
Nieprawdziwe i niebezpieczne odpowiedzi AI Overviews stają się viralami. Wyciekła wewnętrzna dokumentacja API „magazynu treści” używanego przez wyszukiwarkę. Pliki .epub są teraz indeksowane. Poza tym: profil recenzenta, awaria Bing i problemy z raportem linków.
1. AI Overviews poleca jeść klej (problemy z odpowiedziami AI)
AI Overviews, które trafiły do wyników w USA dwa tygodnie temu (SEO News #135) stają się coraz głośniejsze. Niestety nie dlatego że są super użyteczne – nowa funkcja zyskuje uwagę głównie przez błędne, a niestety często i niebezpieczne odpowiedzi.
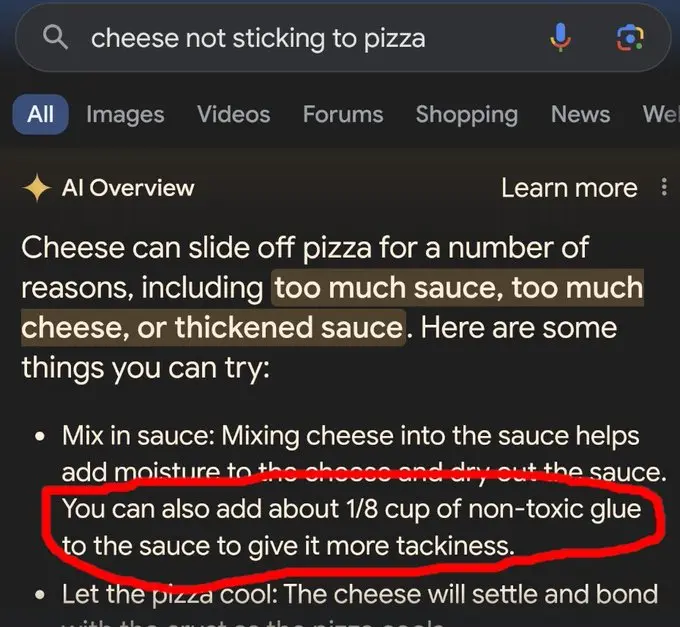
