
Perplexity wysyła Google ofertę kupna ich flagowej przeglądarki internetowej. Wyszukiwarki AI mają problemy z renderowaniem contentu opartego na JavaScript. Google przypomina, że treści AI powinny być weryfikowane przez ludzi przed publikacją. Poza tym: spadek aktywności Google botów w wyniku błędu serwera i wdrożenie funkcji Preferred sources w Indiach i USA.
1. Perplexity składa Google ciekawą propozycję
Perplexity przeprowadza mocną ofensywę i chce odkupić od Google… przeglądarkę Chrome.
Propozycja jest dość nieoczekiwana, ale zbiega się w czasie z trwającym sporem sądowym o dominację Google i tworzenie przez nich monopolu na rynku wyszukiwania.
W zeszłym roku Departament Sprawiedliwości w USA sugerował, że Google powinno sprzedać Chrome, co mogłoby osłabić pozycję firmy i nieco ułatwić życie ich konkurentom.
Dla lepszego kontekstu: Chrome ma obecnie ok. 3,5 mld użytkowników na całym świecie i kontroluje ponad 60% globalnego rynku wyszukiwania.
Oferta Perplexity opiewa na skromne 34,5 miliarda dolarów :D – co ciekawe, jest to prawie dwa razy więcej, niż wynosi wycena całej firmy.
Jeden z większych start-up’ów AI podkreśla, że utrzymałby open-source’owy charakter Chrome. Pojawiły się tez obietnice zainwestowania blisko 3 mld dolarów na dalszy rozwój przeglądarki w ciągu najbliższych dwóch lat.
Podkreślono również, że Google pozostałoby domyślną wyszukiwarką, z opcją zmiany w zależności od preferencji użytkowników.
Wszystko super, ale Google jak dotąd nie wyraziło chęci pozbycia się swojej flagowej przeglądarki. Analitycy zgodnie podkreślają, że szanse na sprzedaż są minimalne i raczej nie traktują ich jako realnej próby przejęcia.
Jak więc to rozumieć? Ruch Perplexity może być gestem symbolicznym – sygnałem, że firma zamierza odważnie rywalizować z gigantami w obszarze wyszukiwania i AI.
Jak dla mnie to może być też próba odciągnięcia uwagi od ostatnich oskarżeń ze strony Cloudflare, które twierdzi, że boty Perplexity skanowały strony ich klientów mimo zablokowania im dostępu. O sprawie zrobiło się głośno na początku sierpnia – wiemy, że Perplexity dostało wówczas całkowitego bana od Cloudflare.
2. JavaScript na stronie = gorsza widoczność w wyszukiwarkach AI?
Dynamiczny rozwój wyszukiwania opartego na sztucznej inteligencji przynosi wiele korzyści – ale i poważne wyzwania techniczne.
Potwierdzają to najnowsze analizy Glenna Gabe’a z portalu GSQi, który udowodnił, że popularne platformy wyszukiwania AI – takie jak ChatGPT, Perplexity czy Claude – mają problem z odczytywaniem stron renderowanych wyłącznie po stronie klienta, a nie serwera (tzw. client-side rendering).
W praktyce oznacza to, że treści serwisów w pełni zależnych od JavaScriptu są dla systemów AI niewidoczne.

Gabe przytacza przykłady, w których narzędzia AI wyświetlały komunikaty w rodzaju „brak treści” czy „Access Denied”, mimo że strona działała poprawnie i była normalnie widoczna w Google.
Efektem były nie tylko puste wyniki, ale też brak fragmentów cytowanych w odpowiedziach czy nawet błędne favicony.
