
Analiza Semrush wskazuje, że treści napisane przez ludzi mają 8x większą szansę na zajęcie pierwszego miejsca wynikach wyszukiwania. Boty AI już teraz indeksują więcej stron niż Googlebot. Nowy wpis na blogu Google, który tłumaczy techniczne aspekty crawlowania. Oprócz tego: trwa naprawa błędu w GSC, który zawyżał liczbę wyświetleń, a także John Mueller o tym, dlaczego na zakończenie core update’ów musimy czekać nawet kilka tygodni.
1. Treści napisane przez ludzi mają większe szanse na TOP 1 w Google
Z analizy przeprowadzonej przez Semrush wynika, że content tworzony ludzką ręką wyraźnie dominuje na najwyższych pozycjach w Google, pomimo rosnącej popularności narzędzi AI.
Badanie skupiło się na analizie TOP 10 wyników wyszukiwania i objęło ok. 40 000 wpisów blogowych (z 200 000 różnych stron) i 20 000 słów kluczowych. W oczy z pewnością rzucają się poniższe liczby:
- 80% treści na 1. miejscu w SERP-ach było napisanych przez ludzi,
- tylko 9% topowych wyników to treści wygenerowane w całości przez sztuczną inteligencję.
Teoretycznie daje nam to prosty wniosek: teksty pisane przez „ludzkich” specjalistów mają 8 razy większe szanse na pojawienie się w TOP 1 w Google.
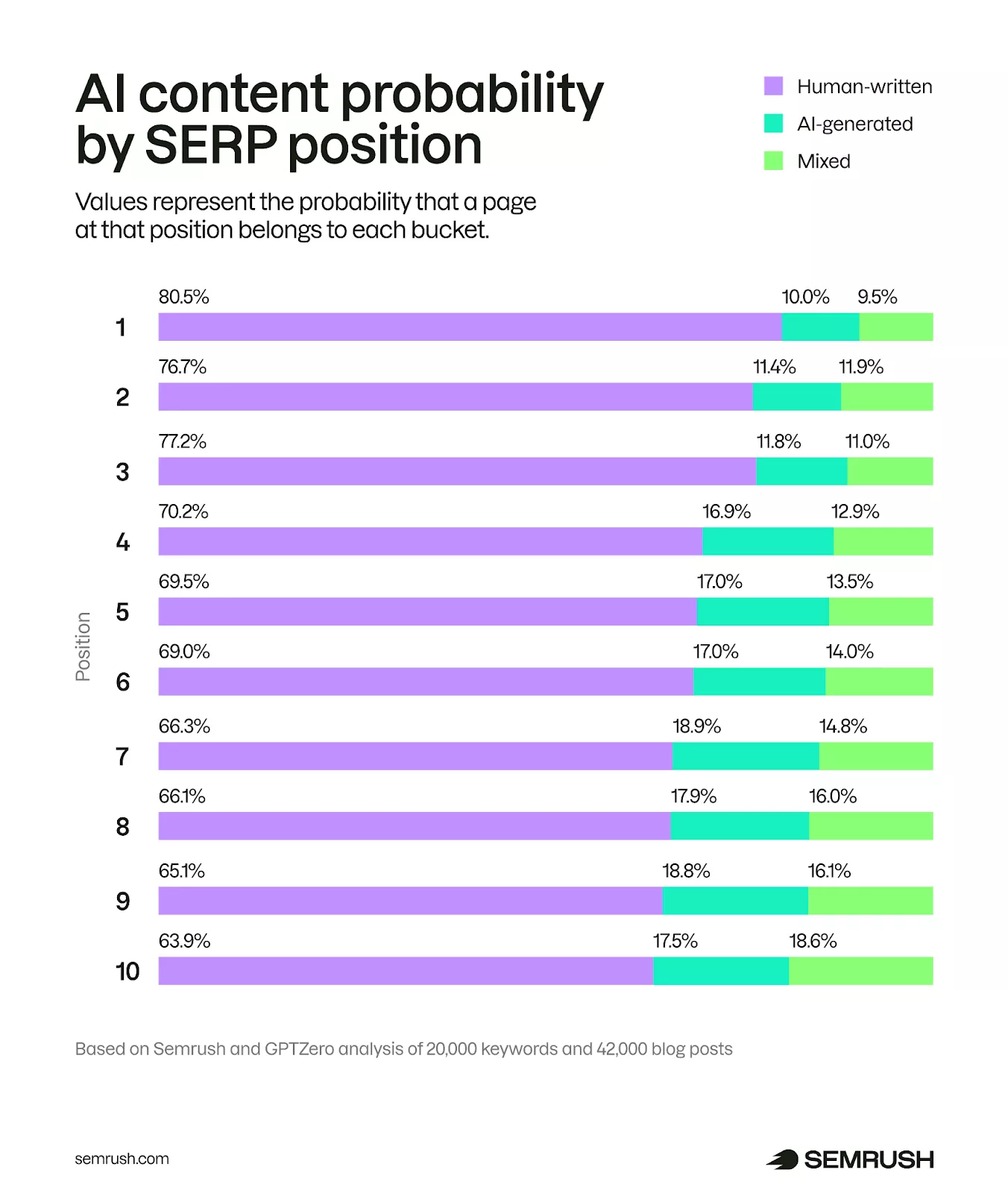
Autorzy badania podkreślają jednak, że to wcale nie oznacza, że content AI nie dowozi. Przeciwnie – takie treści również trafiają do pierwszej dziesiątki w wynikach. Po prostu mają wyraźne problemy z „doczołganiem” się na sam szczyt.