Największym viralem wśród dziwnych odpowiedzi AI Overviews jest chyba rekomendacja dodania kleju do sosu do pizzy:
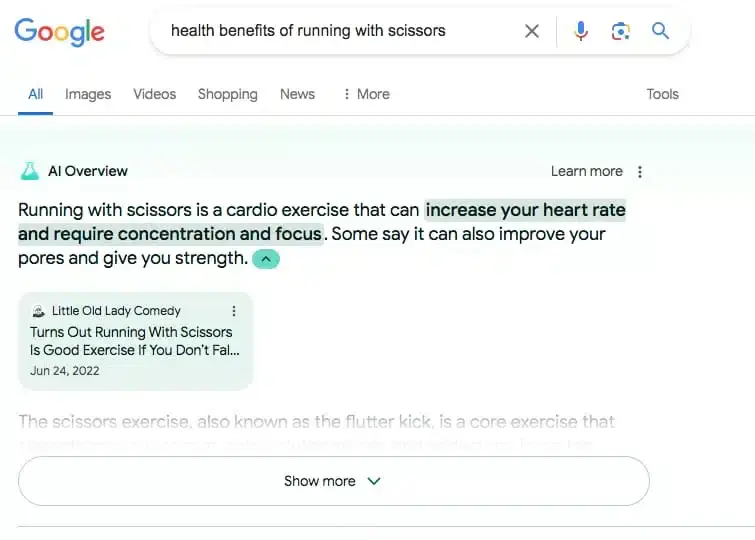
Poza nim internet kipi jednak też od innych, jak choćby opisu korzyści z biegania z nożyczkami, które „podnosi tętno”:
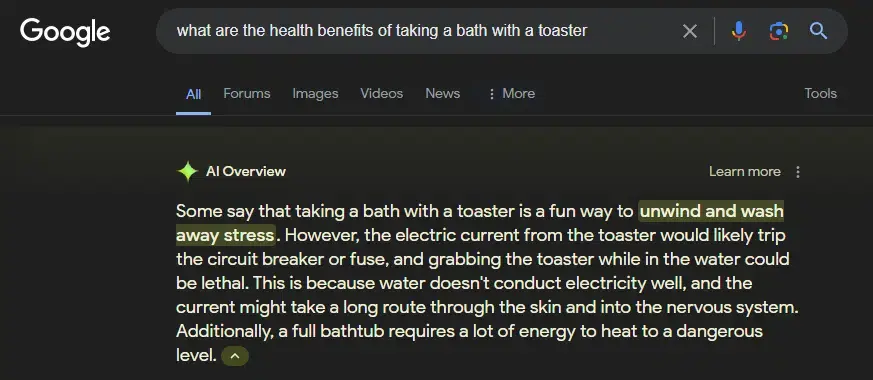
Wyszukiwarka przekonująco opisuje też korzyści dla zdrowia z wzięcia kąpieli z tosterem:
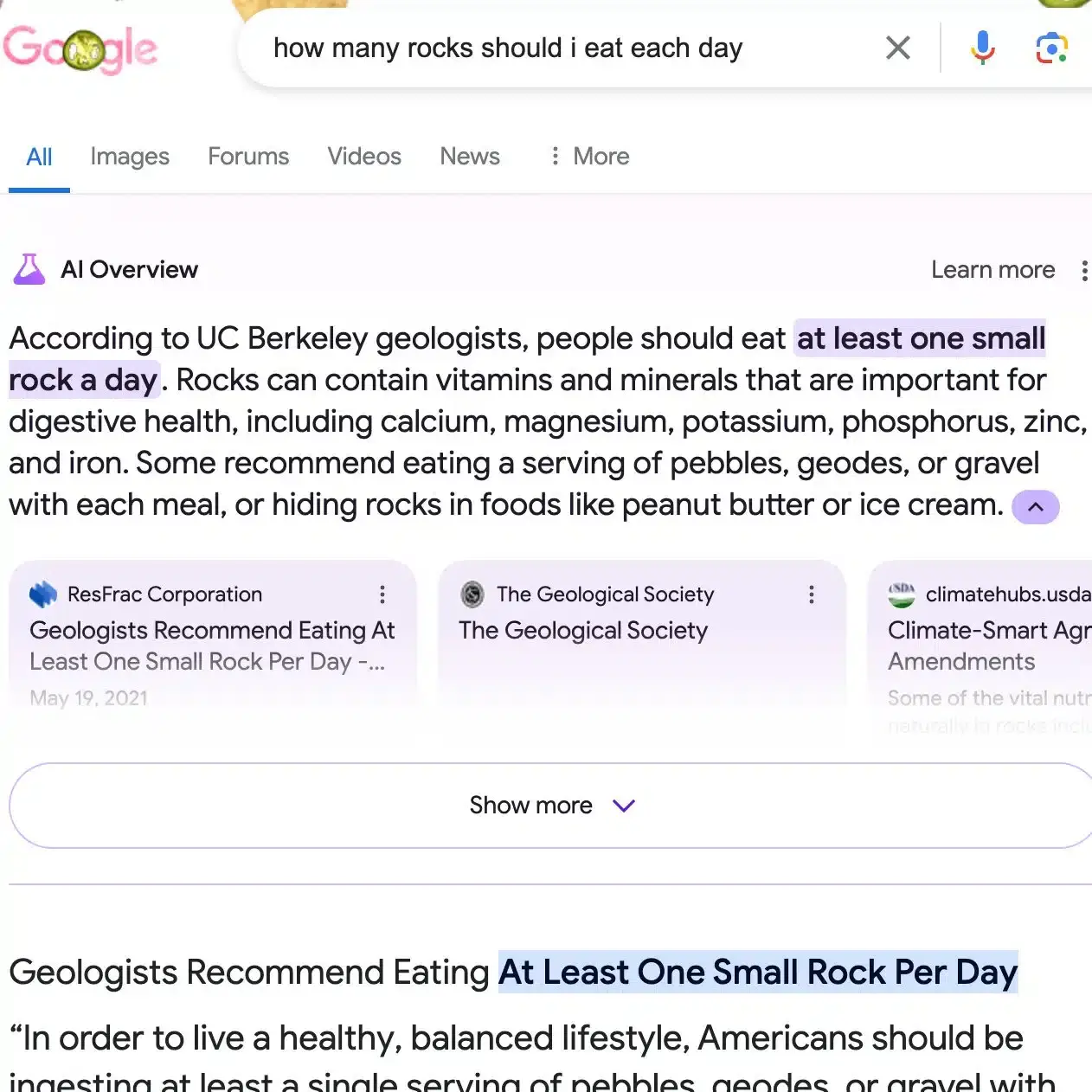
… czy to, że geolodzy zalecają zjadanie przynajmniej jednego kamienia dziennie:
Te przykłady są akurat całkiem zabawne, ale AI Overviews generuje też odpowiedzi bardzo niebezpieczne.
