
Google pozwał SerpApi, zarzucając firmie masowe scrapowanie wyników wyszukiwania, omijanie zabezpieczeń i odsprzedaż danych w formie płatnego API. Spór dotyczy nie tylko klasycznych linków, ale też elementów objętych licencjami, takich jak panele wiedzy czy grafiki w SERP-ach. SerpApi twierdzi, że korzysta z danych publicznie dostępnych dla każdego użytkownika.
Google walczy ze scrapowaniem SERP-ów i pozywa SerpApi. Unia Europejska przygląda się Google i temu, jak wykorzystują treści zewnętrzne do generowania swoich odpowiedzi AI. ChatGPT z lokalnymi panelami wiedzy. Poza tym: Gemini 3 Flash w Trybie AI oraz dwie znane twarze Google o strategiach pozycjonowania w wyszukiwarkach generatywnych.
Google pozywa SerpApi…
Google wchodzi na ścieżkę sądową z firmą SerpApi. Gigant z Mountain View złożył pozew, w którym zarzuca im nielegalne pobieranie i odsprzedaż danych z wyników wyszukiwania.
W skrócie: według Google SerpApi miało omijać zabezpieczenia techniczne, podszywać się pod realnych użytkowników i masowo scrapować SERP-y – w tym elementy objęte licencjami, jak panele wiedzy, zdjęcia czy rozszerzone dane widoczne w wynikach.
Te informacje były następnie udostępniane klientom w formie płatnego API. Google twierdzi, że standardowe blokady i mechanizmy ochrony nie wystarczały, dlatego sprawa trafiła do sądu.
Oczywiście SerpApi się broni, argumentując, że udostępnia wyłącznie dane, które są publicznie widoczne w przeglądarce, bez logowania – czyli takie, które każdy może zobaczyć.
Firma sugeruje też, że pozew to próba zablokowania konkurencji i narzędzi, z których korzystają m.in. specjaliści od pozycjonowania oraz twórcy rozwiązań AI.
Cała sprawa wpisuje się w szerszy trend. Google coraz mocniej walczy z masowym pobieraniem danych z wyszukiwarki, a podobne spory – m.in. z udziałem Reddita – pokazują, że temat scrapowania staje się jednym z głównych aspektów konfliktu między big techami a firmami budującymi narzędzia oparte na danych.
… a Unia Europejska pozywa Google
No właśnie – Google wytacza prawnicze działa, ale samo też musi się bronić. Organy UE wszczęły właśnie postępowanie w sprawie wykorzystywania przez firmę treści zewnętrznych wydawców w swoich odpowiedziach generowanych przez AI – w AI Mode oraz AI Overviews.
Sedno problemu jest dość oczywiste i już wielokrotnie o nim wspominałem w ramach SEO News’ów (m.in. tutaj). Google coraz częściej odpowiada użytkownikom bezpośrednio w wynikach wyszukiwania – za pomocą AIO i innych funkcji generatywnych. Dla użytkownika to wygodne, ale dla wydawców już niekoniecznie.
Ich treści są wykorzystywane do tworzenia odpowiedzi, ale kliknięcia mocno na tym cierpią – coraz więcej zapytań kończy się na tzw. zero-click search.
Wydawcy narzekają, że nie mają realnej kontroli nad tym, czy ich treści są używane przez AI. Owszem, istnieją pewne techniczne rozwiązania (np. mechanizm opt-out), ale problem w tym, że ich użycie zwykle kończy się utratą widoczności w klasycznej wyszukiwarce.
A to w zasadzie stawia ich pod ścianą: albo zgadzasz się na wykorzystanie treści przez AI, albo wypadasz z gry o ruch organiczny.
Google z kolei odpowiada, że to naturalna ewolucja wyszukiwania. Skoro treści są publicznie dostępne i indeksowane, mogą być używane do ulepszania wyników.
Wydawcy podkreślają, że generowanie odpowiedzi przez AI to zupełnie nowy sposób wykorzystania ich pracy – taki, który powinien podlegać osobnym zasadom, a być może także wynagrodzeniu.
UE będzie teraz przyglądać się stanowiskom obu stron. Jeśli uzna, że Google faktycznie nadużywa swojej pozycji, być może pojawią się jakieś nowe regulacje: lepsze mechanizmy opt-out, obowiązkowe atrybucje źródeł lub modele licencjonowania treści.
