też oczywiście wszelkich błędów i nietypowych wydarzeń.

Optymalizacja crawl budget - jak to zrobić krok po kroku?
Właściwa optymalizacja crawl budget polega na eliminowaniu wszelkich wąskich gardeł, czyli umożliwieniu robotom maksymalnie swobodnego przemieszczania się po stronie. To właśnie brak tej możliwości (zduszenie jej przez błędy lub brak optymalizacji) jest zazwyczaj przyczyną obniżenia budżetu indeksacji.
Poniżej przedstawiamy w punktach wszystkie najczęstsze zabiegi podejmowane przez nas pracy z optymalizacją crawl budget. Podejmowanie ich jest zazwyczaj poprzedzone wskazaniem na nie przez analizę (patrz: nagłówek wyżej). Nie każdy serwis mający problem z budżetem indeksacji będzie więc wymagał dokładnie tych operacji. Nic nie stoi jednak na przeszkodzie traktowania naszych opisów jako wskazówek.
No to do dzieła!
Podstawowa techniczna optymalizacja indeksacji
Jak to zwykło się mówić: “zaczynamy od początku”, czyli w tym przypadku, od rozwiązania podstawowych problemów optymalizacyjnych. Naprawiamy błędy 404, nieprawidłowe przekierowania, pozbywamy się duplicate content, thin content i kanibalizacji. W tych dwóch zdaniach mieści się często naprawdę mnóstwo pracy, jest to jednak kwestia absolutnie podstawowa.
Po naprawieniu wszystkich podstawowych problemów warto zweryfikować jeszcze raz cały serwis, poprzez zewnętrzny SEO crawl tool.
Przegląd i modyfikacja architektury informacji strony
Dobrze zaprojektowana architektura informacji na stronie jest dla jej crawlowania fundamentem, kręgosłupem, a nawet całym szkieletem. Bez tego indeksowanie nigdy nie będzie poprawne, bez linków robot nie będzie bowiem wiedział, że ma jeszcze co skanować.
Tutaj podejść jest wiele, ale najważniejsze to możliwość dotarcia do takiej samej ilości podstron z każdego URL-u w serwisie, czyli poprawne linkowanie sitewide. To, co najważniejsze dla skuteczności strony (np. główne kategorie sklepu internetowego) powinno być linkowane z widocznych pod każdym adresem menu czy stopki oraz strony głównej.
Weryfikacja i reorganizacja stron noindex
Budżet Google crawl jest “zużywany” na każdy zeskanowany przez roboty adres URL. To dlatego warto więc sprawdzić, ile podstron w serwisie jest oznaczonych jako meta tagiem noindex. Jak wiadomo, adresy te nie są indeksowane, ale roboty Google nadal mogą się po nich poruszać, marnując tym samym crawl budget.
Zawsze warto starać się maksymalnie zmniejszyć udział takich adresów w strukturze całego serwisu. W skrajnych przypadkach (np. źle użyte WordPressowe tagi) może okazać się, że podstrony noindex stanowią całkiem sporą część serwisu, przepalając nam tym samym budżet indeksowania.
Minimalizacja filtrowania listingów i sortowania
Ten punkt dotyczy szczególnie sklepów internetowych. Filtrowanie list produktów, szczególnie przy dużej ilości dowolnie łączonych parametrów, potrafi stworzyć mnóstwo zbędnych linków. W takiej konfiguracji Googlebot może dosłownie zginąć w listingach strony, przez co istotniejsze podstrony nie będą odświeżane czy indeksowane.
Optymalnym rozwiązaniem jest ograniczenie filtrowania do rozsądnego, ale praktycznego minimum oraz jednocześnie maksymalne wyłączenie go z adresów URL.
Warto sprawdzić też stosunek linków niekanonicznych do kanonicznych (zawierających rel=”canonical”). Google traktuje to oznaczenie wyłącznie jako wskazówkę. Może więc ignorować występowanie wersji kanonicznej i indeksować wielokrotnie tę samą kategorię (np. z różnymi parametrami sortowania w URL-ach).