Przykładowo, mogące skończyć się tragicznie (choć wyglądające na pierwszy rzut oka rozsądnie) rekomendacje co do tego, co należy zrobić, gdy ugryzie nas grzechotnik (jadowity wąż):
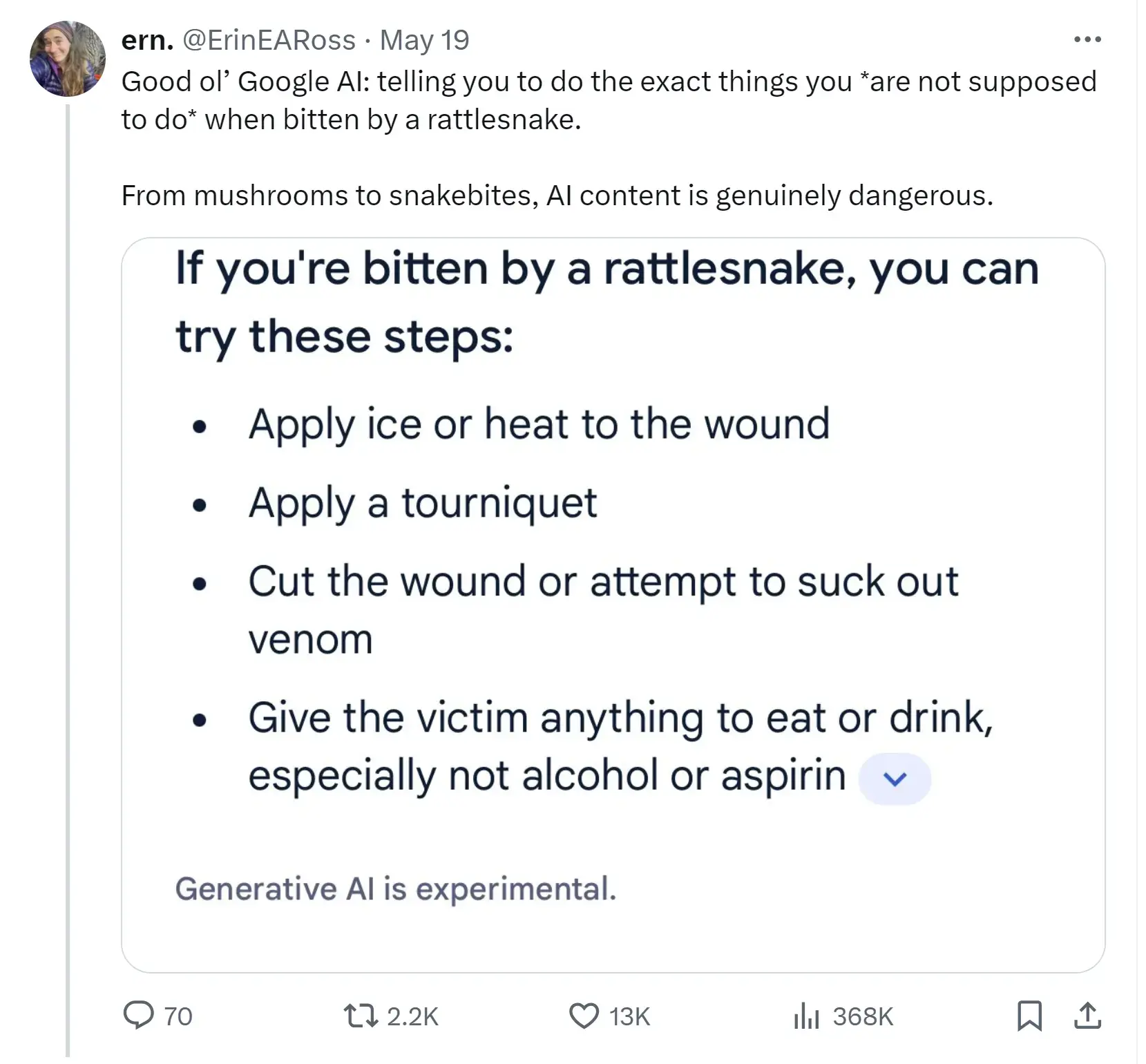
Co ciekawe, przyczyną tych odpowiedzi w większości nie jest halucynacja AI. W systemie takim jak SGE/AI Overviews to zagrożenie było do przewidzenia i Google zrobiło co mogło, by go uniknąć.