ChatGPT wprowadza lokalne panele wiedzy
ChatGPT powoli przestaje być tylko chatbotem do rozmów i researchu – OpenAI właśnie testuje w nim lokalne panele wiedzy, zresztą bardzo podobne do tych, które od lat znamy z Google.
Zobacz też:
Jak to wygląda w praktyce? Gdy zapytasz ChatGPT o restaurację, firmę usługową albo konkretne miejsce, a następnie klikniesz nazwę obiektu w odpowiedzi, po prawej stronie interfejsu może pojawić się panel z dodatkowymi informacjami.
Zobaczysz tam m.in. nazwę firmy, zdjęcia, lokalizację, dane kontaktowe czy godziny otwarcia. Innymi słowy – klasyczny local knowledge panel, tylko że wewnątrz chatbota AI.
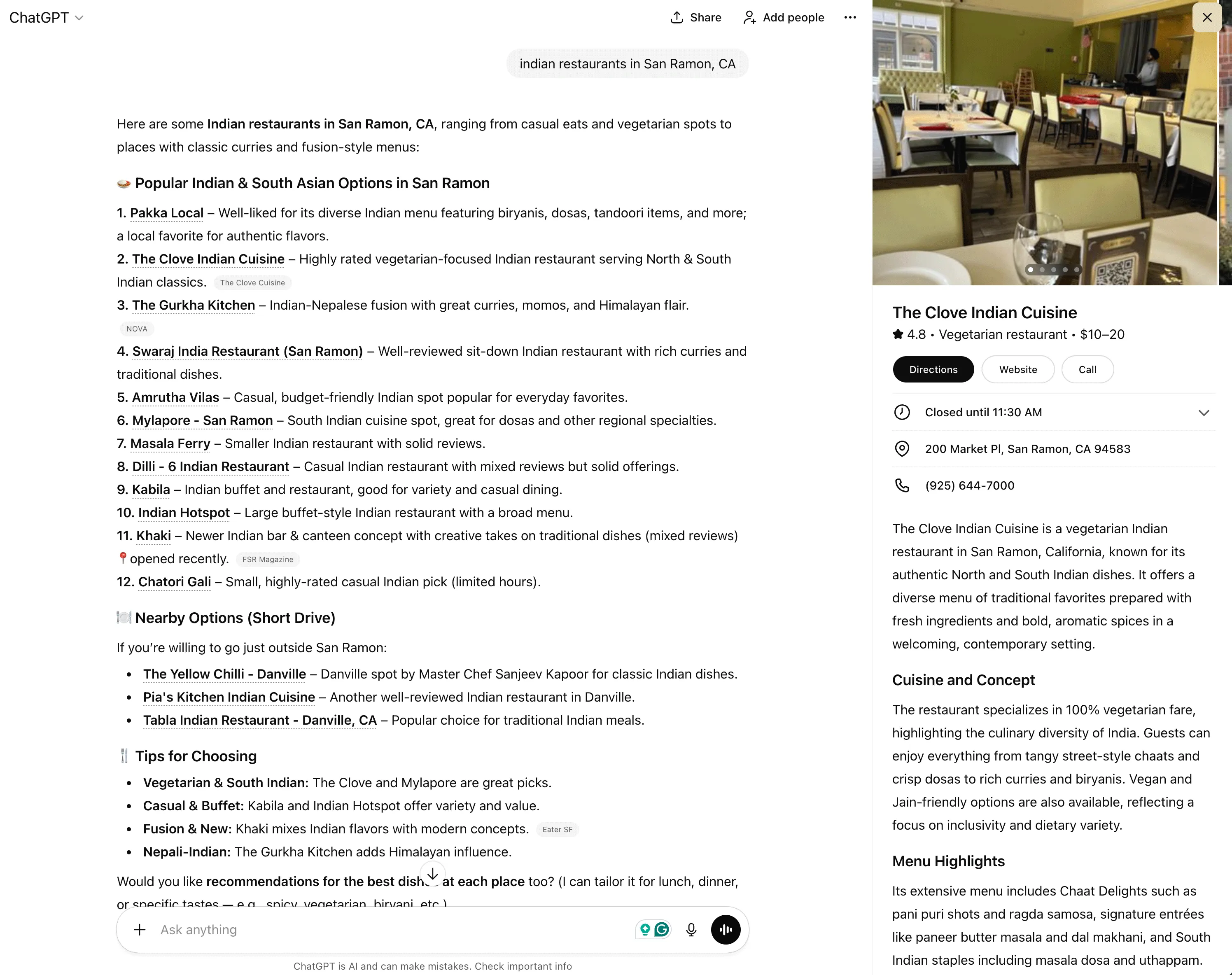
Co ważne, te elementy nie wyświetlają się automatycznie przy każdym zapytaniu. Trzeba wejść w interakcję z wynikiem, kliknąć nazwę miejsca albo punkt na mapie. Wygląda więc na to, że ChatGPT traktuje je jako warstwę pogłębiającą odpowiedź, a nie główną bazę wyników.