Ciekawy jest rozdźwięk między tym, co pokazują dane, a tym, co deklarują specjaliści od pozycjonowania. Większość z nich uważa, że treści AI są równie skuteczne albo nawet lepsze od tych tworzonych przez ludzi. Tymczasem liczby sugerują coś odwrotnego.

Na koniec ważna uwaga: Semrush nie ukrywa, że do odróżnienia contentu w trakcie tej analizy wykorzystano zwykłe detektory AI. A te, jak wiadomo, radzą sobie różnie i często dostarczają sprzeczne wyniki.
Tutaj znajdziecie link do pełnego badania: Does AI content rank well in search?
2. ChatGPT indeksuje więcej niż Google
Ruch generowany przez boty AI rośnie mega dynamicznie – to już wiemy. Ale nie wiedzieliśmy, że w wielu przypadkach przewyższa już aktywność botów Google!
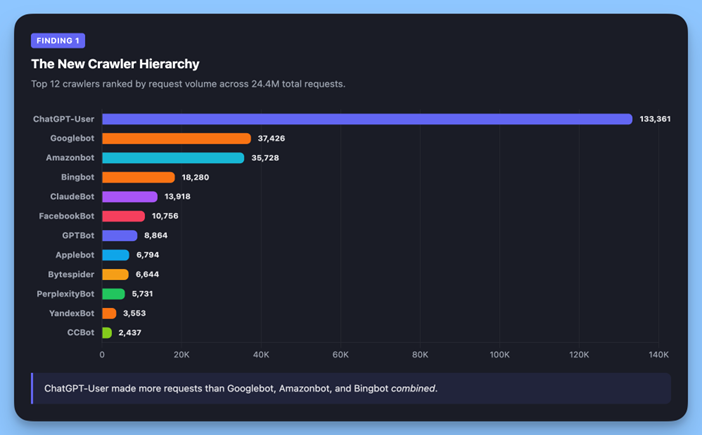
Tak przynajmniej wynika z analizy wykonanej przez platformę do automatyzacji Alli AI. To nie Googlebot generuje największy ruch, ale crawler powiązany z ChatemGPT.
Sprawdzono:
- 24 411 048 żądań,
- na ponad 78 000 podstron,
- w 69 witrynach.
W badanej próbce robot ChatGPT-User wykonywał ponad 3,6 razy więcej zapytań niż Googlebot, a jeśli doliczyć do tego drugi crawler OpenAI (GPTBot), przewaga nad Google jeszcze rośnie.
Warto wiedzieć
OpenAI korzysta z dwóch różnych crawlerów o innych funkcjach. ChatGPT-User odpowiada za pobieranie treści w czasie rzeczywistym, gdy użytkownik zadaje pytanie, i to on decyduje, czy dana strona pojawi się w odpowiedziach generowanych przez ChatGPT. Z kolei GPTBot służy do zbierania danych treningowych dla modeli. Wiele stron blokuje jednego z nich, nie rozumiejąc, że każdy wpływa na widoczność w inny sposób.
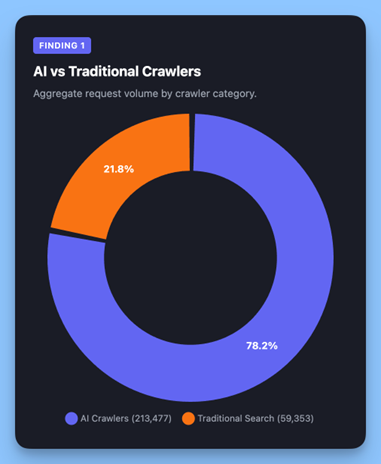
Różnice w działaniu crawlerów AI i Google są też widoczne na poziomie technicznym. Boty AI są znacznie szybsze i skuteczniejsze w pojedynczych zapytaniach – osiągają niemal stuprocentowy wskaźnik poprawnych odpowiedzi serwera.
Wynika to z faktu, że działają bardziej wybiórczo i pobierają konkretne strony w odpowiedzi na zapytania użytkowników. Nie eksplorują całej struktury serwisu tak jak Google.
W badaniu zwrócono też uwagę na to, że choć pojedyncze zapytania crawlerów AI są „lekkie” i szybkie, ich skala powoli staje się wyzwaniem. Ogromna liczba żądań może obciążać serwery i wpływać na koszty utrzymania infrastruktury.