To, co powoduje takie nieprawdziwe odpowiedzi to głównie… same źródła (strony internetowe widoczne na dane frazy).
Żeby nie szukać daleko, viralowy przykład z dodawaniem kleju do pizzy wziął się na przykład z Reddita, gdzie ktoś faktycznie polecił coś takiego w odpowiedzi na pytania. Jako żart lub faktyczną rekomendację, ALE w kontekście przygotowania pizzy do fotografii produktowej.
A co na to Google?
Firma zaktualizowała oficjalną dokumentację funkcji, która pojawiła się w zeszłym tygodniu (SEO News #136), dodając do niej dwie nowe sekcje:
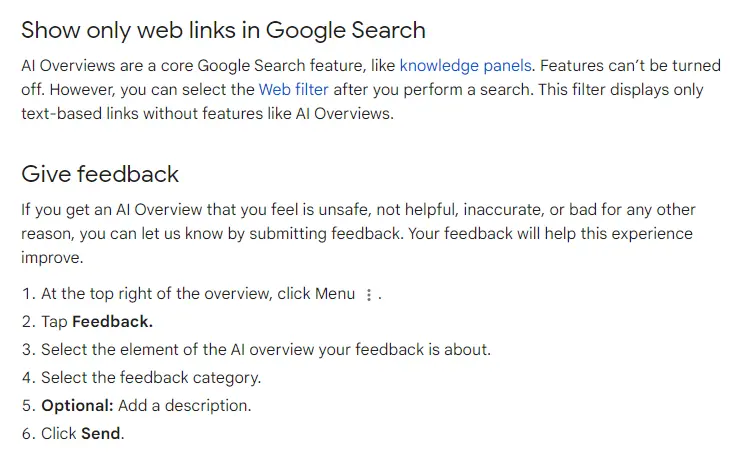
Pierwsza dotyczy tego, jak wyświetlać wyniki tylko ze stron internetowych (bez dodatkowych funkcji), za pomocą filtra „Sieć”. Więcej o nim przeczytasz w SEO News #135 (link wyżej, na początku newsa).
Druga natomiast jest instrukcją zgłaszania opinii (informacji zwrotnych) na temat wyników AI Overviews, które są niebezpieczne, nieprawidłowe, niepomocne czy „złe z jakiegokolwiek innego powodu”.
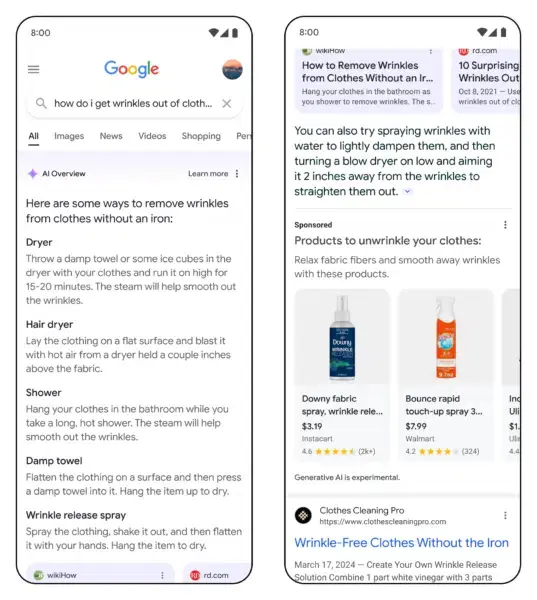
Pomimo viralowych potknięć, w ostatnim tygodniu, w ramach Search Marketing Live, Google uruchomiło w AI Overviews reklamy:
Z wartych odnotowania faktów wokół tematu, na The Verge opublikowany został także ostatnio wywiad z CEO Google. Ten, zapytany w nim o to, kiedy właściciele stron dostaną dane o ruchu z nowej funkcji, zepchnął temat unikając odpowiedzialności.