Najwięcej wątpliwości budzi źródło tych danych. Samo OpenAI oficjalnie nie podaje, skąd dokładnie pochodzą informacje. Krążą jednak opinie, że mogą być agregowane z wielu źródeł – w tym z publicznych profili firm, katalogów lokalnych i map.
Część specjalistów zauważa też podobieństwa do danych znanych z profili firm w Google.
Udało mi się odtworzyć tę funkcję u siebie – wygląda to tak:
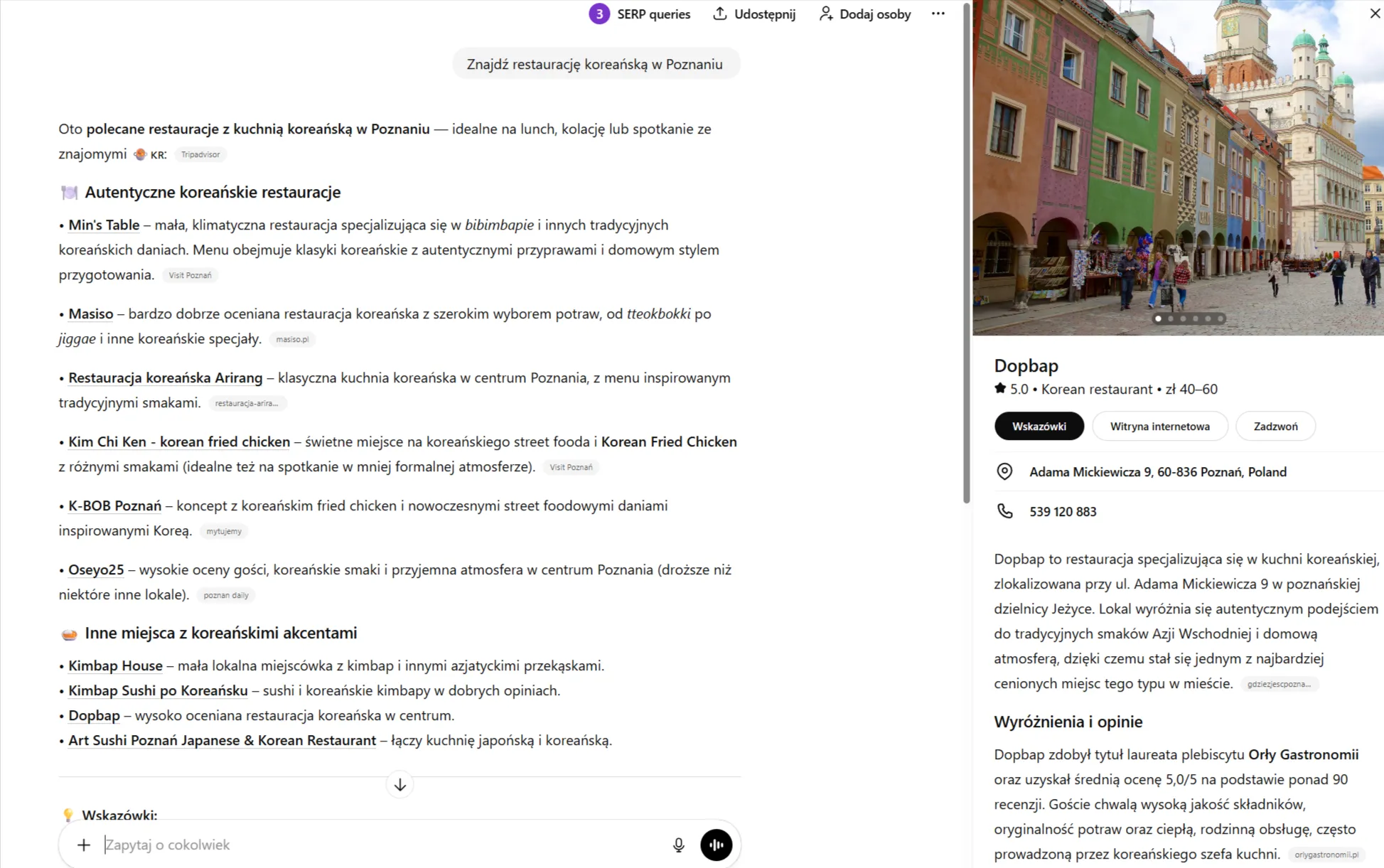

Gemini 3 Flash w AI Mode
Google szybciutko integruje swój nowy model AI z odpowiedziami w AI Mode.