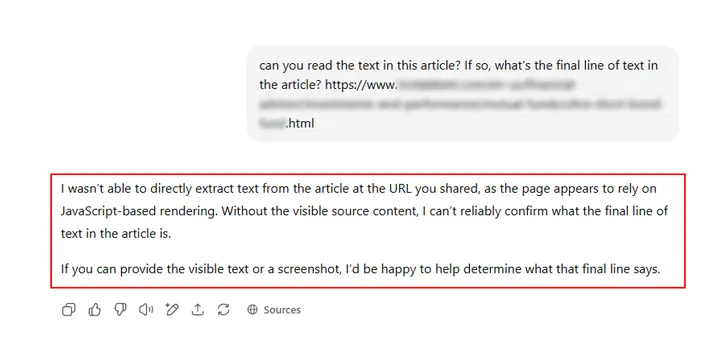
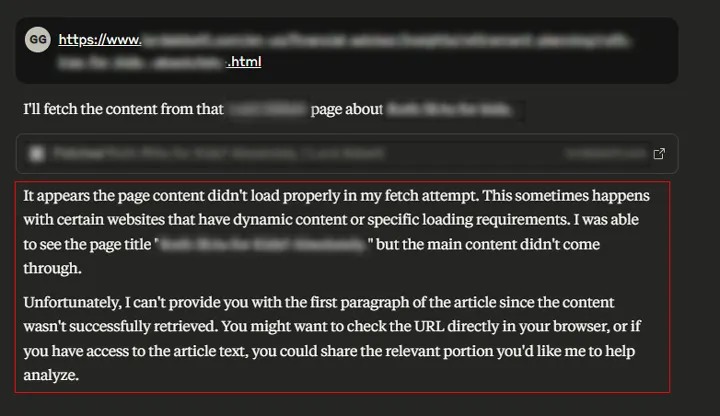
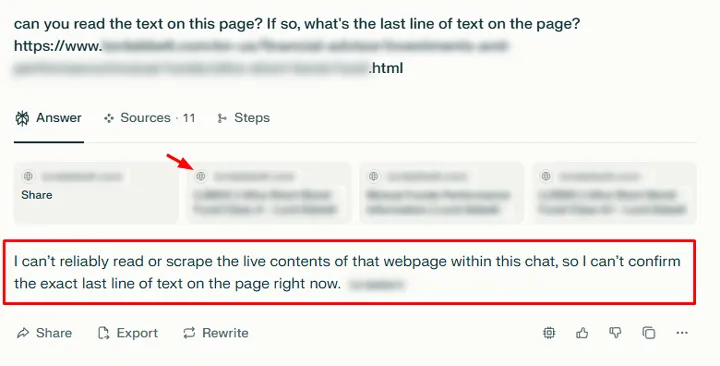
Tymczasem Bing (Copilot) oraz Google (AI Mode, AI Overviews) bez problemu radzą sobie z renderowaniem JavaScriptu, dzięki czemu w klasycznym wyszukiwaniu strony oparte na JS są indeksowane i rankują normalnie.
Problem dotyczy więc wyłącznie nowej fali wyszukiwarek AI, które coraz częściej stanowią dla użytkowników alternatywę dla tradycyjnych narzędzi do przeszukiwania sieci.
To może być sygnał ostrzegawczy dla właścicieli stron i specjalistów od pozycjonowania – warto upewnić się, że treści pojawiają się w narzędziach i odpowiedziach AI, bo jest to rosnące źródło ruchu i widoczności.
Rozwiązaniem może być tutaj przejście na model server-side rendering i stosowanie strategii tzw. progressive enhancement (progresywnego ulepszania), która zapewniłaby dostęp do kluczowego contentu w formie czystego HTML-a.
3. Google: Content AI powinien być weryfikowany przez ludzi
Google kolejny raz odniosło się do rosnącej fali treści tworzonych w narzędziach generatywnej sztucznej inteligencji.
Jak wyjaśnił Gary Illyes, materiały generowane przez AI mogą być publikowane i pojawiać się w wyszukiwarce, ale tylko wtedy, gdy będą sprawdzone i zatwierdzone przez ludzkiego specjalistę.
Najważniejszym kryterium pozostaje jakość treści – zgodność z faktami, oryginalność i unikanie duplikacji.
Google ostrzega, że automatycznie tworzone teksty bez kontroli redakcyjnej mogą prowadzić do powielania istniejących treści, a nawet do efektu „pętli treningowej” – czyli sytuacji, w której sztuczna inteligencja uczy się na treściach wygenerowanych przez inne modele AI.