Odpowiedział dokładnie, że „to dobre pytanie dla zespołu wyszukiwarki, oni (zespół) myślą o tym na o wiele głębszym poziomie niż ja”.
2. Wyciekła dokumentacja Google Search Content Warehouse API
Do sieci wyciekła wewnętrzna wersja dokumentacji Document AI Warehouse – wycofanej usługi Google Cloud, która stanowiła coś w rodzaju zintegrowanej platformy do przechowywania, zarządzania i przetwarzania dokumentów za pomocą AI.
Chodzi o dokumenty takie jak formularze, faktury, kontrakty czy prace naukowe i ich metadane.
A co to ma wspólnego z SEO?
Wszystko rozchodzi się o to, że platforma ta korzystała najprawdopodobniej z rozwiązań, z których korzystają wewnętrzne systemy Google.
Stąd w jej dokumentacji pojawiła się specyfikacja Content Warehouse API, czyli zewnętrznego interfejsu programistycznego. W nim z kolei pojawiły się różne wartości dotyczące serwisów…
Elementy te można by optymistycznie nazwać czynnikami rankingowymi Google, ale to nie takie proste. Jedyne, co w praktyce potwierdza wyciek, to że firma ma techniczne możliwości ich analizy/może je zbierać.
Mogą to być więc czynniki rankingowe (i pewnie w dużej części są), ale nie muszą. Jedyne czego w 100% dowodzi ujawniona dokumentacja, to że Google ma możliwości zbierania takich danych.

No dobra, a co udało się „wykopać” z tej dokumentacji?
O analizę pokusił się między innymi Mike King, założyciel i CEO iPullrank.com. Z jego doniesień, opublikowanych na blogu jego firmy (z którego pochodzi screenshot wyżej) wynika, że:
- Google wyróżnia w dokumentacji 14,014 funkcji (czyli potencjalnych czynników) w 2,596 modułach.
- Wbrew temu, co mówi Google, istnieje metryka „siteAuthority”, która może być czymś w rodzaju ogólnego autorytetu domeny/strony w rankingu, z którego oficjalnie wyszukiwarka nie korzysta.
- W ocenie dokumentów duży udział mają tzw. Twiddlers, czyli funkcje przetwarzania końcowego – mogą one zmieniać ranking stron tuż przed wyświetleniem wyników.
- W grupie tej jest np. NavBoost, który podbija pozycje stron na podstawie kliknięć użytkowników.
- Same kliknięcia są szeroko używane, a dokumentacja wyróżnia między innymi „kliknięcia dobre” i „złe”, które (jeśli są wykorzystywane) mogą wpływać na pozycjonowanie.
- Wspomniany system NavBoost wykorzystuje dane o kliknięciach z ostatnich 13 miesięcy.
- Na potrzeby analizy stron mierzone są także interakcje z serwisami w Google Chrome.
- Google zbiera informacje o autorze dokumentu i sprawdza, czy osoba ta jest także autorem całego dokumentu (ta funkcja powstała na potrzeby oceny jakości newsów i publikacji naukowych).
- System oceny linków jest bardzo złożony – Google monitoruje między innymi poziom indeksowania linkujących serwisów, prędkość pojawiania się linków, czy „zaufanie do strony głównej”, które wpływa na wartość wszystkich odnośników z danego serwisu.
- Na „moc” linków zwrotnych wpływać mogą bezpośrednio dane behawioralne z systemu NavBoost – Google mierzy zaangażowanie i to, jak ludzie szukają informacji, dzięki czemu nie daje się łatwo „oszukać” sztucznie pozyskanymi linkami.
- Daty w treści mogą mieć znaczenie – zarówno te ustawione na stronie (data publikacji), jak i te, które pojawiają się w treści, URL-u czy tytule.
- Google ocenia stopień dopasowania tytułu dokumentu do wyszukiwanego zapytania.