Link do pełnej analizy Alli AI zostawiam tutaj: ChatGPT Now Crawls 3.6x More Than Googlebot: What 24M Requests Reveal
3. Google wyjaśnia, jak działa ich system indeksowania
Gary Illyes z Google opublikował na oficjalnym blogu firmy nowy wpis, w którym tłumaczy wiele ciekawych kwestii związanych z charakterystyką Googlebota, mechanizmem indeksowania czy limitami rozmiarów dla plików, które są skanowane i pobierane przez różne roboty wyszukiwarki.
Zobacz też:
W artykule znalazło się dużo technicznych zagadnień związanych z crawlowaniem stron, więc nie będę się tutaj mocno rozpisywał – każdy zainteresowany może to sobie sprawdzić samodzielnie.
Illyes odpowiada m.in. na takie pytania:
- Czym właściwie jest Googlebot?
- Limit pliku HTML 2 MB dla pojedycznego adresu URL – co się dzieje po jego przekroczeniu?
- Jakie są inne limity dla pozostałych plików?
- Co dzieje się po pobraniu pliku HTML strony i jaki ma w tym udział WRS, czyli system renderowania?
- Jak i gdzie przerwarzane są elementy w JavaScript i style (CSS)?
Link do artykułu znajdziecie tutaj: Googlebot od kuchni: wyjaśniamy indeksowanie, pobieranie i przetwarzane przez nas bajty.
4. Trwa naprawa poważnego buga w GSC, którego wykryto w… maju 2025 roku
Wspomniany błąd w Google Search Console pojawił się dokładnie 13 maja 2025 r. i dotyczył sposobu zbierania danych. Od tego momentu właściciele stron mogli widzieć lepsze niż w rzeczywistości wyniki widoczności w wyszukiwarce.
Błąd nie wpłynął jednak na kliknięcia ani faktyczny ruch na stronach. Zafałszowany został wyłącznie wskaźnik wyświetleń – ale to wystarczyło, żeby zaburzyć też inne metryki, np. średnie pozycje.
W efekcie część analiz SEO prowadzonych w ostatnich miesiącach mogła opierać się na nieprecyzyjnych danych.
Zobacz też:
Google rozpoczęło już proces naprawy i aktualizacji raportów. W najbliższym czasie użytkownicy mogą zauważyć spadki liczby wyświetleń w raportach, ale nie powinny one budzić niepokoju – będzie to po prostu powrót do bardziej wiarygodnych danych.
Nie znamy dokładnej skali błędu ani tego, jak bardzo zawyżone były wykresy. Nie wyjaśniono też szczegółowo przyczyny technicznej problemu. Wiadomo jedynie, że poprawka będzie wdrażana stopniowo i może minąć kilka tygodni, zanim dane w pełni się ustabilizują.
5. Dlaczego wdrażanie core updates trwa tak długo? Google tłumaczy
Zastanawialiście się kiedyś, dlaczego główne aktualizacje algorytmu Google nie pojawiają się od razu w pełnej formie, tylko musimy czekać na ich zakończenie po kilka tygodni? Z odpowiedzią spieszy niezastąpiony John Mueller.
Wyjaśnił on, że core update to nie jest „jeden guzik”, który Google przełącza i gotowe. To zestaw szerokich zmian w wielu systemach i komponentach algorytmu wyszukiwania, nad którymi pracują różne zespoły wewnątrz firmy.
Te elementy nie są wypuszczane jednocześnie, tylko krok po kroku – w miarę jak są gotowe i przetestowane. Dlatego cały proces może trwać nawet dwa/trzy tygodnie, zanim update zostanie w pełni wdrożony we wszystkich obszarach wyszukiwarki.
To wyjaśnia, dlaczego widzimy tak mocne wahania w rankingach podczas rolloutu. W pierwszych dniach mogą pojawiać się duże zmiany pozycji, potem lekka stabilizacja, a następnie kolejne przesunięcia – wszystko dlatego, że różne komponenty wpływające na ranking są aktywowane w różnych momentach.
Mueller podkreślił, że Google nie ogłasza formalnych etapów zmian, ale techniczna natura wdrożenia sprawia, że taki stopniowy przebieg jest normalny.
Każdy core update jest inny, bo zależy od tego, nad czym pracowały konkretne zespoły przed jego wypuszczeniem. Nie ma jednego sztywnego procesu, który jest uruchamiany dla każdej aktualizacji.
To kolejny powód, dla którego prognozowanie kolejnych zmian czy przewidywanie ich efektów jest trudne – kolejna aktualizacja może dotykać zupełnie innych komponentów niż poprzednia.
Autor artykułu
Szymon Anioł
Szymon tworzy SEO Newsy i redaguje artykuły ekspertów na naszym blogu. Pisanie do internetu to dla niego czysta frajda, zwłaszcza gdy może wykazać się kreatywnością. Interesuje się neuro- i psychomarketingiem. Po godzinach miłośnik dobrej muzyki, filmów i podróży.