Analiza wydajności serwera i strony
Sugerujemy się przede wszystkim tym, jak wypada PageSpeed naszej strony. Sprawdzamy też wskaźniki Core Web Vitals. W kwestii wydajności samego serwera, na problemy zwróci naszą uwagę z pewnością wspomniany już raport Stan indeksowania w Search Console, analiza logów lub nie do końca poprawny SEO crawl.
W przypadku problemów z serwerem trzeba będzie skontaktować się z pomocą techniczną hostingu lub zwyczajnie, pomyśleć o zmianie usługi. W przypadku samej strony konieczna będzie optymalizacja, o tym pisaliśmy jednak w poprzednich częściach SEO Samodzielnych.
Sitemap i robots.txt
No i jeszcze dwa prozaiczne, ale warto ponownego wspomnienia drobiazgi. Sprawdzamy, czy roboty nie są w żaden sposób blokowane ani ograniczane w pliku robots.txt. Co do sitemap.xml sprawdzamy natomiast, czy plik jest prawidłowy i aktualny. Weryfikujemy też, czy zawiera wszystko, co najważniejsze, tj. adresy kanoniczne.
Kolejność działań
Na koniec, dla każdego, komu przyjdzie podjąć się analizy i optymalizacji crawl budget, zamieszczamy dla przypomnienia naszą procedurę działania. Zasada jest podobna jak przy pełnej optymalizacji, najpierw zbieramy dane i je analizujemy, czyli przeprowadzamy audyt SEO. Dopiero potem, na tej podstawie, wyznaczamy i wprowadzamy w życie działania optymalizacyjne i wdrożenia.
Kolejność działań przy pracy z budżetem indeksowania:
- Zbieranie informacji z narzędzi.
- Analiza danych i wyznaczanie potencjalnych przyczyn powstania problemu.
- Analiza dostępnych rozwiązań (w celu wyznaczenia najbardziej opłacalnych).
- Sformułowanie planu działań i wdrożenie go w życie.
Może i dla wielu z Was wydaje się to oczywiste, ale wiemy, że wiele osób szuka w sieci w kwestii SEO gotowych rozwiązań. Zaznaczamy więc: nawet wdrożenie wszystkich wymienionych tutaj elementów optymalizacji może nie pomóc Twojej stronie, jeśli nie będziesz mieć pewności co do tego, gdzie leży przyczyna. Najpierw znajdujemy problem, a dopiero potem go rozwiązujemy. Nigdy na odwrót.
Podsumowanie
Budżet indeksacji jest pojęciem dość nieoczywistym i skomplikowanym. To temat ciekawy, ale dla większości mniejszych serwisów absolutnie kosmetyczny. Jeśli nie działasz z SEO naprawdę sporej strony, to najprawdopodobniej nie musisz się nim przejmować, ani zwracać na niego szczególnej uwagi. Jednak, nawet jeśli nie jest to w Twoim przypadku konieczne, polecamy się przyjrzeć, choćby po to, by jeszcze lepiej zrozumieć pozycjonowanie :)
Masz problem z indeksacją i nie wiesz jak go rozwiązać? Nasze wyjaśnienia okazały się niewystarczające? A może zabrakło Ci czegoś w naszej Akademii? Napisz do nas na Facebooku! Odnośnik do grupy SEO Samodzielni znajdziesz poniżej. Czekamy na Ciebie!
Z tego artykułu dowiedziałeś się:
- Czym jest crawl budget i z czego się składa
- Jak sprawdzić jego poprawność i kiedy to istotne
- Jakich narzędzi do tego użyć i jakie dane analizować
- Jak przeprowadzić optymalizację budżetu indeksacji
Autorzy artykułu
Zespół Top Online
Adam Przybyłowicz
Product Lead i specjalista od researchu i rozwoju w Top Online. Zdobywa dla nas wiedzę, szuka nowych rozwiązań i pracuje nad tym, żebyśmy nie zostali w tyle. Prowadzi zespół tworzący m.in. YOSA.AI.