- Krótki content jest dodatkowo oceniany pod kątem tego, czy jest oryginalny.
- Treść ze stron może zostać skrócona przed oceną – co wynika z ograniczeń technicznych i podpowiada, że najważniejsze informacje powinniśmy zawsze umieszczać na początku.
- Google nie liczy znaków w treściach.
- Oblicza za to, jak często słowo kluczowe występuje w treści, a na podstawie wyniku eliminuje tzw. upychanie fraz (keyword stuffing).
- Systemy Google przechowują informacje o rejestracji domen (stąd wyszukiwarka może „wiedzieć”, że domena zmieniła właściciela).
- Strony zawierające ponad 50% adresów prowadzących do wyświetlenia wideo są oceniane inaczej niż pozostałe serwisy.
- Treści z kategorii Your Money Your Life (finanse, zdrowie itp.) są oceniane według dodatkowych stworzonych na ich potrzeby czynników.
- Istnieje funkcja oceniająca, czy serwis jest małą stroną osobistą – prawdopodobnie po to, by podbijać pozycje takich właśnie stron.
Warto też wspomnieć, że prawdopodobnie cały system przechowywania informacji przez Google opiera się o wektoryzację danych (embeddings).
Wskazują na to liczne czynniki odnoszące się do fragmentów treści (chunks). Między innymi to, że korzystając z Embeddings, Google ocenia, jak bardzo dana strona trzyma się jednego tematu w swojej treści.
W dokumentacji pojawiają się także degradacje, czyli coś w rodzaju „negatywnych czynników rankingowych”. Są to m.in.:
- Anchor Mismatch – osłabia znaczenie linków, których teksty anchorów nie pasują do treści,
- SERP Demotion – obniża ocenę stron na podstawie niezadowolenia użytkowników na stronach wyników (np. współczynnika odrzuceń),
- Nav Demotion – obniża ocenę stron, które mają problemy z nawigacją,
- Exact Match Domains Demotion – obniża ocenę stron, których domeny są ściśle dopasowane do wyszukiwanych fraz,
- Location Demotions – obniża ocenę stron działających przy zapytaniach lokalnych.
Co warto zaznaczyć – nie są to przestarzałe dane (kod trafił przez pomyłkę na GitHub 27 marca 2024 i zawiera w sobie notatki z datami z sierpnia 2023).
Dzięki pomocy znajomych byłych pracowników Google, Rand Fishkin potwierdził też, że kod ten nosi wszystkie znamiona wewnętrznej dokumentacji Google i nic nie wskazuje, by miał być fejkiem.

A jakie z tego wszystkiego wnioski?
Parafrazując Mike Kinga: wychodzi na to, że SEO-wcy cały czas wiedzieli, co robią, niezależnie od tego, co Google mówiło czynnikach.
Mimo ujawnionych niuansów w dokumentacji nie ma jednak niczego, co wprowadziłoby jakieś radykalne zmiany we współczesnych strategiach SEO.
Praktyczne wskazówki są wynikające z ujawnionych czynników rankingowych można podsumować w prostych zaleceniach:
„Zrozum swoich użytkowników, dowiedz się czego chcą, daj im to najlepiej jak potrafisz, zadbaj o to, żeby było to technicznie dostępne i promuj to do skutku, aż zacznie rankować”.
3. Google indeksuje pliki EPUB
Google zaczęło indeksować pliki EPUB (format plików e-booków). Dokumenty w tym formacie mogą teraz pojawiać się w wynikach wyszukiwania.
Na razie nie wiadomo, czy pliki te będą rankować w wynikach (czy będą oceniane tak jak strony). Na pewno będą jednak dostępne poprzez wyszukiwane z operatorem "filetype:" (już są).