Gemini 3 Flash został zaprojektowany z myślą o jednym: szybkości. Google stawia tu na błyskawiczne reakcje, niskie opóźnienia i sprawne radzenie sobie z pytaniami, które wymagają logicznego myślenia, porównań czy krótkich analiz.
Zobacz też:
To dokładnie ten typ modelu, który wydaje się idealnie pasować do wyszukiwarki generatywnej, gdzie użytkownik oczekuje odpowiedzi tu i teraz, a nie po kilku sekundach.
W praktyce powinniśmy więc dostać super płynne rozmowy, szybsze podsumowania i mniejsze opóźnienia przy bardziej złożonych zapytaniach.
Oczywiście Gemini 3 Flash hula nie tylko w funkcjach związanych z wyszukiwaniem. Jest też dostępny dla wszystkich w aplikacji Gemini, a także w narzędziach Google dla deweloperów.
Przy okazji firma chwali się też niską „tokenożernością” nowego modelu – podobno potrafi on dostosowywać intensywność swoich działań. W przypadku złożonych zadań będzie myślał dłużej, ale zużyje przy tym średnio o 30% mniej tokenów niż poprzednik, czyli Gemini 2.5.
J. Mueller i D. Sullivan z Google: SEO dla wyszukiwarek AI niczym się nie różni od klasycznego
W podcaście Search Off the Record spotkali się ostatnio John Mueller i Danny Sullivan z Google, żeby pogadać nieco o pozycjonowaniu w dobie AI.
Padło krótkie, mocne stwierdzenie: SEO robione pod AI to nadal po prostu SEO. Bez żadnych nowych zasad czy magicznych sztuczek.
Panowie podkreślili, że pojawienie się AI w wyszukiwarce nie oznacza, że trzeba wszystko robić od nowa. Fundamenty pozostają te same – treści mają być tworzone przede wszystkim dla ludzi, a nie pod algorytm czy model językowy.
Jeśli coś jest wartościowe, unikalne i faktycznie pomaga użytkownikowi, to ma sens zarówno w klasycznych wynikach, jak i w odpowiedziach generowanych przez AI.
W dobie generycznych treści tworzonych na jedno kopyto wygrywać mają przede wszystkim materiały oparte na doświadczeniu, ekspertyzie i własnej perspektywie – czyli takie, których nie da się łatwo skleić z dziesięciu podobnych artykułów.
Sullivan i Mueller sugerują też, że warto myśleć szerzej o swojej widoczności online – nie tylko w kontekście pisania tekstów, ale także wrzucania contentu audio, wideo i ogólnie treści interaktywnych/wizualnych. To one coraz częściej stają się naturalną częścią wyszukiwań i odpowiedzi AI.
Autor artykułu
Szymon Anioł
Szymon tworzy SEO Newsy i redaguje artykuły ekspertów na naszym blogu. Pisanie do internetu to dla niego czysta frajda, zwłaszcza gdy może wykazać się kreatywnością. Interesuje się neuro- i psychomarketingiem. Po godzinach miłośnik dobrej muzyki, filmów i podróży.