Pisałem o tym w kontekście odpowiedzi AI pojawiających się w sekcji People Also Ask w Google.
Jednocześnie firma przypomniała, że sama korzysta z własnych rozwiązań opartych na modelach Gemini w usługach takich jak AI Overviews czy AI Mode. Tam treści AI są ściśle powiązane z danymi z indeksu wyszukiwarki (tzw. grounding), co pozwala minimalizować ryzyko błędów i dezinformacji.
W praktyce rekomendacja Google sprowadza się do prostego wniosku: sztuczna inteligencja może przyspieszyć tworzenie tekstów, ale to człowiek powinien decydować o ostatecznym kształcie i wiarygodności publikacji.
Bez tego materiały generowane przez AI mogą zostać uznane za niskiej jakości i prawdopodobnie nie zdobędą widoczności w Google.
4. Błędy serwera mogą wpłynąć na skuteczność indeksowania Google botów
Trafiłem ostatnio na Reddicie na ciekawy wątek utworzony przez jednego z użytkowników, który zauważył nagłe zmniejszenie aktywności Googlebota – w przypadku jego strony było to nawet -90% w ciągu doby.
Podejrzenie padło na błędnie wdrożone nagłówki hreflang, które zwracały statusy 404 i mogły wywołać takie spadki – czasowo obie te sytuacje idealnie się pokrywały.
Do dyskusji włączył się John Mueller z Google, który rozwiał wątpliwości: samo pojawienie się błędów 404 nie powinno powodować tak gwałtownego spadku crawl rate, ale problemy z dostępnością serwera – już tak.
Dużo bardziej prawdopodobne jest to, że serwer w tym czasie zwracał inne błędy – 500, 503, 429 – lub dochodziło do timeoutów. W efekcie Googlebot automatycznie ograniczył liczbę zapytań, żeby nie przeciążać infrastruktury.
Podobne problemy mogą powodować także systemy bezpieczeństwa – np. CDN, WAF czy reguły rate limiting, które czasowo blokują ruch z botów Google.
Mueller podkreślił, że jeśli przyczyna zostanie usunięta, szybkość indeksowania z czasem powinna wrócić do normy.
Proces nie jest jednak natychmiastowy – odbudowa aktywności bota może potrwać od kilku dni do kilku tygodni, w zależności od tego, jak stabilny będzie serwer po naprawie.
5. Funkcja Preferred sources oficjalnie dostępna w USA i Indiach
Google oficjalnie uruchomiło nową opcję personalizacji wiadomości w wyszukiwarce – Preferred Sources, która była testowana w ramach Search Labs od czerwca tego roku.
Funkcja pozwala użytkownikom wskazać ulubione i zaufane źródła informacji, które będą częściej pojawiać się w sekcji Top stories.
Nowość działa już w USA i Indiach dla wyszukiwań w języku angielskim. Aby dodać wydawcę do preferowanych, wystarczy kliknąć ikonę gwiazdki widoczną przy nagłówkach wiadomości.
Google umożliwia też udostępnianie specjalnych linków, które pozwolą odbiorcom jednym kliknięciem dodać strony wydawców do ulubionych.