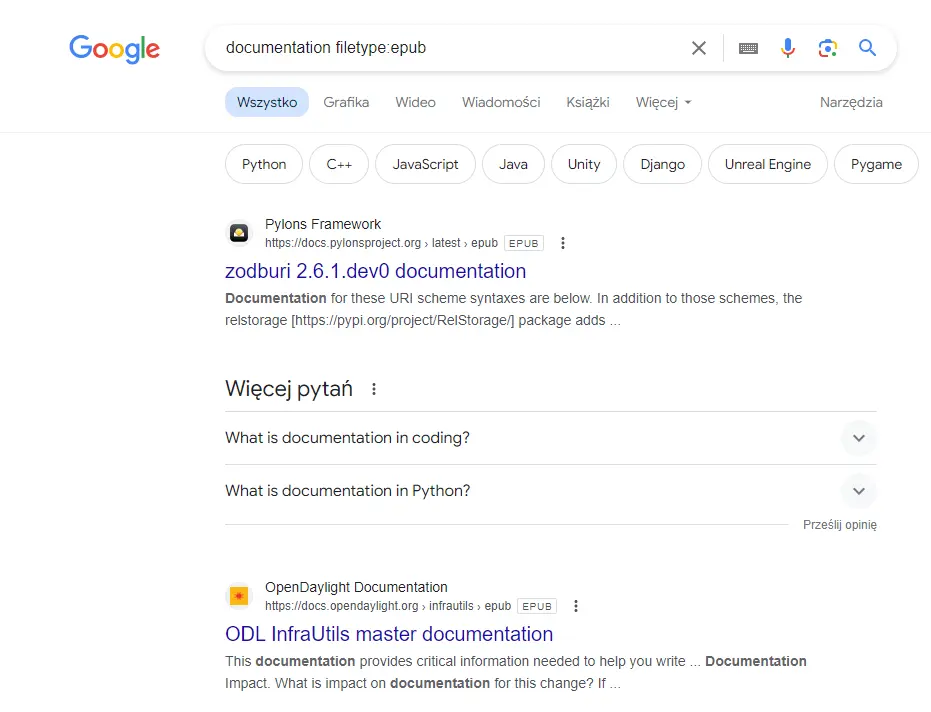
Co wynika z tej zmiany w praktyce? Przede wszystkim to, że jeśli masz na stronie jakieś e-booki w .epub, to warto teraz sprawdzić, czy na pewno mają one „noindex”, bo z tą zmianą mogły stać się dostępne z Google.
4. Profil recenzenta – łatwe zarządzanie swoimi opiniami w Google
Google stworzyło profil recenzenta – specjalny serwis, w którym każdy użytkownik Google może zarządzać swoimi opiniami „o filmach, książkach, grach wideo i albumach”.
Profil zbiera w jednym miejscu wszystkie opinie tego typu wystawione przez dane konto Google w jednym miejscu i tworzy coś w rodzaju odpowiednika profilu użytkownika na Filmwebie czy Lubimyczytać.
Podobno funkcja sama w sobie nie jest nowa (istnieje już od jakiegoś czasu), ale teraz Google rozszerza jej dostępność, wysyłając maile do osób, które zostawiły w wynikach jakieś oceny.
Wyświetlane w niej opinie, to z kolei opinie dodane w funkcjach mobilnych wyników na temat filmów, książek itd. U nas są na razie one niedostępne, ale możliwe, że niebawem się to zmieni.
5. Awaria wyszukiwarki Bing
23 maja 2024 roku wyszukiwarka Bing miała dużą awarię. Serwis zaczął mieć problemy około 7:30 naszego czasu, a wyszukiwarka nie działała lub ładowała się z gigantycznym opóźnieniem aż do 19:30, czyli przez jakieś 12 godzin (!).
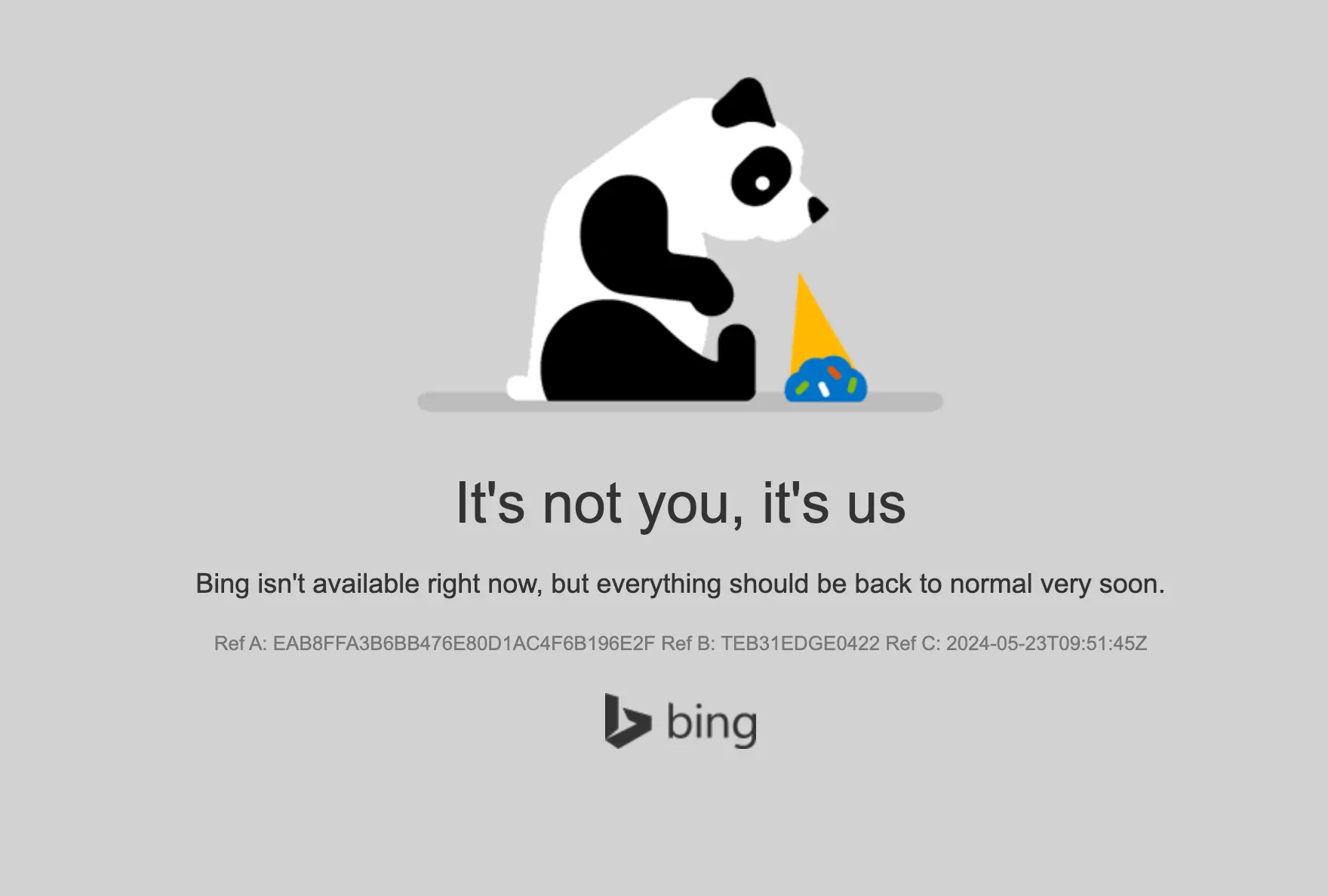
Co ciekawe, na czas tej awarii przestały działać też wszystkie wyszukiwarki będące partnerami Binga. Między innymi DuckDuckGo, Ecosia. Nie działało także wyszukiwanie w sieci w ChatGPT (korzysta ono z API Microsoftu).
6. Raport linków w GSC pokazuje mniej pozycji
Raport linków zewnętrznych w Search Console może pokazywać mniej linków. Tak przynajmniej wskazują liczne doniesienia SEO-wców.
Jeśli zauważysz więc spadki, to najprawdopodobniej nie są one realnym odzwierciedleniem utraconych odnośników.
Taka sytuacja miała miejsce już wcześniej, w lipcu 2023 (SEO News #93). Wtedy Google przyznało, że był to bug w raportowaniu danych (SEO News #94).
A jak jest tym razem? Znowu jest to bug, czy może tym razem raport faktycznie ignoruje część linków?
Na razie nie wiadomo, nikt z Google nie wypowiedział się w tej sprawie. Na pewno tym razem skala spadków jest znacznie mniejsza.
Autor artykułu
Adam Przybyłowicz
Product Lead i specjalista od researchu i rozwoju w Top Online. Zdobywa dla nas wiedzę, szuka nowych rozwiązań i pracuje nad tym, żebyśmy nie zostali w tyle. Prowadzi zespół tworzący m.in. YOSA.AI.