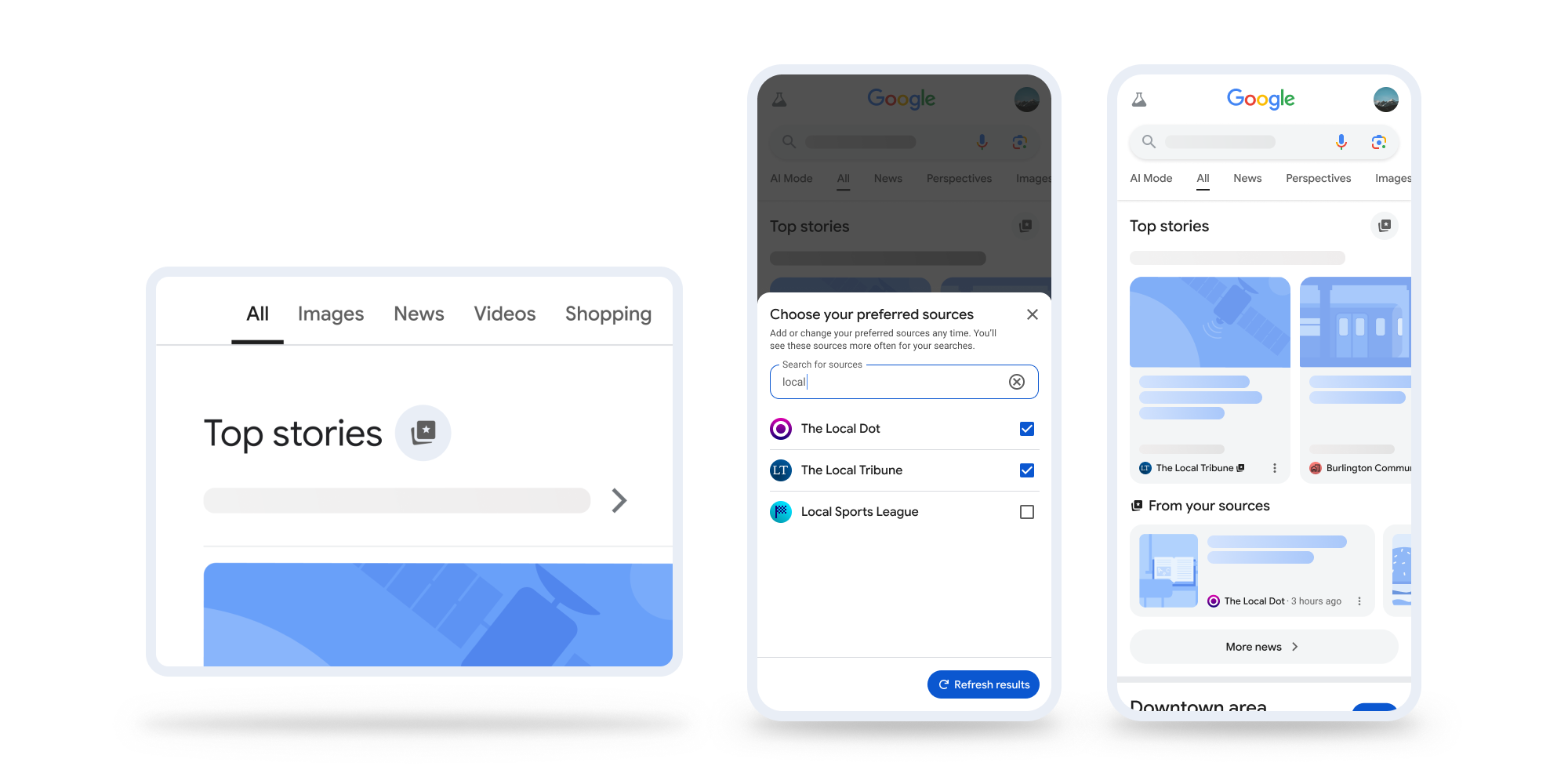
Firma podkreśla, że dzięki funkcji Preferred sources użytkownicy mogą łatwiej filtrować treści i szybciej docierać do sprawdzonych publikacji, a wydawcy – budować lojalność i zwiększać swoją widoczność w wynikach organicznych.
To też w sumie fajna odskocznia od wszechobecnych newsów związanych z kolejnymi rozwiązaniami opartymi na sztucznej inteligencji – akurat ta funkcja nie ma z nią nic wspólnego.
Autor artykułu
Szymon Anioł
Szymon tworzy SEO Newsy i redaguje artykuły ekspertów na naszym blogu. Pisanie do internetu to dla niego czysta frajda, zwłaszcza gdy może wykazać się kreatywnością. Interesuje się neuro- i psychomarketingiem. Po godzinach miłośnik dobrej muzyki, filmów i podróży.


